 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-based Machine Learning for Fast SAT Solvers and Logic Synthesis
Jul 15, 2021



CNF-based SAT and MaxSAT solvers are central to logic synthesis and verification systems. The increasing popularity of these constraint problems in electronic design automation encourages studies on different SAT problems and their properties for further computational efficiency. There has been both theoretical and practical success of modern Conflict-driven clause learning SAT solvers, which allows solving very large industrial instances in a relatively short amount of time. Recently, machine learning approaches provide a new dimension to solving this challenging problem. Neural symbolic models could serve as generic solvers that can be specialized for specific domains based on data without any changes to the structure of the model. In this work, we propose a one-shot model derived from the Transformer architecture to solve the MaxSAT problem, which is the optimization version of SAT where the goal is to satisfy the maximum number of clauses. Our model has a scale-free structure which could process varying size of instances. We use meta-path and self-attention mechanism to capture interactions among homogeneous nodes. We adopt cross-attention mechanisms on the bipartite graph to capture interactions among heterogeneous nodes. We further apply an iterative algorithm to our model to satisfy additional clauses, enabling a solution approaching that of an exact-SAT problem. The attention mechanisms leverage the parallelism for speedup. Our evaluation indicates improved speedup compared to heuristic approaches and improved completion rate compared to machine learning approaches.
STAR: Sparse Transformer-based Action Recognition
Jul 15, 2021
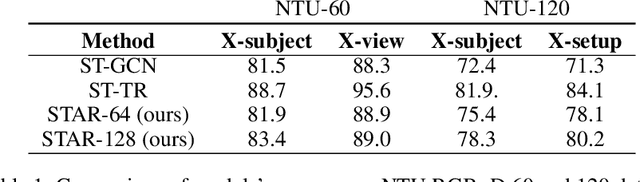

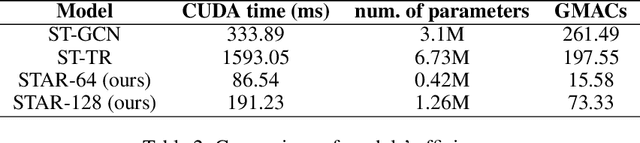
The cognitive system for human action and behavior has evolved into a deep learning regime, and especially the advent of Graph Convolution Networks has transformed the field in recent years. However, previous works have mainly focused on over-parameterized and complex models based on dense graph convolution networks, resulting in low efficiency in training and inference. Meanwhile, the Transformer architecture-based model has not yet been well explored for cognitive application in human action and behavior estimation. This work proposes a novel skeleton-based human action recognition model with sparse attention on the spatial dimension and segmented linear attention on the temporal dimension of data. Our model can also process the variable length of video clips grouped as a single batch. Experiments show that our model can achieve comparable performance while utilizing much less trainable parameters and achieve high speed in training and inference. Experiments show that our model achieves 4~18x speedup and 1/7~1/15 model size compared with the baseline models at competitive accuracy.