 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWIDIn: Wording Image for Domain-Invariant Representation in Single-Source Domain Generalization
Paper and Code
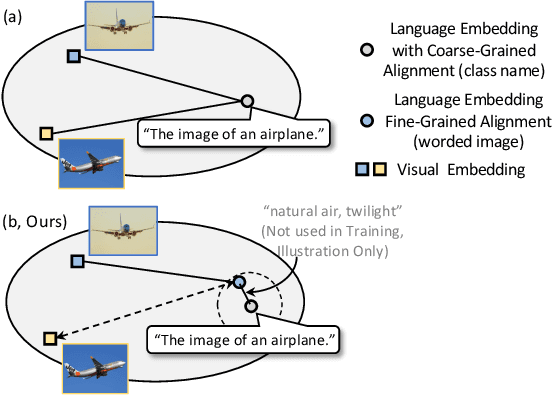
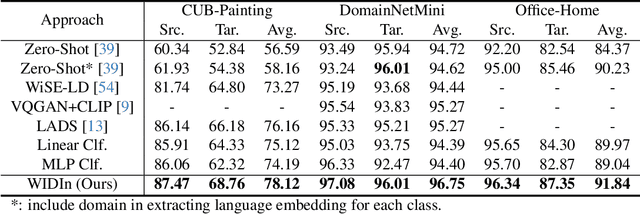
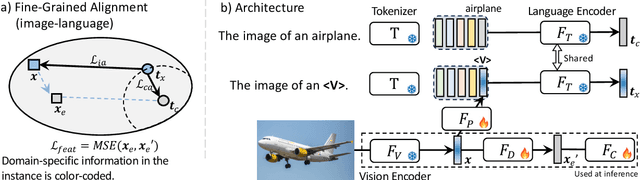
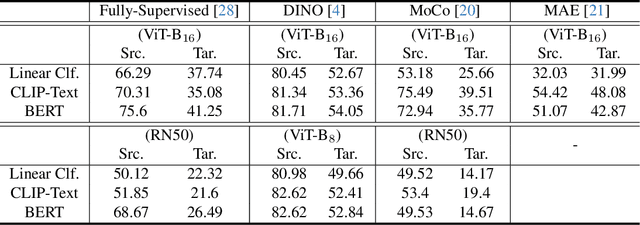
Language has been useful in extending the vision encoder to data from diverse distributions without empirical discovery in training domains. However, as the image description is mostly at coarse-grained level and ignores visual details, the resulted embeddings are still ineffective in overcoming complexity of domains at inference time. We present a self-supervision framework WIDIn, Wording Images for Domain-Invariant representation, to disentangle discriminative visual representation, by only leveraging data in a single domain and without any test prior. Specifically, for each image, we first estimate the language embedding with fine-grained alignment, which can be consequently used to adaptively identify and then remove domain-specific counterpart from the raw visual embedding. WIDIn can be applied to both pretrained vision-language models like CLIP, and separately trained uni-modal models like MoCo and BERT. Experimental studies on three domain generalization datasets demonstrate the effectiveness of our approach.