 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Natural Language Processing Pipeline of Chinese Free-text Radiology Reports for Liver Cancer Diagnosis
Paper and Code
Apr 10, 2020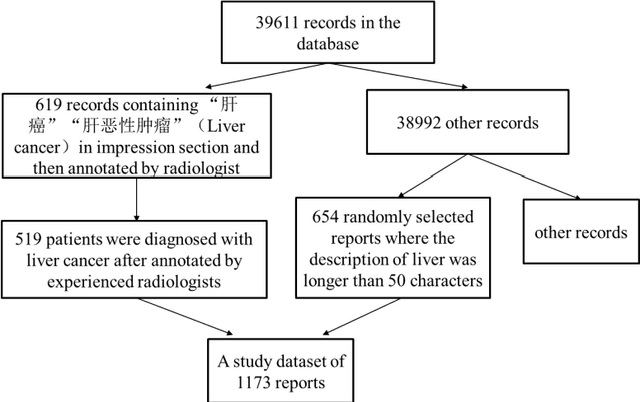

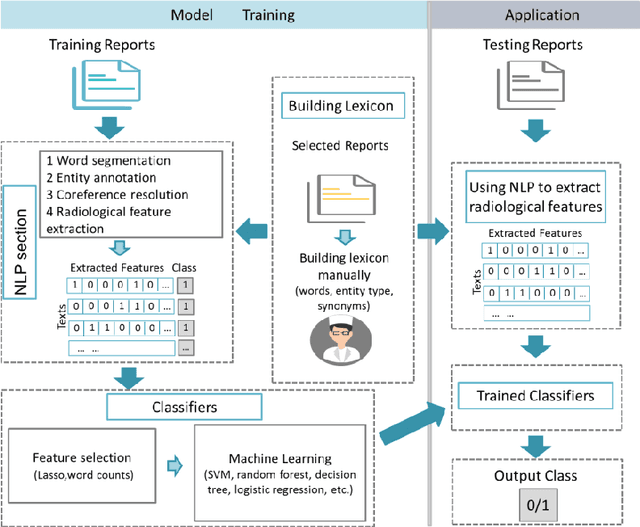
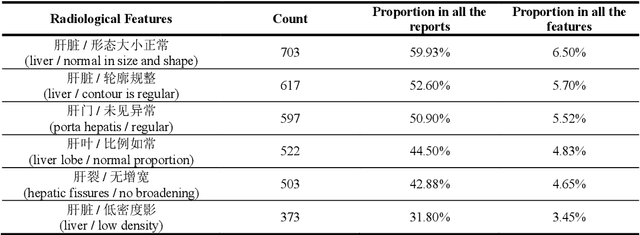
Background Despite the rapid development of natural language processing (NLP) implementation in electronic medical records (EMRs), Chinese EMRs processing remains challenging due to the limited corpus and specific grammatical characteristics, especially for radiology reports. This study sought to design an NLP pipeline for the direct extraction of clinically relevant features from Chinese radiology reports, which is the first key step in computer-aided radiologic diagnosis. Methods We implemented the NLP pipeline on abdominal computed tomography (CT) radiology reports written in Chinese. The pipeline was comprised of word segmentation, entity annotation, coreference resolution, and relationship extraction to finally derive the symptom features composed of one or more terms. The whole pipeline was based on a lexicon that was constructed manually according to Chinese grammatical characteristics. Least absolute shrinkage and selection operator (LASSO) and machine learning methods were used to build the classifiers for liver cancer prediction. Random forest model was also used to calculate the Gini impurity for identifying the most important features in liver cancer diagnosis. Results The lexicon finally contained 831 words. The features extracted by the NLP pipeline conformed to the original meaning of the radiology reports. SVM had a higher predictive performance in liver cancer diagnosis (F1 score 90.23%, precision 92.51%, and recall 88.05%). Conclusions Our study was a comprehensive NLP study focusing on Chinese radiology reports and the application of NLP in cancer risk prediction. The proposed method for the radiological feature extraction could be easily implemented in other kinds of Chinese clinical texts and other disease predictive tasks.