 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePretraining large language models with MXFP4
May 11, 2026Why does full-pipeline FP4 training of large language models often diverge, even when forward activations and activation gradients remain stable? We address this question through a controlled study of MXFP4 quantization in transformer training, progressively enabling FP4 across forward propagation (Fprop), activation gradients (Dgrad), and weight gradients (Wgrad) while holding all other factors fixed. In full pretraining of Llama 3.1-8B on the C4 dataset, we observe that quantizing Wgrad is the primary driver of convergence degradation, whereas FP4 in Fprop and Dgrad alone introduces only modest additional token requirements. To interpret this behavior, we evaluate both structured and stochastic interventions under a controlled experimental setting. We find that stochastic rounding and randomized Hadamard rotations fail to stabilize training once Wgrad is quantized, whereas deterministic Hadamard rotations consistently restore stable optimization. These results suggest that FP4 training instability is driven by structured micro-scaling errors along sensitive gradient paths, rather than by insufficient stochasticity. We run experiments with native MXFP4 support on AMD Instinct MI355X GPUs, enabling controlled investigation of these effects without reliance on software emulation.
PIFS-Rec: Process-In-Fabric-Switch for Large-Scale Recommendation System Inferences
Sep 25, 2024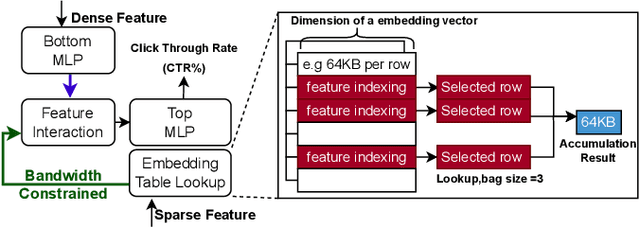
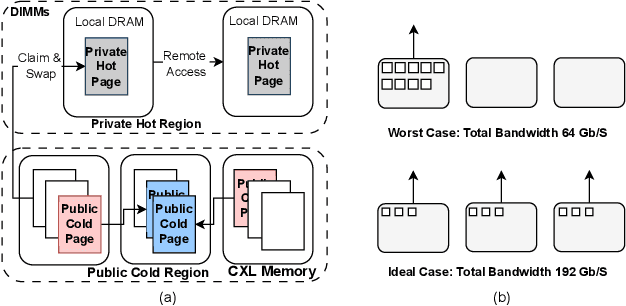
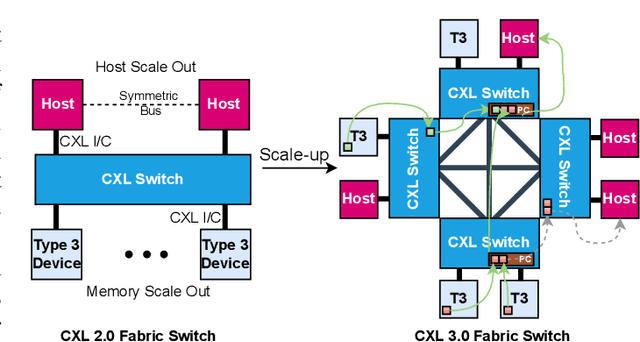

Deep Learning Recommendation Models (DLRMs) have become increasingly popular and prevalent in today's datacenters, consuming most of the AI inference cycles. The performance of DLRMs is heavily influenced by available bandwidth due to their large vector sizes in embedding tables and concurrent accesses. To achieve substantial improvements over existing solutions, novel approaches towards DLRM optimization are needed, especially, in the context of emerging interconnect technologies like CXL. This study delves into exploring CXL-enabled systems, implementing a process-in-fabric-switch (PIFS) solution to accelerate DLRMs while optimizing their memory and bandwidth scalability. We present an in-depth characterization of industry-scale DLRM workloads running on CXL-ready systems, identifying the predominant bottlenecks in existing CXL systems. We, therefore, propose PIFS-Rec, a PIFS-based scheme that implements near-data processing through downstream ports of the fabric switch. PIFS-Rec achieves a latency that is 3.89x lower than Pond, an industry-standard CXL-based system, and also outperforms BEACON, a state-of-the-art scheme, by 2.03x.
Early prediction of onset of sepsis in Clinical Setting
Feb 05, 2024This study proposes the use of Machine Learning models to predict the early onset of sepsis using deidentified clinical data from Montefiore Medical Center in Bronx, NY, USA. A supervised learning approach was adopted, wherein an XGBoost model was trained utilizing 80\% of the train dataset, encompassing 107 features (including the original and derived features). Subsequently, the model was evaluated on the remaining 20\% of the test data. The model was validated on prospective data that was entirely unseen during the training phase. To assess the model's performance at the individual patient level and timeliness of the prediction, a normalized utility score was employed, a widely recognized scoring methodology for sepsis detection, as outlined in the PhysioNet Sepsis Challenge paper. Metrics such as F1 Score, Sensitivity, Specificity, and Flag Rate were also devised. The model achieved a normalized utility score of 0.494 on test data and 0.378 on prospective data at threshold 0.3. The F1 scores were 80.8\% and 67.1\% respectively for the test data and the prospective data for the same threshold, highlighting its potential to be integrated into clinical decision-making processes effectively. These results bear testament to the model's robust predictive capabilities and its potential to substantially impact clinical decision-making processes.
Strategies for Optimizing End-to-End Artificial Intelligence Pipelines on Intel Xeon Processors
Nov 01, 2022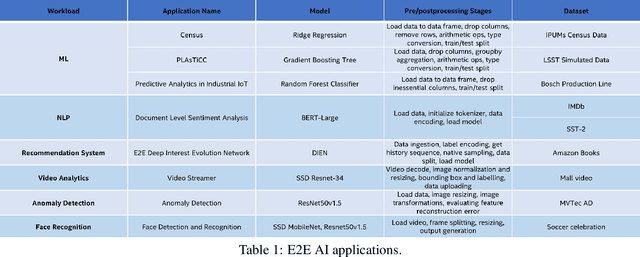
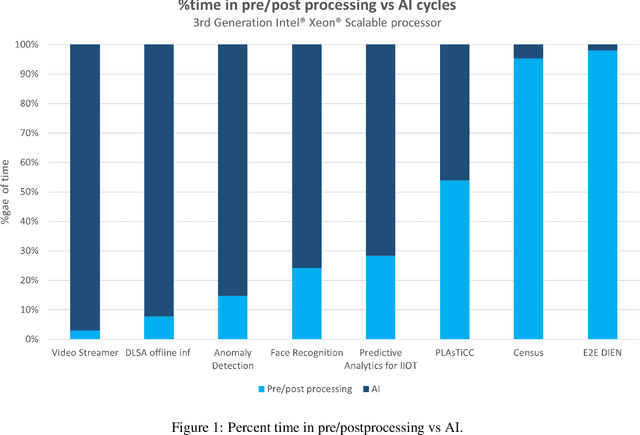
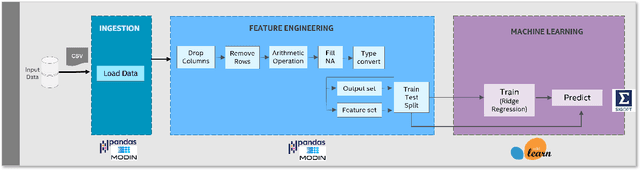
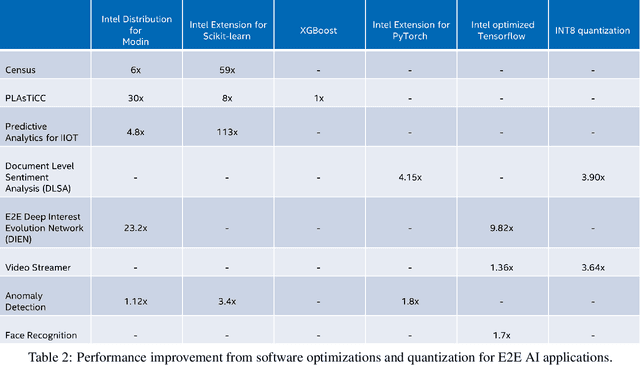
End-to-end (E2E) artificial intelligence (AI) pipelines are composed of several stages including data preprocessing, data ingestion, defining and training the model, hyperparameter optimization, deployment, inference, postprocessing, followed by downstream analyses. To obtain efficient E2E workflow, it is required to optimize almost all the stages of pipeline. Intel Xeon processors come with large memory capacities, bundled with AI acceleration (e.g., Intel Deep Learning Boost), well suited to run multiple instances of training and inference pipelines in parallel and has low total cost of ownership (TCO). To showcase the performance on Xeon processors, we applied comprehensive optimization strategies coupled with software and hardware acceleration on variety of E2E pipelines in the areas of Computer Vision, NLP, Recommendation systems, etc. We were able to achieve a performance improvement, ranging from 1.8x to 81.7x across different E2E pipelines. In this paper, we will be highlighting the optimization strategies adopted by us to achieve this performance on Intel Xeon processors with a set of eight different E2E pipelines.
* 10 pages, 11 figures, 3 tables