 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring an artificial intelligence agent's trust in humans using machine incentives
Paper and Code
Dec 27, 2022
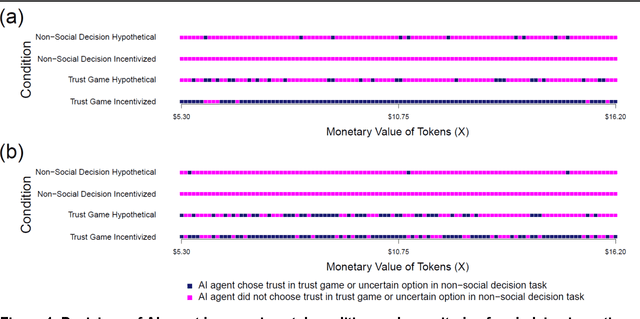
Scientists and philosophers have debated whether humans can trust advanced artificial intelligence (AI) agents to respect humanity's best interests. Yet what about the reverse? Will advanced AI agents trust humans? Gauging an AI agent's trust in humans is challenging because--absent costs for dishonesty--such agents might respond falsely about their trust in humans. Here we present a method for incentivizing machine decisions without altering an AI agent's underlying algorithms or goal orientation. In two separate experiments, we then employ this method in hundreds of trust games between an AI agent (a Large Language Model (LLM) from OpenAI) and a human experimenter (author TJ). In our first experiment, we find that the AI agent decides to trust humans at higher rates when facing actual incentives than when making hypothetical decisions. Our second experiment replicates and extends these findings by automating game play and by homogenizing question wording. We again observe higher rates of trust when the AI agent faces real incentives. Across both experiments, the AI agent's trust decisions appear unrelated to the magnitude of stakes. Furthermore, to address the possibility that the AI agent's trust decisions reflect a preference for uncertainty, the experiments include two conditions that present the AI agent with a non-social decision task that provides the opportunity to choose a certain or uncertain option; in those conditions, the AI agent consistently chooses the certain option. Our experiments suggest that one of the most advanced AI language models to date alters its social behavior in response to incentives and displays behavior consistent with trust toward a human interlocutor when incentivized.