 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Masked Knowledge Distillation for Few-Shot Transformers
Paper and Code
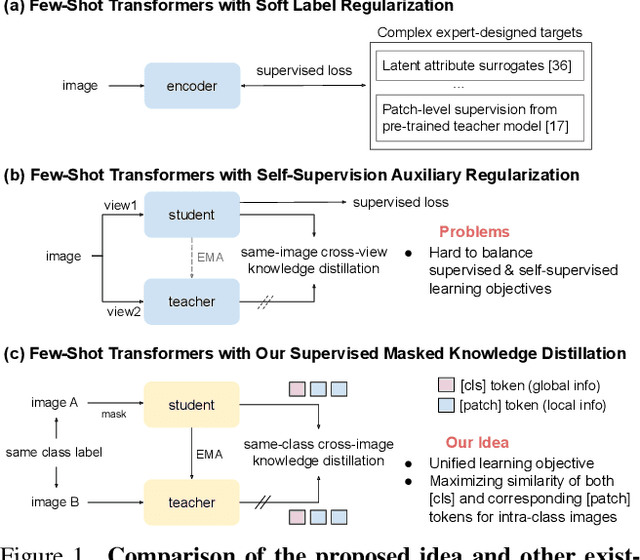
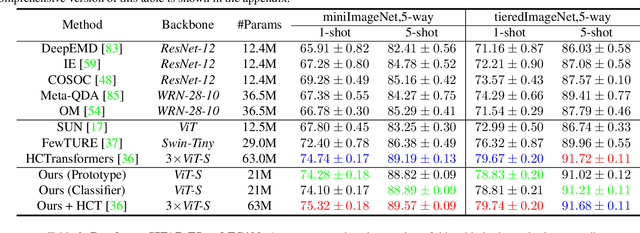
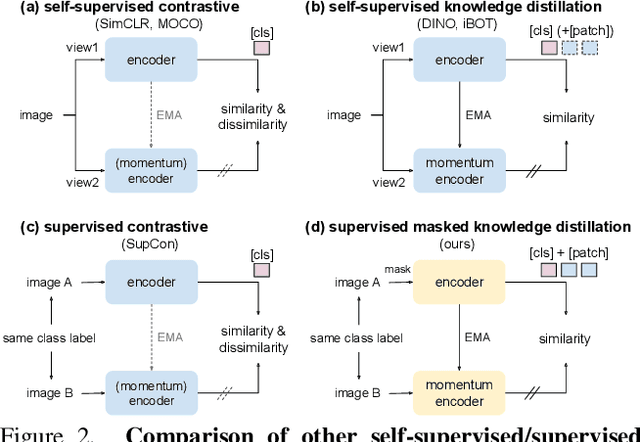
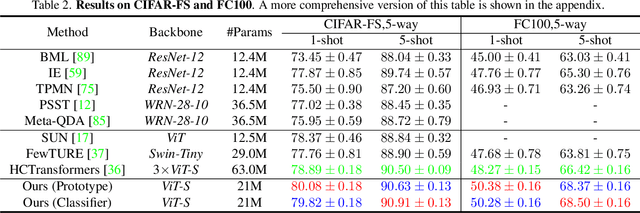
Vision Transformers (ViTs) emerge to achieve impressive performance on many data-abundant computer vision tasks by capturing long-range dependencies among local features. However, under few-shot learning (FSL) settings on small datasets with only a few labeled data, ViT tends to overfit and suffers from severe performance degradation due to its absence of CNN-alike inductive bias. Previous works in FSL avoid such problem either through the help of self-supervised auxiliary losses, or through the dextile uses of label information under supervised settings. But the gap between self-supervised and supervised few-shot Transformers is still unfilled. Inspired by recent advances in self-supervised knowledge distillation and masked image modeling (MIM), we propose a novel Supervised Masked Knowledge Distillation model (SMKD) for few-shot Transformers which incorporates label information into self-distillation frameworks. Compared with previous self-supervised methods, we allow intra-class knowledge distillation on both class and patch tokens, and introduce the challenging task of masked patch tokens reconstruction across intra-class images. Experimental results on four few-shot classification benchmark datasets show that our method with simple design outperforms previous methods by a large margin and achieves a new start-of-the-art. Detailed ablation studies confirm the effectiveness of each component of our model. Code for this paper is available here: https://github.com/HL-hanlin/SMKD.