 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Graph Representation Learning with Large Language Models: A Comprehensive Survey of Techniques
Feb 04, 2024
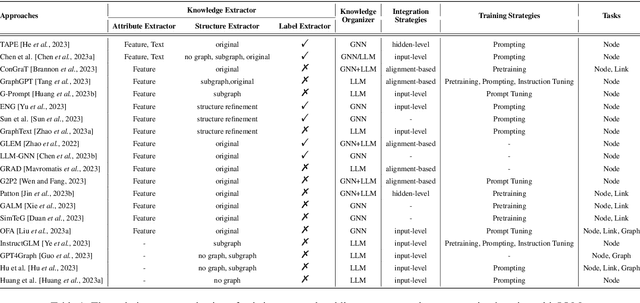
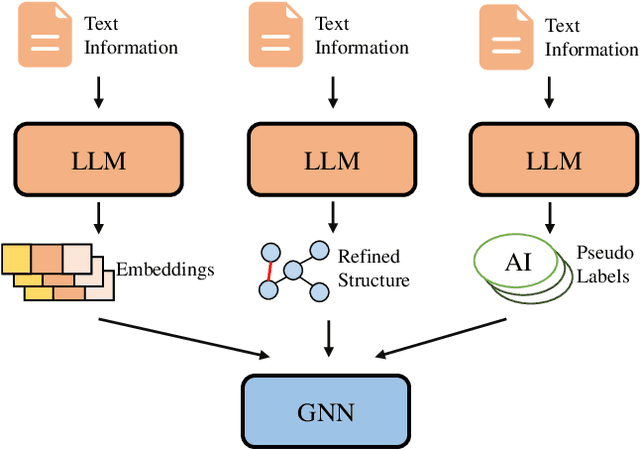
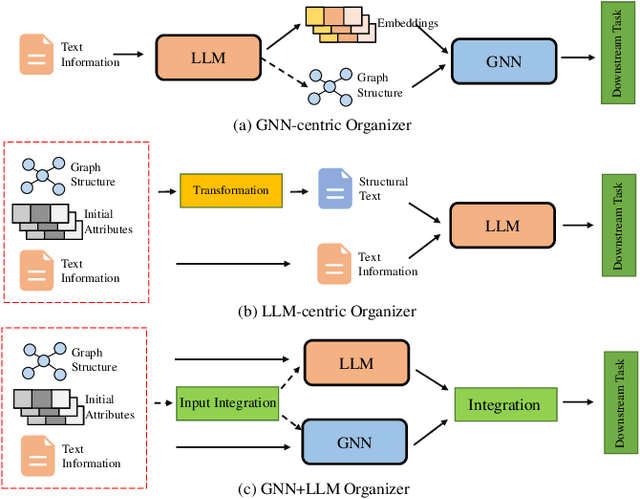
The integration of Large Language Models (LLMs) with Graph Representation Learning (GRL) marks a significant evolution in analyzing complex data structures. This collaboration harnesses the sophisticated linguistic capabilities of LLMs to improve the contextual understanding and adaptability of graph models, thereby broadening the scope and potential of GRL. Despite a growing body of research dedicated to integrating LLMs into the graph domain, a comprehensive review that deeply analyzes the core components and operations within these models is notably lacking. Our survey fills this gap by proposing a novel taxonomy that breaks down these models into primary components and operation techniques from a novel technical perspective. We further dissect recent literature into two primary components including knowledge extractors and organizers, and two operation techniques including integration and training stratigies, shedding light on effective model design and training strategies. Additionally, we identify and explore potential future research avenues in this nascent yet underexplored field, proposing paths for continued progress.
ULTRA-DP: Unifying Graph Pre-training with Multi-task Graph Dual Prompt
Oct 23, 2023
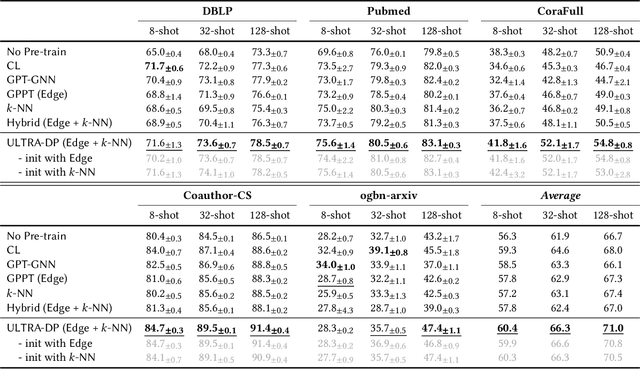
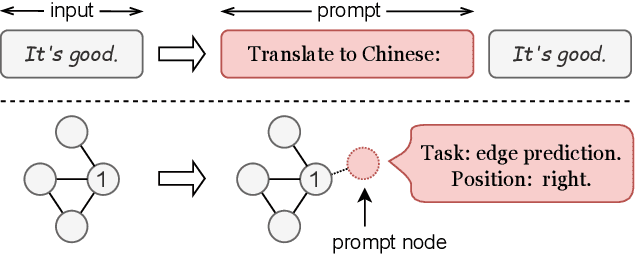
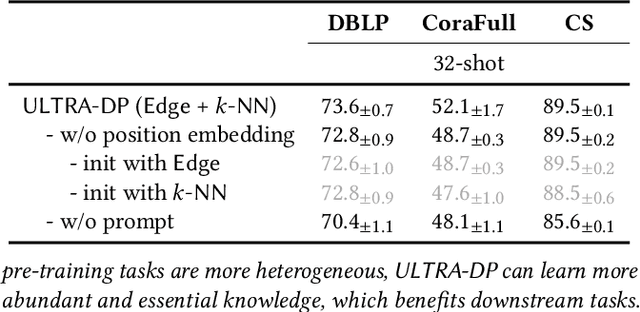
Recent research has demonstrated the efficacy of pre-training graph neural networks (GNNs) to capture the transferable graph semantics and enhance the performance of various downstream tasks. However, the semantic knowledge learned from pretext tasks might be unrelated to the downstream task, leading to a semantic gap that limits the application of graph pre-training. To reduce this gap, traditional approaches propose hybrid pre-training to combine various pretext tasks together in a multi-task learning fashion and learn multi-grained knowledge, which, however, cannot distinguish tasks and results in some transferable task-specific knowledge distortion by each other. Moreover, most GNNs cannot distinguish nodes located in different parts of the graph, making them fail to learn position-specific knowledge and lead to suboptimal performance. In this work, inspired by the prompt-based tuning in natural language processing, we propose a unified framework for graph hybrid pre-training which injects the task identification and position identification into GNNs through a prompt mechanism, namely multi-task graph dual prompt (ULTRA-DP). Based on this framework, we propose a prompt-based transferability test to find the most relevant pretext task in order to reduce the semantic gap. To implement the hybrid pre-training tasks, beyond the classical edge prediction task (node-node level), we further propose a novel pre-training paradigm based on a group of $k$-nearest neighbors (node-group level). The combination of them across different scales is able to comprehensively express more structural semantics and derive richer multi-grained knowledge. Extensive experiments show that our proposed ULTRA-DP can significantly enhance the performance of hybrid pre-training methods and show the generalizability to other pre-training tasks and backbone architectures.
HINormer: Representation Learning On Heterogeneous Information Networks with Graph Transformer
Mar 03, 2023



Recent studies have highlighted the limitations of message-passing based graph neural networks (GNNs), e.g., limited model expressiveness, over-smoothing, over-squashing, etc. To alleviate these issues, Graph Transformers (GTs) have been proposed which work in the paradigm that allows message passing to a larger coverage even across the whole graph. Hinging on the global range attention mechanism, GTs have shown a superpower for representation learning on homogeneous graphs. However, the investigation of GTs on heterogeneous information networks (HINs) is still under-exploited. In particular, on account of the existence of heterogeneity, HINs show distinct data characteristics and thus require different treatment. To bridge this gap, in this paper we investigate the representation learning on HINs with Graph Transformer, and propose a novel model named HINormer, which capitalizes on a larger-range aggregation mechanism for node representation learning. In particular, assisted by two major modules, i.e., a local structure encoder and a heterogeneous relation encoder, HINormer can capture both the structural and heterogeneous information of nodes on HINs for comprehensive node representations. We conduct extensive experiments on four HIN benchmark datasets, which demonstrate that our proposed model can outperform the state-of-the-art.