 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Activation based Gradient Output Sparsity to Accelerate Backpropagation in CNNs
Paper and Code
Sep 16, 2021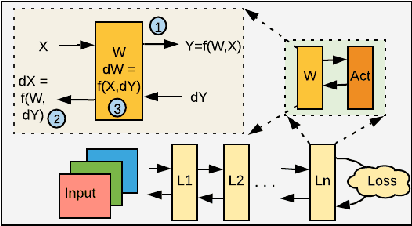
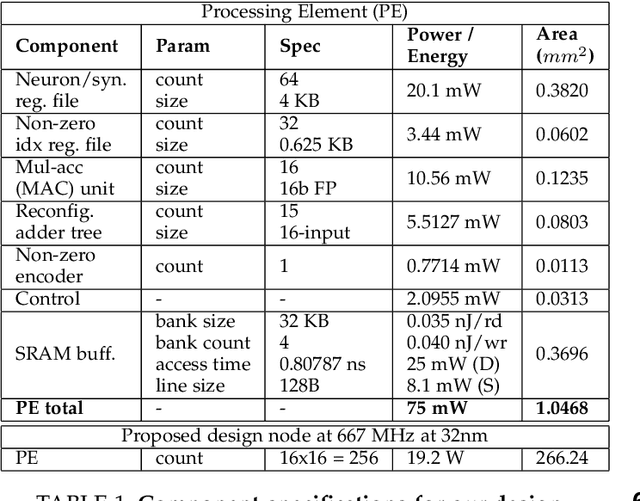
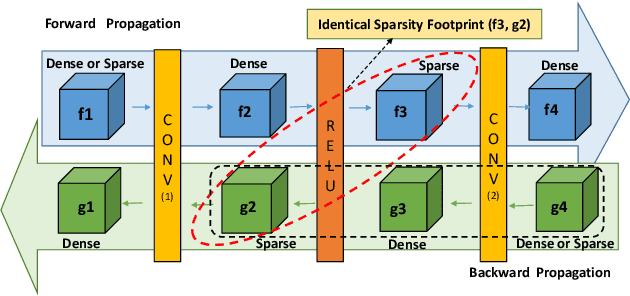
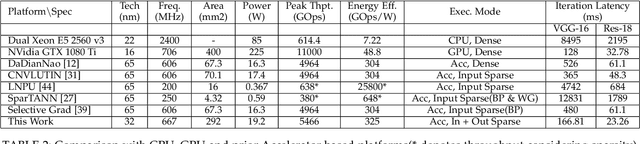
Machine/deep-learning (ML/DL) based techniques are emerging as a driving force behind many cutting-edge technologies, achieving high accuracy on computer vision workloads such as image classification and object detection. However, training these models involving large parameters is both time-consuming and energy-hogging. In this regard, several prior works have advocated for sparsity to speed up the of DL training and more so, the inference phase. This work begins with the observation that during training, sparsity in the forward and backward passes are correlated. In that context, we investigate two types of sparsity (input and output type) inherent in gradient descent-based optimization algorithms and propose a hardware micro-architecture to leverage the same. Our experimental results use five state-of-the-art CNN models on the Imagenet dataset, and show back propagation speedups in the range of 1.69$\times$ to 5.43$\times$, compared to the dense baseline execution. By exploiting sparsity in both the forward and backward passes, speedup improvements range from 1.68$\times$ to 3.30$\times$ over the sparsity-agnostic baseline execution. Our work also achieves significant reduction in training iteration time over several previously proposed dense as well as sparse accelerator based platforms, in addition to achieving order of magnitude energy efficiency improvements over GPU based execution.