 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly prediction of onset of sepsis in Clinical Setting
Feb 05, 2024This study proposes the use of Machine Learning models to predict the early onset of sepsis using deidentified clinical data from Montefiore Medical Center in Bronx, NY, USA. A supervised learning approach was adopted, wherein an XGBoost model was trained utilizing 80\% of the train dataset, encompassing 107 features (including the original and derived features). Subsequently, the model was evaluated on the remaining 20\% of the test data. The model was validated on prospective data that was entirely unseen during the training phase. To assess the model's performance at the individual patient level and timeliness of the prediction, a normalized utility score was employed, a widely recognized scoring methodology for sepsis detection, as outlined in the PhysioNet Sepsis Challenge paper. Metrics such as F1 Score, Sensitivity, Specificity, and Flag Rate were also devised. The model achieved a normalized utility score of 0.494 on test data and 0.378 on prospective data at threshold 0.3. The F1 scores were 80.8\% and 67.1\% respectively for the test data and the prospective data for the same threshold, highlighting its potential to be integrated into clinical decision-making processes effectively. These results bear testament to the model's robust predictive capabilities and its potential to substantially impact clinical decision-making processes.
Distributed Transfer Learning with 4th Gen Intel Xeon Processors
Oct 10, 2023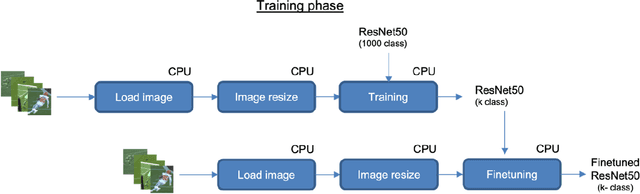
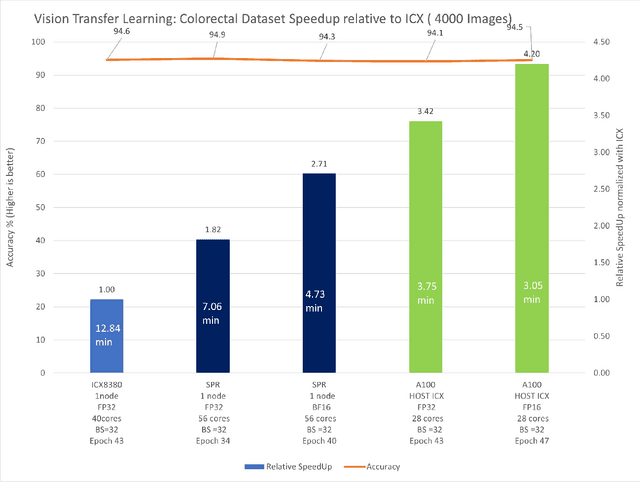
In this paper, we explore how transfer learning, coupled with Intel Xeon, specifically 4th Gen Intel Xeon scalable processor, defies the conventional belief that training is primarily GPU-dependent. We present a case study where we achieved near state-of-the-art accuracy for image classification on a publicly available Image Classification TensorFlow dataset using Intel Advanced Matrix Extensions(AMX) and distributed training with Horovod.
Strategies for Optimizing End-to-End Artificial Intelligence Pipelines on Intel Xeon Processors
Nov 01, 2022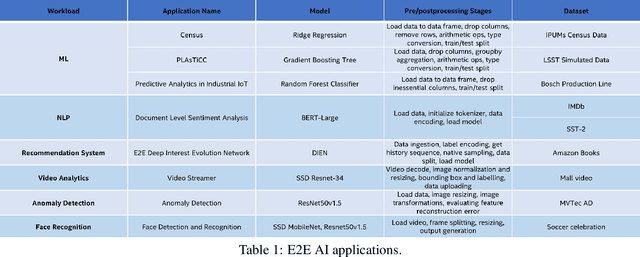
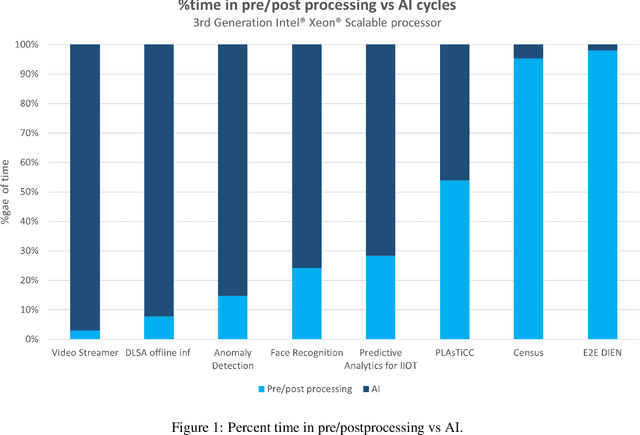
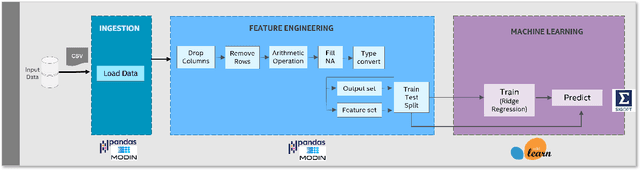
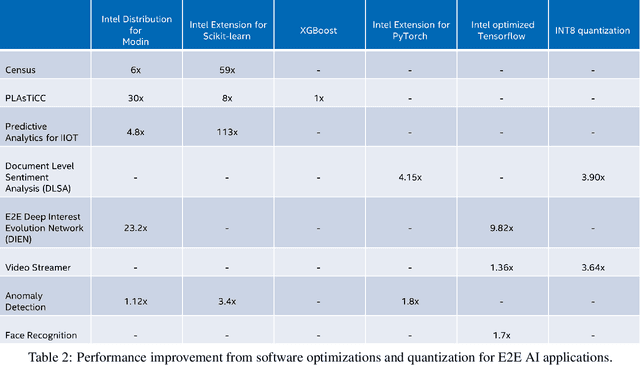
End-to-end (E2E) artificial intelligence (AI) pipelines are composed of several stages including data preprocessing, data ingestion, defining and training the model, hyperparameter optimization, deployment, inference, postprocessing, followed by downstream analyses. To obtain efficient E2E workflow, it is required to optimize almost all the stages of pipeline. Intel Xeon processors come with large memory capacities, bundled with AI acceleration (e.g., Intel Deep Learning Boost), well suited to run multiple instances of training and inference pipelines in parallel and has low total cost of ownership (TCO). To showcase the performance on Xeon processors, we applied comprehensive optimization strategies coupled with software and hardware acceleration on variety of E2E pipelines in the areas of Computer Vision, NLP, Recommendation systems, etc. We were able to achieve a performance improvement, ranging from 1.8x to 81.7x across different E2E pipelines. In this paper, we will be highlighting the optimization strategies adopted by us to achieve this performance on Intel Xeon processors with a set of eight different E2E pipelines.
* 10 pages, 11 figures, 3 tables
Is preprocessing of text really worth your time for online comment classification?
Aug 29, 2018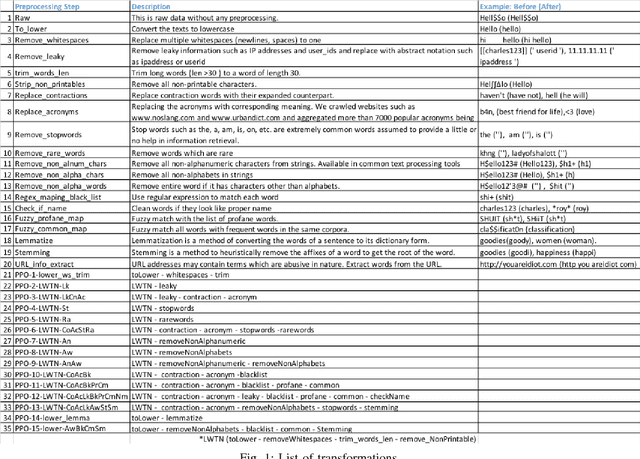
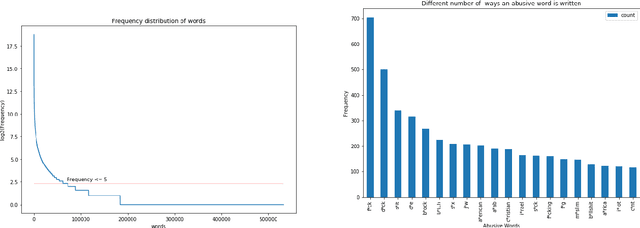
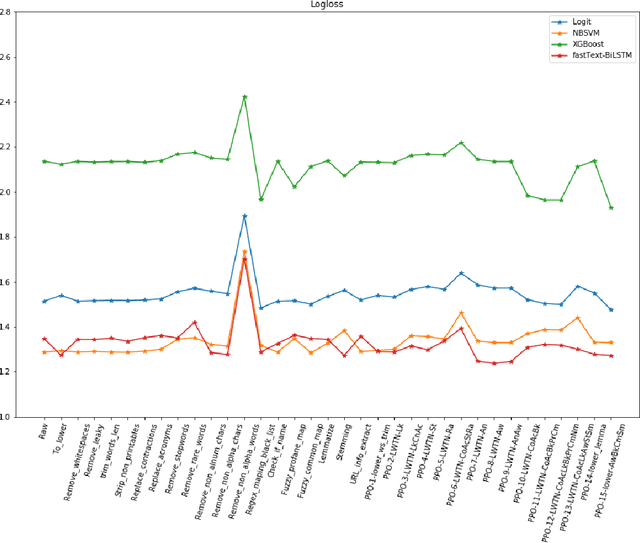
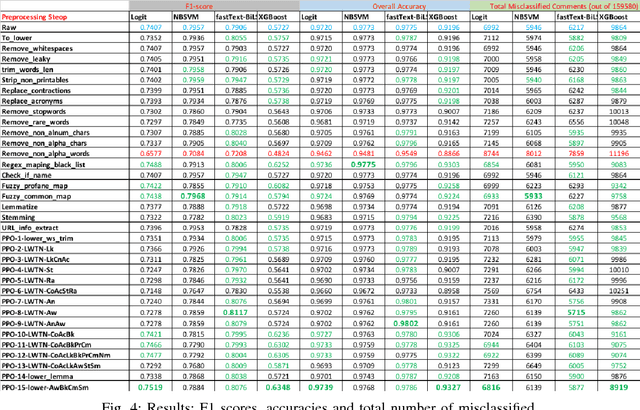
A large proportion of online comments present on public domains are constructive, however a significant proportion are toxic in nature. The comments contain lot of typos which increases the number of features manifold, making the ML model difficult to train. Considering the fact that the data scientists spend approximately 80% of their time in collecting, cleaning and organizing their data [1], we explored how much effort should we invest in the preprocessing (transformation) of raw comments before feeding it to the state-of-the-art classification models. With the help of four models on Jigsaw toxic comment classification data, we demonstrated that the training of model without any transformation produce relatively decent model. Applying even basic transformations, in some cases, lead to worse performance and should be applied with caution.