 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInclusive Design Insights from a Preliminary Image-Based Conversational Search Systems Evaluation
Mar 29, 2024



The digital realm has witnessed the rise of various search modalities, among which the Image-Based Conversational Search System stands out. This research delves into the design, implementation, and evaluation of this specific system, juxtaposing it against its text-based and mixed counterparts. A diverse participant cohort ensures a broad evaluation spectrum. Advanced tools facilitate emotion analysis, capturing user sentiments during interactions, while structured feedback sessions offer qualitative insights. Results indicate that while the text-based system minimizes user confusion, the image-based system presents challenges in direct information interpretation. However, the mixed system achieves the highest engagement, suggesting an optimal blend of visual and textual information. Notably, the potential of these systems, especially the image-based modality, to assist individuals with intellectual disabilities is highlighted. The study concludes that the Image-Based Conversational Search System, though challenging in some aspects, holds promise, especially when integrated into a mixed system, offering both clarity and engagement.
Temporal-Spatial Entropy Balancing for Causal Continuous Treatment-Effect Estimation
Dec 19, 2023In the field of intracity freight transportation, changes in order volume are significantly influenced by temporal and spatial factors. When building subsidy and pricing strategies, predicting the causal effects of these strategies on order volume is crucial. In the process of calculating causal effects, confounding variables can have an impact. Traditional methods to control confounding variables handle data from a holistic perspective, which cannot ensure the precision of causal effects in specific temporal and spatial dimensions. However, temporal and spatial dimensions are extremely critical in the logistics field, and this limitation may directly affect the precision of subsidy and pricing strategies. To address these issues, this study proposes a technique based on flexible temporal-spatial grid partitioning. Furthermore, based on the flexible grid partitioning technique, we further propose a continuous entropy balancing method in the temporal-spatial domain, which named TS-EBCT (Temporal-Spatial Entropy Balancing for Causal Continue Treatments). The method proposed in this paper has been tested on two simulation datasets and two real datasets, all of which have achieved excellent performance. In fact, after applying the TS-EBCT method to the intracity freight transportation field, the prediction accuracy of the causal effect has been significantly improved. It brings good business benefits to the company's subsidy and pricing strategies.
A Split-face Study of Novel Robotic Prototype vs Human Operator in Skin Rejuvenation Using Q-switched Nd:Yag Laser: Accuracy, Efficacy and Safety
Jun 05, 2021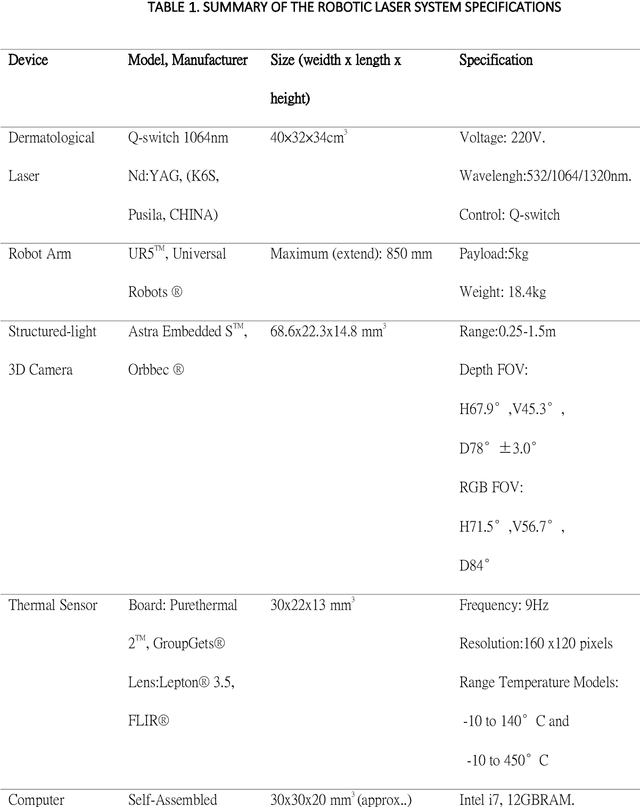
Background: Robotic technologies involved in skin laser are emerging. Objective: To compare the accuracy, efficacy and safety of novel robotic prototype with human operator in laser operation performance for skin photo-rejuvenation. Methods: Seventeen subjects were enrolled in a prospective, comparative split-face trial. Q-switch 1064nm laser conducted by the robotic prototype was provided on the right side of the face and that by the professional practitioner on the left. Each subject underwent a single time, one-pass, non-overlapped treatment on an equal size area of the forehead and cheek. Objective assessments included: treatment duration, laser irradiation shots, laser coverage percentage, VISIA parameters, skin temperature and the VAS pain scale. Results: Average time taken by robotic manipulator was longer than human operator; the average number of irradiation shots of both sides had no significant differences. Laser coverage rate of robotic manipulator (60.2 +-15.1%) was greater than that of human operator (43.6 +-12.9%). The VISIA parameters showed no significant differences between robotic manipulator and human operator. No short or long-term side effects were observed with maximum VAS score of 1 point. Limitations: Only one section of laser treatment was performed. Conclusion: Laser operation by novel robotic prototype is more reliable, stable and accurate than human operation.
Reinforcement Learning and Video Games
Sep 10, 2019

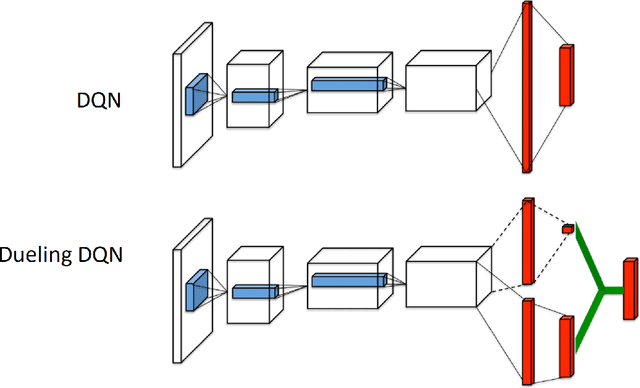
Reinforcement learning has exceeded human-level performance in game playing AI with deep learning methods according to the experiments from DeepMind on Go and Atari games. Deep learning solves high dimension input problems which stop the development of reinforcement for many years. This study uses both two techniques to create several agents with different algorithms that successfully learn to play T-rex Runner. Deep Q network algorithm and three types of improvements are implemented to train the agent. The results from some of them are far from satisfactory but others are better than human experts. Batch normalization is a method to solve internal covariate shift problems in deep neural network. The positive influence of this on reinforcement learning has also been proved in this study.
Intention Oriented Image Captions with Guiding Objects
Nov 19, 2018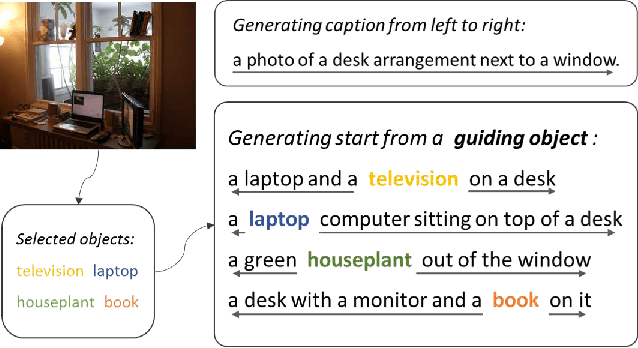
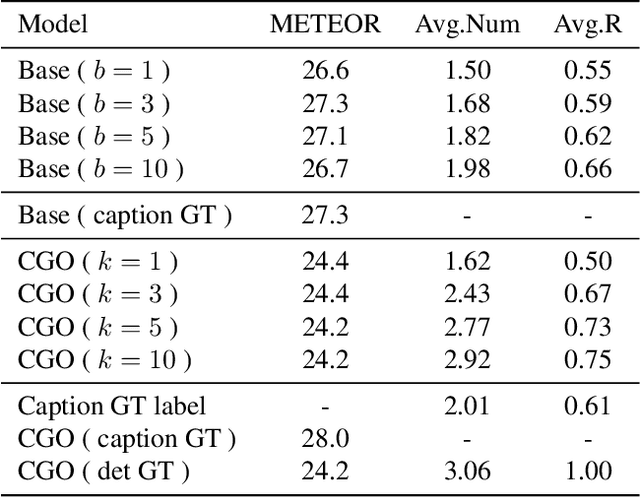
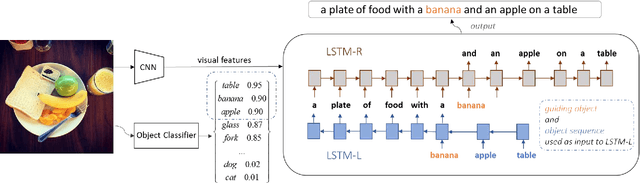
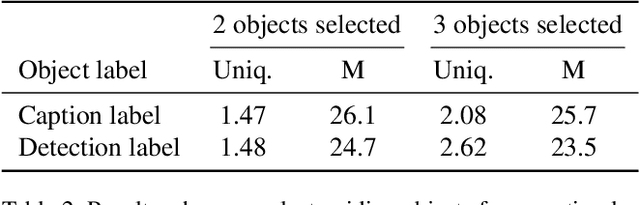
Although existing image caption models can produce promising results using recurrent neural networks (RNNs), it is difficult to guarantee that an object we care about is contained in generated descriptions, for example in the case that the object is inconspicuous in image. Problems become even harder when these objects did not appear in training stage. In this paper, we propose a novel approach for generating image captions with guiding objects (CGO). The CGO constrains the model to involve a human-concerned object, when the object is in the image, in the generated description while maintaining fluency. Instead of generating the sequence from left to right, we start description with a selected object and generate other parts of the sequence based on this object. To achieve this, we design a novel framework combining two LSTMs in opposite directions. We demonstrate the characteristics of our method on MSCOCO to generate descriptions for each detected object in images. With CGO, we can extend the ability of description to the objects being neglected in image caption labels and provide a set of more comprehensive and diverse descriptions for an image. CGO shows obvious advantages when applied to the task of describing novel objects. We show experiment results on both MSCOCO and ImageNet datasets. Evaluations show that our method outperforms the state-of-the-art models in the task with average F1 75.8, leading to better descriptions in terms of both content accuracy and fluency.