 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAR: Sparse Transformer-based Action Recognition
Paper and Code
Jul 15, 2021
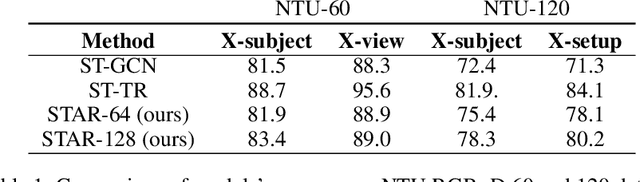

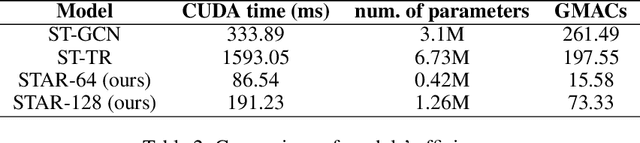
The cognitive system for human action and behavior has evolved into a deep learning regime, and especially the advent of Graph Convolution Networks has transformed the field in recent years. However, previous works have mainly focused on over-parameterized and complex models based on dense graph convolution networks, resulting in low efficiency in training and inference. Meanwhile, the Transformer architecture-based model has not yet been well explored for cognitive application in human action and behavior estimation. This work proposes a novel skeleton-based human action recognition model with sparse attention on the spatial dimension and segmented linear attention on the temporal dimension of data. Our model can also process the variable length of video clips grouped as a single batch. Experiments show that our model can achieve comparable performance while utilizing much less trainable parameters and achieve high speed in training and inference. Experiments show that our model achieves 4~18x speedup and 1/7~1/15 model size compared with the baseline models at competitive accuracy.