 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Activation based Gradient Output Sparsity to Accelerate Backpropagation in CNNs
Sep 16, 2021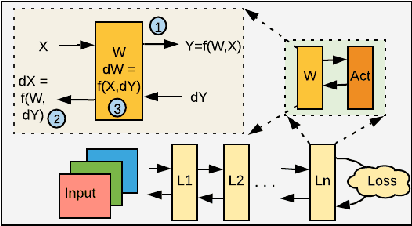
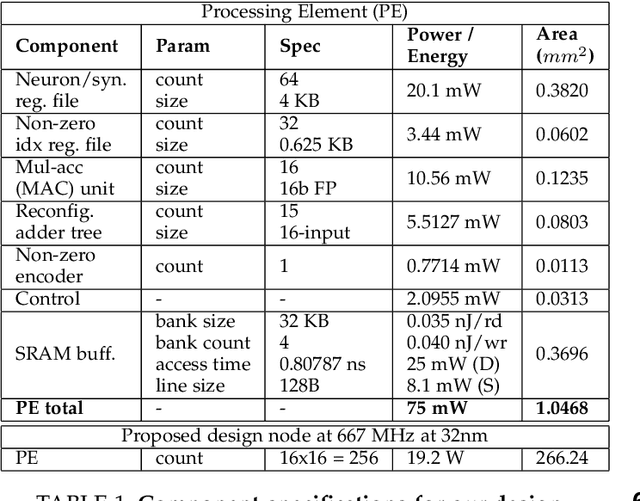
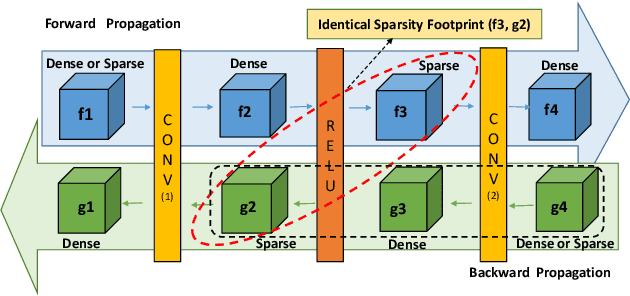
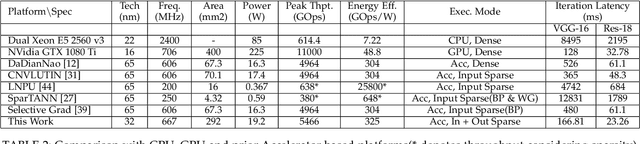
Machine/deep-learning (ML/DL) based techniques are emerging as a driving force behind many cutting-edge technologies, achieving high accuracy on computer vision workloads such as image classification and object detection. However, training these models involving large parameters is both time-consuming and energy-hogging. In this regard, several prior works have advocated for sparsity to speed up the of DL training and more so, the inference phase. This work begins with the observation that during training, sparsity in the forward and backward passes are correlated. In that context, we investigate two types of sparsity (input and output type) inherent in gradient descent-based optimization algorithms and propose a hardware micro-architecture to leverage the same. Our experimental results use five state-of-the-art CNN models on the Imagenet dataset, and show back propagation speedups in the range of 1.69$\times$ to 5.43$\times$, compared to the dense baseline execution. By exploiting sparsity in both the forward and backward passes, speedup improvements range from 1.68$\times$ to 3.30$\times$ over the sparsity-agnostic baseline execution. Our work also achieves significant reduction in training iteration time over several previously proposed dense as well as sparse accelerator based platforms, in addition to achieving order of magnitude energy efficiency improvements over GPU based execution.
Structured in Space, Randomized in Time: Leveraging Dropout in RNNs for Efficient Training
Jun 22, 2021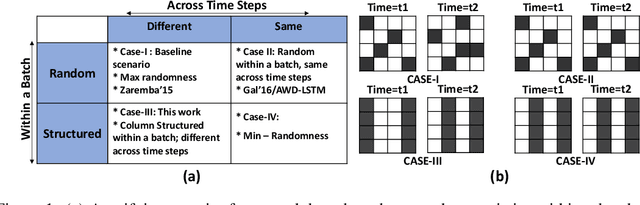
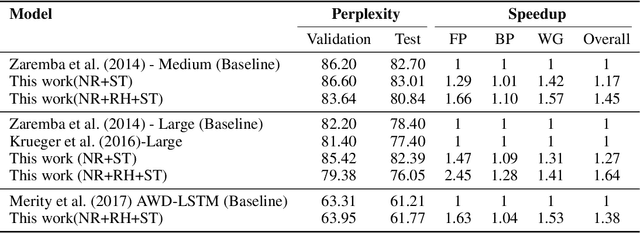
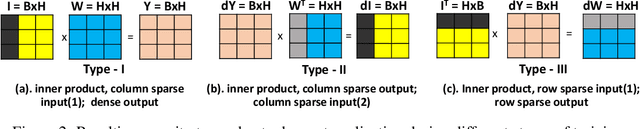
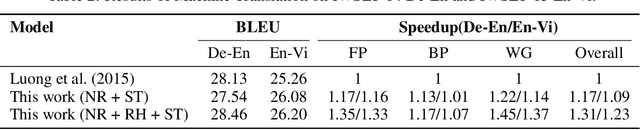
Recurrent Neural Networks (RNNs), more specifically their Long Short-Term Memory (LSTM) variants, have been widely used as a deep learning tool for tackling sequence-based learning tasks in text and speech. Training of such LSTM applications is computationally intensive due to the recurrent nature of hidden state computation that repeats for each time step. While sparsity in Deep Neural Nets has been widely seen as an opportunity for reducing computation time in both training and inference phases, the usage of non-ReLU activation in LSTM RNNs renders the opportunities for such dynamic sparsity associated with neuron activation and gradient values to be limited or non-existent. In this work, we identify dropout induced sparsity for LSTMs as a suitable mode of computation reduction. Dropout is a widely used regularization mechanism, which randomly drops computed neuron values during each iteration of training. We propose to structure dropout patterns, by dropping out the same set of physical neurons within a batch, resulting in column (row) level hidden state sparsity, which are well amenable to computation reduction at run-time in general-purpose SIMD hardware as well as systolic arrays. We conduct our experiments for three representative NLP tasks: language modelling on the PTB dataset, OpenNMT based machine translation using the IWSLT De-En and En-Vi datasets, and named entity recognition sequence labelling using the CoNLL-2003 shared task. We demonstrate that our proposed approach can be used to translate dropout-based computation reduction into reduced training time, with improvement ranging from 1.23x to 1.64x, without sacrificing the target metric.