 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-view Gait Recognition based on Siamese Vision Transformer
Oct 19, 2022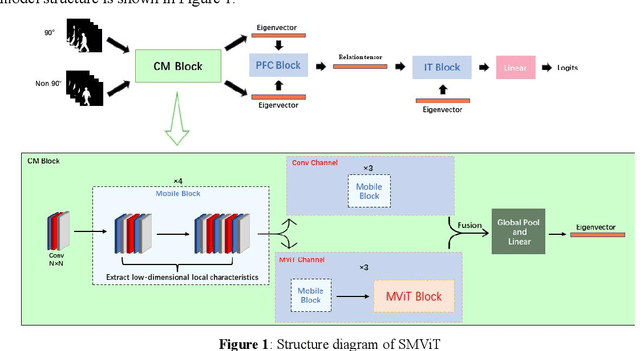
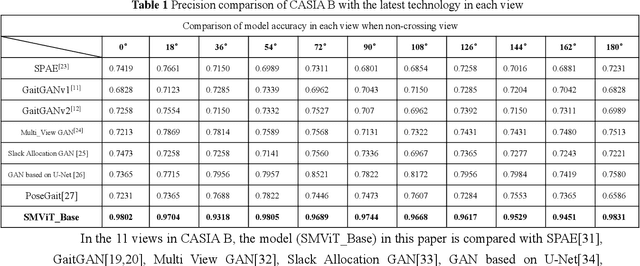
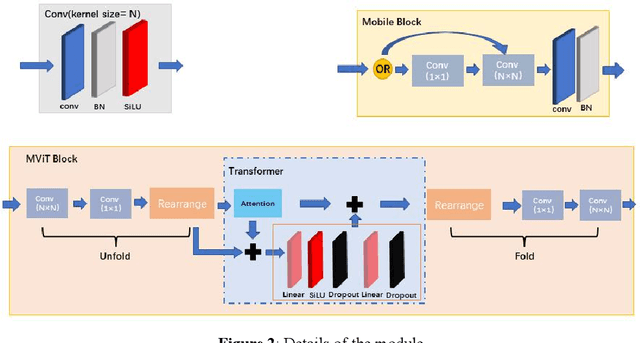

While the Vision Transformer has been used in gait recognition, its application in multi-view gait recognition is still limited. Different views significantly affect the extraction and identification accuracy of the characteristics of gait contour. To address this, this paper proposes a Siamese Mobile Vision Transformer (SMViT). This model not only focuses on the local characteristics of the human gait space but also considers the characteristics of long-distance attention associations, which can extract multi-dimensional step status characteristics. In addition, it describes how different perspectives affect gait characteristics and generate reliable perspective feature relationship factors. The average recognition rate of SMViT on the CASIA B data set reached 96.4%. The experimental results show that SMViT can attain state-of-the-art performance compared to advanced step recognition models such as GaitGAN, Multi_view GAN, Posegait and other gait recognition models.