 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMERLIN: Building Low-SNR Robust Multimodal LLMs for Electromagnetic Signals
Mar 09, 2026The paradigm of Multimodal Large Language Models (MLLMs) offers a promising blueprint for advancing the electromagnetic (EM) domain. However, prevailing approaches often deviate from the native MLLM paradigm, instead using task-specific or pipelined architectures that lead to fundamental limitations in model performance and generalization. Fully realizing the MLLM potential in EM domain requires overcoming three main challenges: (1) Data. The scarcity of high-quality datasets with paired EM signals and descriptive text annotations used for MLLMs pre-training; (2) Benchmark. The absence of comprehensive benchmarks to systematically evaluate and compare the performance of models on EM signal-to-text tasks; (3) Model. A critical fragility in low Signal-to-Noise Ratio (SNR) environments, where critical signal features can be obscured, leading to significant performance degradation. To address these challenges, we introduce a tripartite contribution to establish a foundation for MLLMs in the EM domain. First, to overcome data scarcity, we construct and release EM-100k, a large-scale dataset comprising over 100,000 EM signal-text pairs. Second, to enable rigorous and standardized evaluation, we propose EM-Bench, the most comprehensive benchmark featuring diverse downstream tasks spanning from perception to reasoning. Finally, to tackle the core modeling challenge, we present MERLIN, a novel training framework designed not only to align low-level signal representations with high-level semantic text, but also to explicitly enhance model robustness and performance in challenging low-SNR environments. Comprehensive experiments validate our method, showing that MERLIN is state-of-the-art in the EM-Bench and exhibits remarkable robustness in low-SNR settings.
EMind: A Foundation Model for Multi-task Electromagnetic Signals Understanding
Aug 26, 2025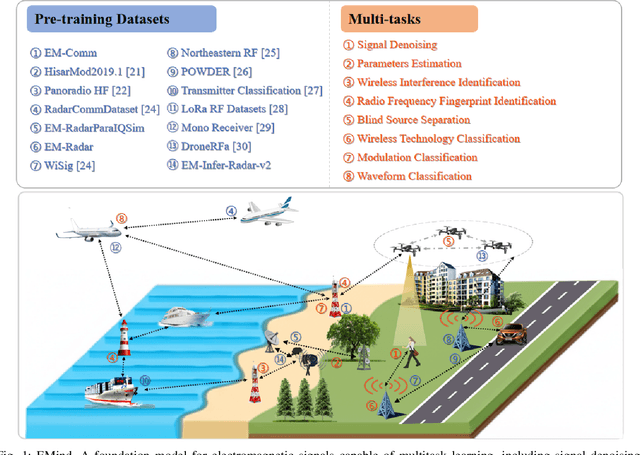
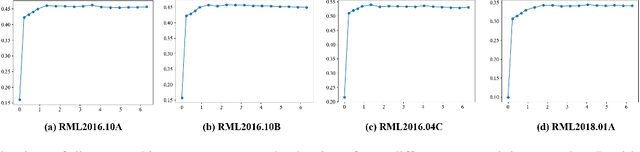
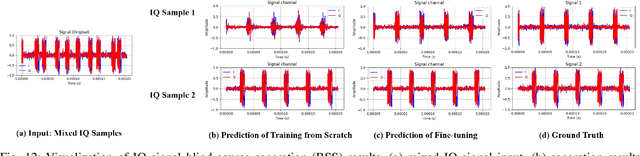
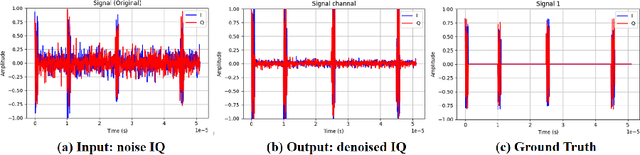
Deep understanding of electromagnetic signals is fundamental to dynamic spectrum management, intelligent transportation, autonomous driving and unmanned vehicle perception. The field faces challenges because electromagnetic signals differ greatly from text and images, showing high heterogeneity, strong background noise and complex joint time frequency structure, which prevents existing general models from direct use. Electromagnetic communication and sensing tasks are diverse, current methods lack cross task generalization and transfer efficiency, and the scarcity of large high quality datasets blocks the creation of a truly general multitask learning framework. To overcome these issue, we introduce EMind, an electromagnetic signals foundation model that bridges large scale pretraining and the unique nature of this modality. We build the first unified and largest standardized electromagnetic signal dataset covering multiple signal types and tasks. By exploiting the physical properties of electromagnetic signals, we devise a length adaptive multi-signal packing method and a hardware-aware training strategy that enable efficient use and representation learning from heterogeneous multi-source signals. Experiments show that EMind achieves strong performance and broad generalization across many downstream tasks, moving decisively from task specific models to a unified framework for electromagnetic intelligence. The code is available at: https://github.com/GabrielleTse/EMind.
PhysAug: A Physical-guided and Frequency-based Data Augmentation for Single-Domain Generalized Object Detection
Dec 16, 2024



Single-Domain Generalized Object Detection~(S-DGOD) aims to train on a single source domain for robust performance across a variety of unseen target domains by taking advantage of an object detector. Existing S-DGOD approaches often rely on data augmentation strategies, including a composition of visual transformations, to enhance the detector's generalization ability. However, the absence of real-world prior knowledge hinders data augmentation from contributing to the diversity of training data distributions. To address this issue, we propose PhysAug, a novel physical model-based non-ideal imaging condition data augmentation method, to enhance the adaptability of the S-DGOD tasks. Drawing upon the principles of atmospheric optics, we develop a universal perturbation model that serves as the foundation for our proposed PhysAug. Given that visual perturbations typically arise from the interaction of light with atmospheric particles, the image frequency spectrum is harnessed to simulate real-world variations during training. This approach fosters the detector to learn domain-invariant representations, thereby enhancing its ability to generalize across various settings. Without altering the network architecture or loss function, our approach significantly outperforms the state-of-the-art across various S-DGOD datasets. In particular, it achieves a substantial improvement of $7.3\%$ and $7.2\%$ over the baseline on DWD and Cityscape-C, highlighting its enhanced generalizability in real-world settings.
Object Gaussian for Monocular 6D Pose Estimation from Sparse Views
Sep 04, 2024



Monocular object pose estimation, as a pivotal task in computer vision and robotics, heavily depends on accurate 2D-3D correspondences, which often demand costly CAD models that may not be readily available. Object 3D reconstruction methods offer an alternative, among which recent advancements in 3D Gaussian Splatting (3DGS) afford a compelling potential. Yet its performance still suffers and tends to overfit with fewer input views. Embracing this challenge, we introduce SGPose, a novel framework for sparse view object pose estimation using Gaussian-based methods. Given as few as ten views, SGPose generates a geometric-aware representation by starting with a random cuboid initialization, eschewing reliance on Structure-from-Motion (SfM) pipeline-derived geometry as required by traditional 3DGS methods. SGPose removes the dependence on CAD models by regressing dense 2D-3D correspondences between images and the reconstructed model from sparse input and random initialization, while the geometric-consistent depth supervision and online synthetic view warping are key to the success. Experiments on typical benchmarks, especially on the Occlusion LM-O dataset, demonstrate that SGPose outperforms existing methods even under sparse view constraints, under-scoring its potential in real-world applications.
PU-EVA: An Edge Vector based Approximation Solution for Flexible-scale Point Cloud Upsampling
Apr 22, 2022


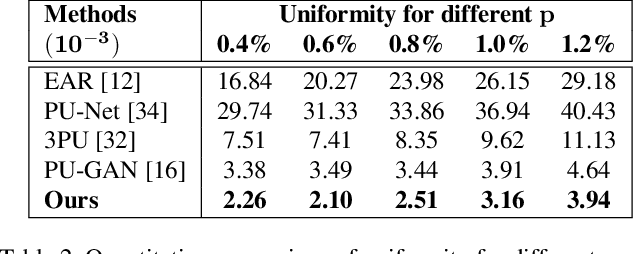
High-quality point clouds have practical significance for point-based rendering, semantic understanding, and surface reconstruction. Upsampling sparse, noisy and nonuniform point clouds for a denser and more regular approximation of target objects is a desirable but challenging task. Most existing methods duplicate point features for upsampling, constraining the upsampling scales at a fixed rate. In this work, the flexible upsampling rates are achieved via edge vector based affine combinations, and a novel design of Edge Vector based Approximation for Flexible-scale Point clouds Upsampling (PU-EVA) is proposed. The edge vector based approximation encodes the neighboring connectivity via affine combinations based on edge vectors, and restricts the approximation error within the second-order term of Taylor's Expansion. The EVA upsampling decouples the upsampling scales with network architecture, achieving the flexible upsampling rates in one-time training. Qualitative and quantitative evaluations demonstrate that the proposed PU-EVA outperforms the state-of-the-art in terms of proximity-to-surface, distribution uniformity, and geometric details preservation.