 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect Judgement Preference Optimization
Paper and Code
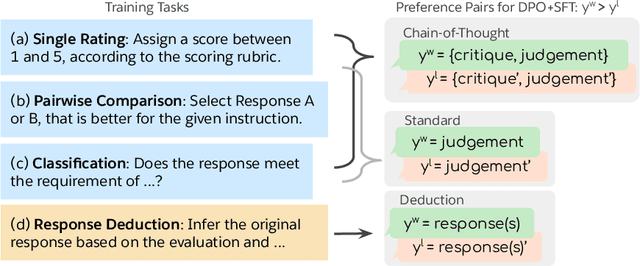

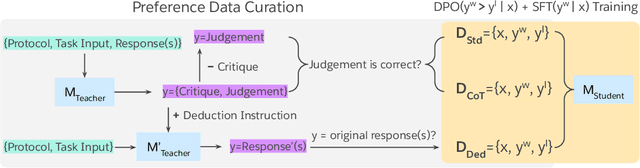

Auto-evaluation is crucial for assessing response quality and offering feedback for model development. Recent studies have explored training large language models (LLMs) as generative judges to evaluate and critique other models' outputs. In this work, we investigate the idea of learning from both positive and negative data with preference optimization to enhance the evaluation capabilities of LLM judges across an array of different use cases. We achieve this by employing three approaches to collect the preference pairs for different use cases, each aimed at improving our generative judge from a different perspective. Our comprehensive study over a wide range of benchmarks demonstrates the effectiveness of our method. In particular, our generative judge achieves the best performance on 10 out of 13 benchmarks, outperforming strong baselines like GPT-4o and specialized judge models. Further analysis show that our judge model robustly counters inherent biases such as position and length bias, flexibly adapts to any evaluation protocol specified by practitioners, and provides helpful language feedback for improving downstream generator models.