Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning via Synthetic Data
Paper and Code
Aug 11, 2020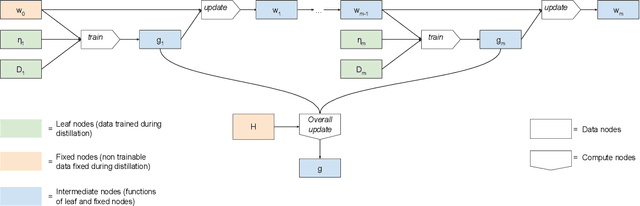
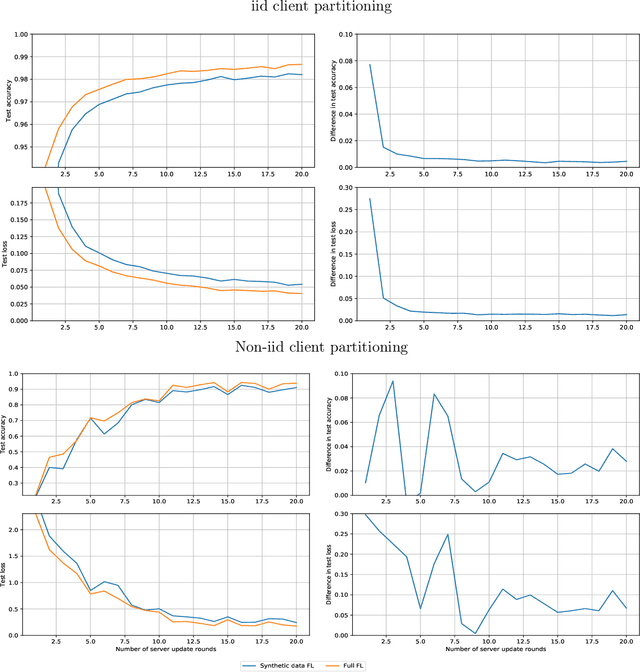
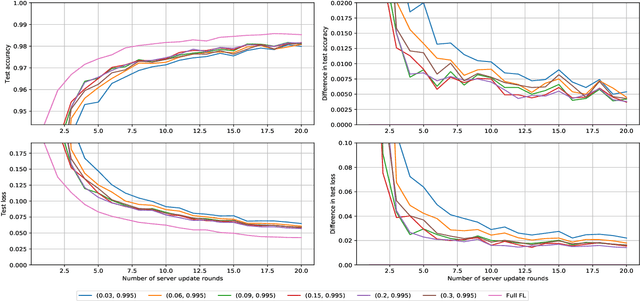

Federated learning allows for the training of a model using data on multiple clients without the clients transmitting that raw data. However the standard method is to transmit model parameters (or updates), which for modern neural networks can be on the scale of millions of parameters, inflicting significant computational costs on the clients. We propose a method for federated learning where instead of transmitting a gradient update back to the server, we instead transmit a small amount of synthetic `data'. We describe the procedure and show some experimental results suggesting this procedure has potential, providing more than an order of magnitude reduction in communication costs with minimal model degradation.
View paper on