 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBroadGen: A Framework for Generating Effective and Efficient Advertiser Broad Match Keyphrase Recommendations
May 25, 2025



In the domain of sponsored search advertising, the focus of Keyphrase recommendation has largely been on exact match types, which pose issues such as high management expenses, limited targeting scope, and evolving search query patterns. Alternatives like Broad match types can alleviate certain drawbacks of exact matches but present challenges like poor targeting accuracy and minimal supervisory signals owing to limited advertiser usage. This research defines the criteria for an ideal broad match, emphasizing on both efficiency and effectiveness, ensuring that a significant portion of matched queries are relevant. We propose BroadGen, an innovative framework that recommends efficient and effective broad match keyphrases by utilizing historical search query data. Additionally, we demonstrate that BroadGen, through token correspondence modeling, maintains better query stability over time. BroadGen's capabilities allow it to serve daily, millions of sellers at eBay with over 2.3 billion items.
GraphEx: A Graph-based Extraction Method for Advertiser Keyphrase Recommendation
Sep 05, 2024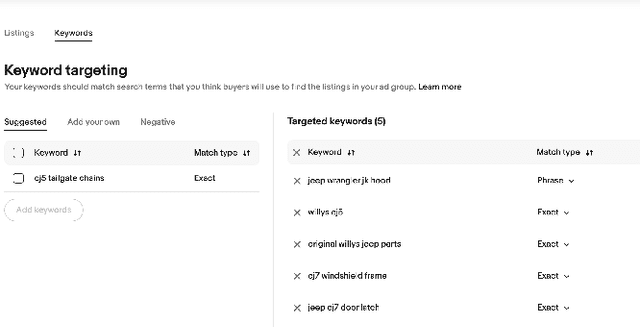
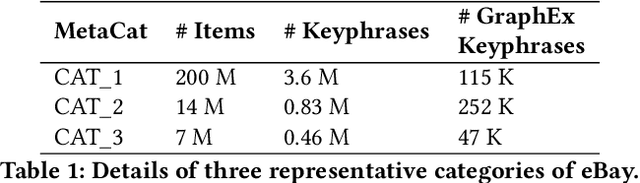
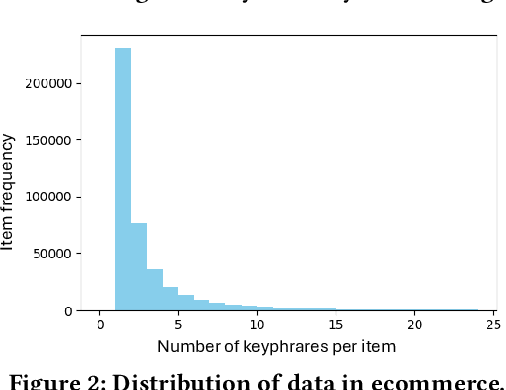
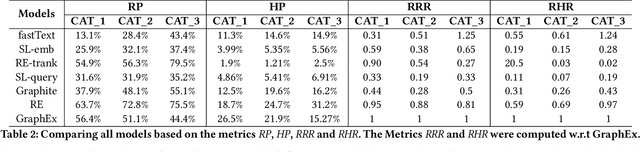
Online sellers and advertisers are recommended keyphrases for their listed products, which they bid on to enhance their sales. One popular paradigm that generates such recommendations is Extreme Multi-Label Classification (XMC), which involves tagging/mapping keyphrases to items. We outline the limitations of using traditional item-query based tagging or mapping techniques for keyphrase recommendations on E-Commerce platforms. We introduce GraphEx, an innovative graph-based approach that recommends keyphrases to sellers using extraction of token permutations from item titles. Additionally, we demonstrate that relying on traditional metrics such as precision/recall can be misleading in practical applications, thereby necessitating a combination of metrics to evaluate performance in real-world scenarios. These metrics are designed to assess the relevance of keyphrases to items and the potential for buyer outreach. GraphEx outperforms production models at eBay, achieving the objectives mentioned above. It supports near real-time inferencing in resource-constrained production environments and scales effectively for billions of items.
Graphite: A Graph-based Extreme Multi-Label Short Text Classifier for Keyphrase Recommendation
Jul 29, 2024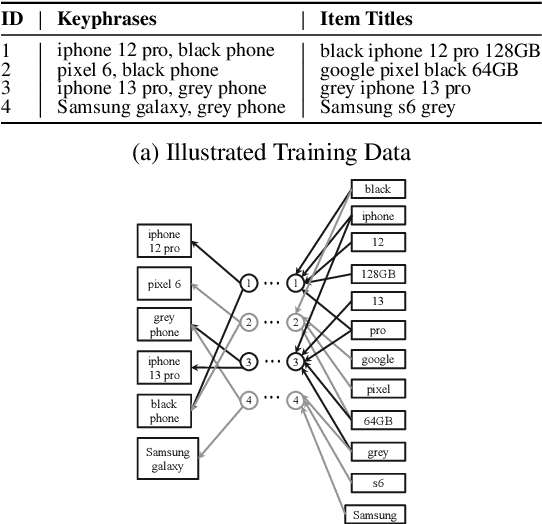
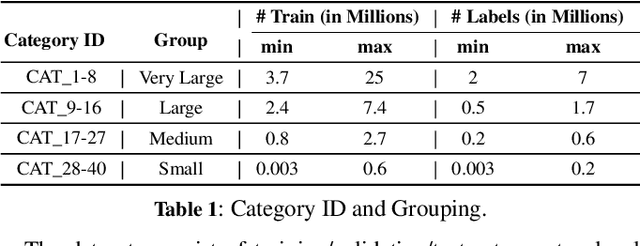
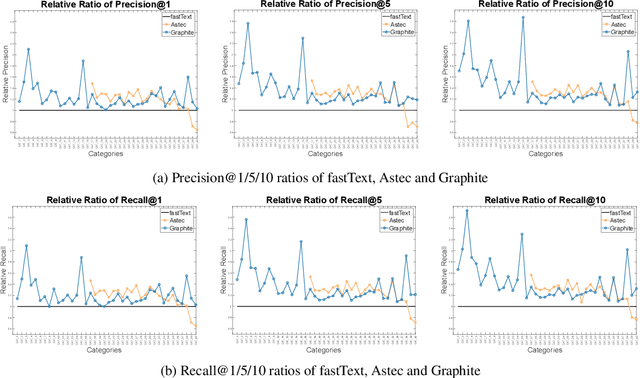
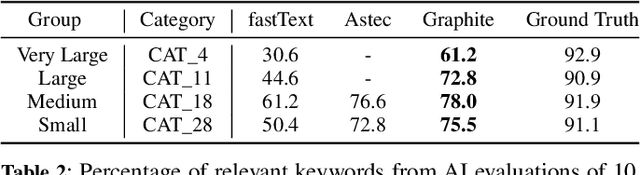
Keyphrase Recommendation has been a pivotal problem in advertising and e-commerce where advertisers/sellers are recommended keyphrases (search queries) to bid on to increase their sales. It is a challenging task due to the plethora of items shown on online platforms and various possible queries that users search while showing varying interest in the displayed items. Moreover, query/keyphrase recommendations need to be made in real-time and in a resource-constrained environment. This problem can be framed as an Extreme Multi-label (XML) Short text classification by tagging the input text with keywords as labels. Traditional neural network models are either infeasible or have slower inference latency due to large label spaces. We present Graphite, a graph-based classifier model that provides real-time keyphrase recommendations that are on par with standard text classification models. Furthermore, it doesn't utilize GPU resources, which can be limited in production environments. Due to its lightweight nature and smaller footprint, it can train on very large datasets, where state-of-the-art XML models fail due to extreme resource requirements. Graphite is deterministic, transparent, and intrinsically more interpretable than neural network-based models. We present a comprehensive analysis of our model's performance across forty categories spanning eBay's English-speaking sites.
Convex Latent Effect Logit Model via Sparse and Low-rank Decomposition
Aug 22, 2021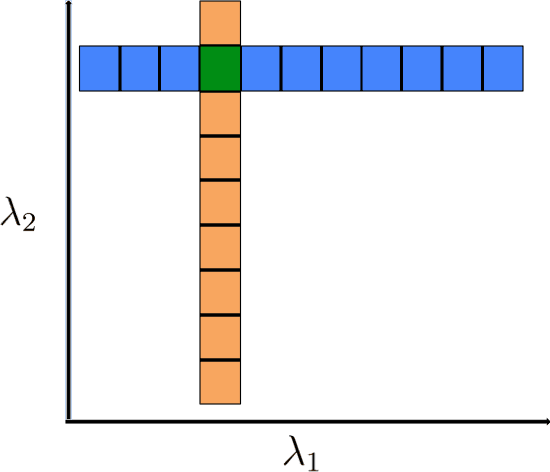
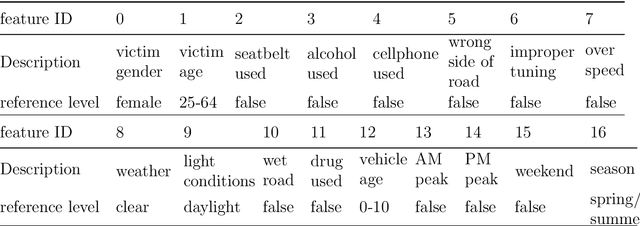
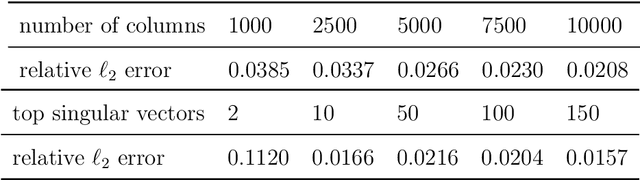
In this paper, we propose a convex formulation for learning logistic regression model (logit) with latent heterogeneous effect on sub-population. In transportation, logistic regression and its variants are often interpreted as discrete choice models under utility theory (McFadden, 2001). Two prominent applications of logit models in the transportation domain are traffic accident analysis and choice modeling. In these applications, researchers often want to understand and capture the individual variation under the same accident or choice scenario. The mixed effect logistic regression (mixed logit) is a popular model employed by transportation researchers. To estimate the distribution of mixed logit parameters, a non-convex optimization problem with nested high-dimensional integrals needs to be solved. Simulation-based optimization is typically applied to solve the mixed logit parameter estimation problem. Despite its popularity, the mixed logit approach for learning individual heterogeneity has several downsides. First, the parametric form of the distribution requires domain knowledge and assumptions imposed by users, although this issue can be addressed to some extent by using a non-parametric approach. Second, the optimization problems arise from parameter estimation for mixed logit and the non-parametric extensions are non-convex, which leads to unstable model interpretation. Third, the simulation size in simulation-assisted estimation lacks finite-sample theoretical guarantees and is chosen somewhat arbitrarily in practice. To address these issues, we are motivated to develop a formulation that models the latent individual heterogeneity while preserving convexity, and avoids the need for simulation-based approximation. Our setup is based on decomposing the parameters into a sparse homogeneous component in the population and low-rank heterogeneous parts for each individual.
Efficient Online Hyperparameter Optimization for Kernel Ridge Regression with Applications to Traffic Time Series Prediction
Nov 01, 2018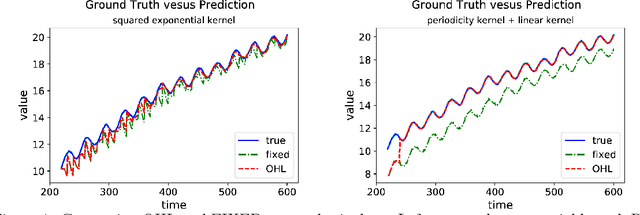
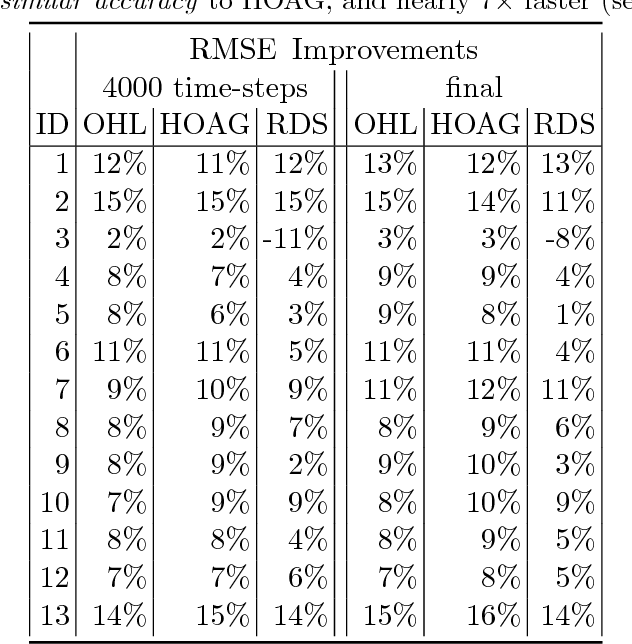
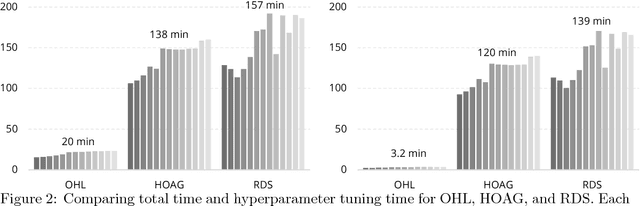
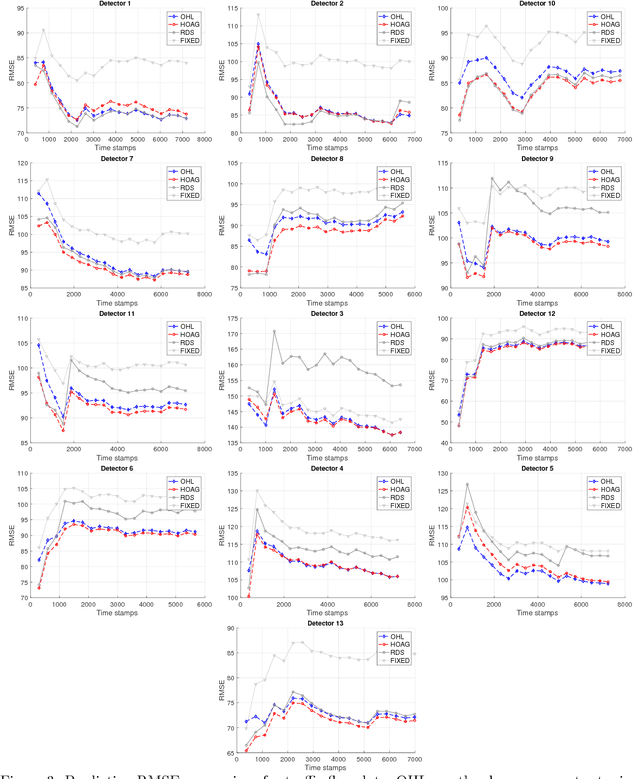
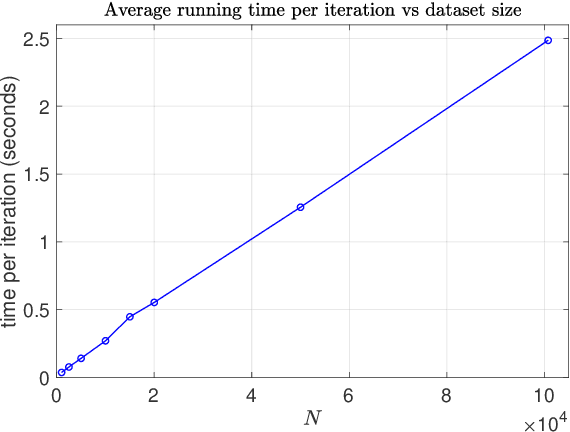
Computational efficiency is an important consideration for deploying machine learning models for time series prediction in an online setting. Machine learning algorithms adjust model parameters automatically based on the data, but often require users to set additional parameters, known as hyperparameters. Hyperparameters can significantly impact prediction accuracy. Traffic measurements, typically collected online by sensors, are serially correlated. Moreover, the data distribution may change gradually. A typical adaptation strategy is periodically re-tuning the model hyperparameters, at the cost of computational burden. In this work, we present an efficient and principled online hyperparameter optimization algorithm for Kernel Ridge regression applied to traffic prediction problems. In tests with real traffic measurement data, our approach requires as little as one-seventh of the computation time of other tuning methods, while achieving better or similar prediction accuracy.
* An extended version of "Efficient Online Hyperparameter Learning for Traffic Flow Prediction" published in The 21st IEEE International Conference on Intelligent Transportation Systems (ITSC 2018)