 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCHAMP: A Competition-level Dataset for Fine-Grained Analyses of LLMs' Mathematical Reasoning Capabilities
Paper and Code
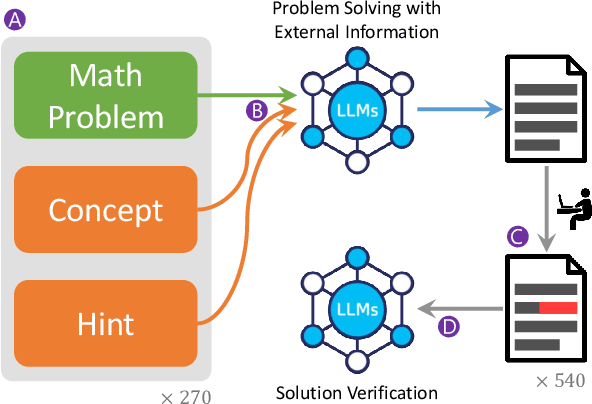


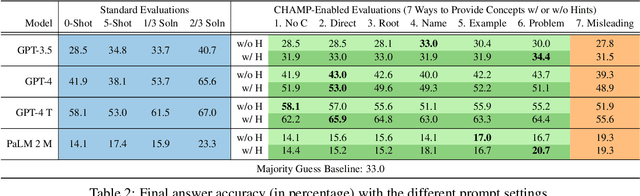
Recent large language models (LLMs) have shown indications of mathematical reasoning ability. However it has not been clear how they would fare on more challenging competition-level problems. And while self-generated verbalizations of intermediate reasoning steps (i.e., chain-of-thought prompting) have been shown to be helpful, whether LLMs can make use of helpful side information such as problem-specific hints has not been investigated before. In this paper, we propose a challenging benchmark dataset for enabling such analyses. The Concept and Hint-Annotated Math Problems (CHAMP) consists of high school math competition problems, annotated with concepts, or general math facts, and hints, or problem-specific tricks. These annotations allow us to explore the effects of additional information, such as relevant hints, misleading concepts, or related problems. This benchmark is difficult, with the best model only scoring 58.1% in standard settings. With concepts and hints, performance sometimes improves, indicating that some models can make use of such side information. We further annotate model-generated solutions for their correctness. Using this corpus, we find that models often arrive at the correct final answer through wrong reasoning steps. In addition, we test whether models are able to verify these solutions, and find that most models struggle. The dataset and code are available on the project website.