 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning with Buffered Asynchronous Aggregation
Paper and Code
Jun 11, 2021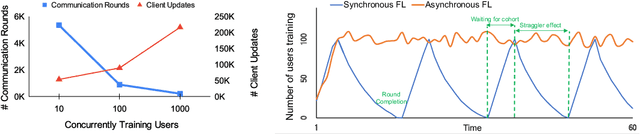

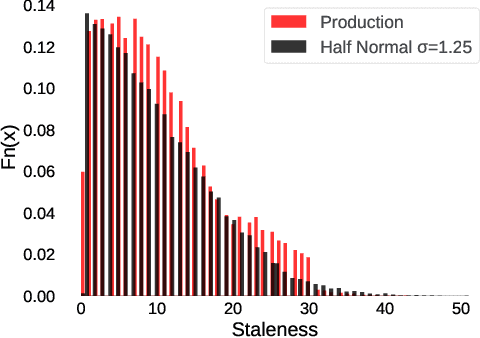

Federated Learning (FL) trains a shared model across distributed devices while keeping the training data on the devices. Most FL schemes are synchronous: they perform a synchronized aggregation of model updates from individual devices. Synchronous training can be slow because of late-arriving devices (stragglers). On the other hand, completely asynchronous training makes FL less private because of incompatibility with secure aggregation. In this work, we propose a model aggregation scheme, FedBuff, that combines the best properties of synchronous and asynchronous FL. Similar to synchronous FL, FedBuff is compatible with secure aggregation. Similar to asynchronous FL, FedBuff is robust to stragglers. In FedBuff, clients trains asynchronously and send updates to the server. The server aggregates client updates in a private buffer until updates have been received, at which point a server model update is immediately performed. We provide theoretical convergence guarantees for FedBuff in a non-convex setting. Empirically, FedBuff converges up to 3.8x faster than previous proposals for synchronous FL (e.g., FedAvgM), and up to 2.5x faster than previous proposals for asynchronous FL (e.g., FedAsync). We show that FedBuff is robust to different staleness distributions and is more scalable than synchronous FL techniques.