 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Few-Shot Object Detection with Meta-Learning Based Cross-Modal Prompting
Paper and Code
Apr 16, 2022
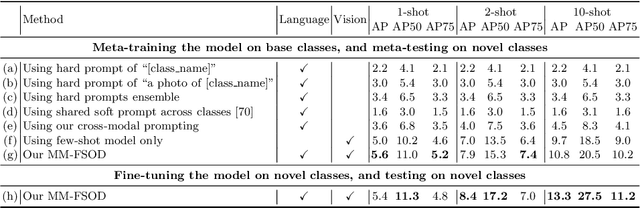
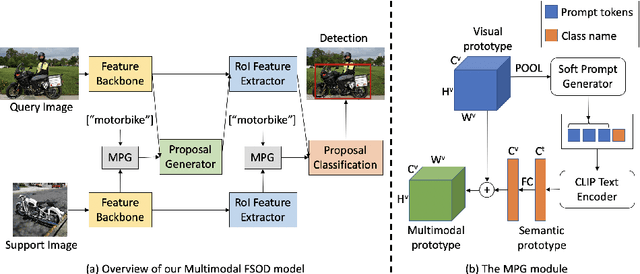
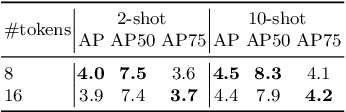
We study multimodal few-shot object detection (FSOD) in this paper, using both few-shot visual examples and class semantic information for detection. Most of previous works focus on either few-shot or zero-shot object detection, ignoring the complementarity of visual and semantic information. We first show that meta-learning and prompt-based learning, the most commonly-used methods for few-shot learning and zero-shot transferring from pre-trained vision-language models to downstream tasks, are conceptually similar. They both reformulate the objective of downstream tasks the same as the pre-training tasks, and mostly without tuning the parameters of pre-trained models. Based on this observation, we propose to combine meta-learning with prompt-based learning for multimodal FSOD without fine-tuning, by learning transferable class-agnostic multimodal FSOD models over many-shot base classes. Specifically, to better exploit the pre-trained vision-language models, the meta-learning based cross-modal prompting is proposed to generate soft prompts and further used to extract the semantic prototype, conditioned on the few-shot visual examples. Then, the extracted semantic prototype and few-shot visual prototype are fused to generate the multimodal prototype for detection. Our models can efficiently fuse the visual and semantic information at both token-level and feature-level. We comprehensively evaluate the proposed multimodal FSOD models on multiple few-shot object detection benchmarks, achieving promising results.