 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoice conversion with limited data and limitless data augmentations
Dec 27, 2022Applying changes to an input speech signal to change the perceived speaker of speech to a target while maintaining the content of the input is a challenging but interesting task known as Voice conversion (VC). Over the last few years, this task has gained significant interest where most systems use data-driven machine learning models. Doing the conversion in a low-latency real-world scenario is even more challenging constrained by the availability of high-quality data. Data augmentations such as pitch shifting and noise addition are often used to increase the amount of data used for training machine learning based models for this task. In this paper we explore the efficacy of common data augmentation techniques for real-time voice conversion and introduce novel techniques for data augmentation based on audio and voice transformation effects as well. We evaluate the conversions for both male and female target speakers using objective and subjective evaluation methodologies.
Locate This, Not That: Class-Conditioned Sound Event DOA Estimation
Mar 08, 2022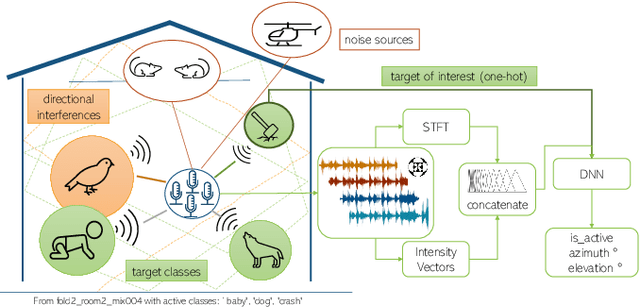
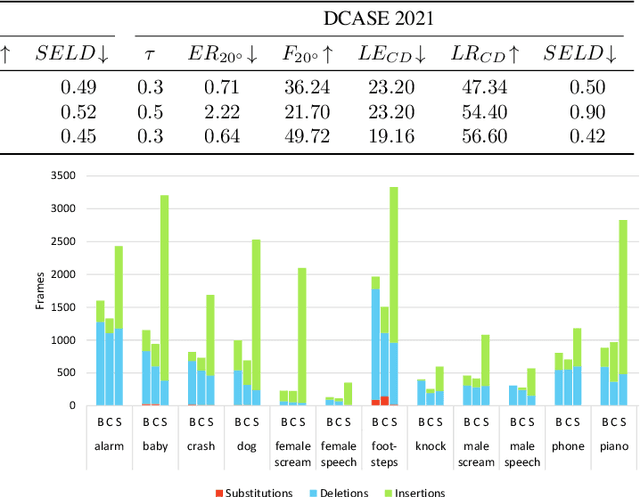
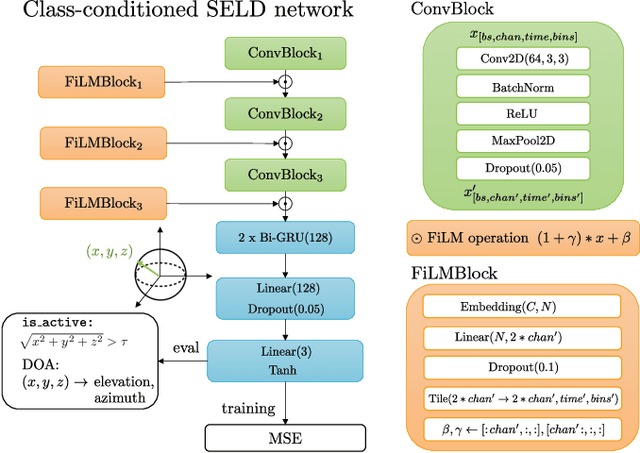
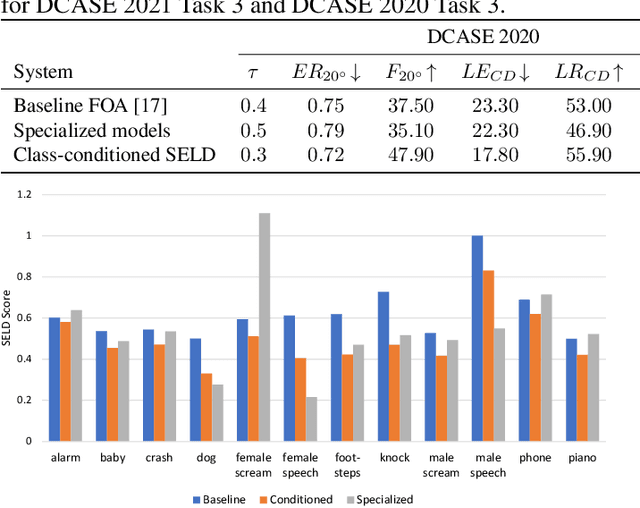
Existing systems for sound event localization and detection (SELD) typically operate by estimating a source location for all classes at every time instant. In this paper, we propose an alternative class-conditioned SELD model for situations where we may not be interested in localizing all classes all of the time. This class-conditioned SELD model takes as input the spatial and spectral features from the sound file, and also a one-hot vector indicating the class we are currently interested in localizing. We inject the conditioning information at several points in our model using feature-wise linear modulation (FiLM) layers. Through experiments on the DCASE 2020 Task 3 dataset, we show that the proposed class-conditioned SELD model performs better in terms of common SELD metrics than the baseline model that locates all classes simultaneously, and also outperforms specialist models that are trained to locate only a single class of interest. We also evaluate performance on the DCASE 2021 Task 3 dataset, which includes directional interference (sound events from classes we are not interested in localizing) and notice especially strong improvement from the class-conditioned model.
Vocoder-Based Speech Synthesis from Silent Videos
Apr 06, 2020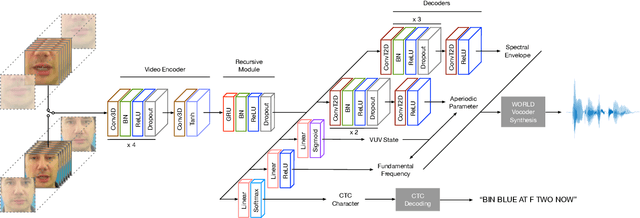
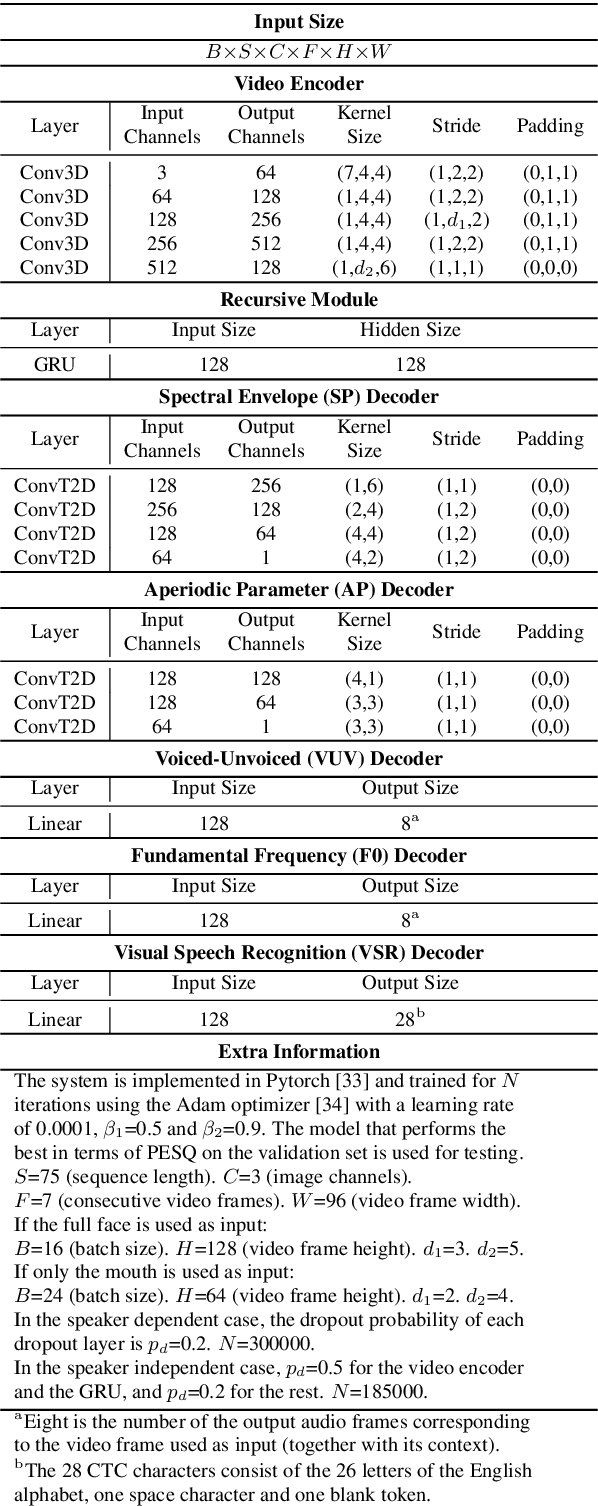

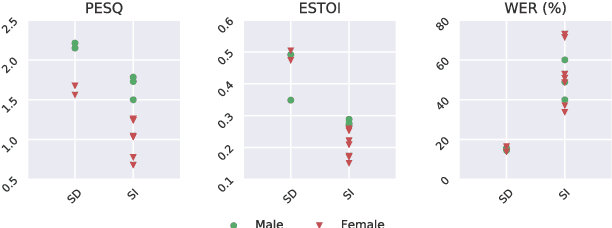
Both acoustic and visual information influence human perception of speech. For this reason, the lack of audio in a video sequence determines an extremely low speech intelligibility for untrained lip readers. In this paper, we present a way to synthesise speech from the silent video of a talker using deep learning. The system learns a mapping function from raw video frames to acoustic features and reconstructs the speech with a vocoder synthesis algorithm. To improve speech reconstruction performance, our model is also trained to predict text information in a multi-task learning fashion and it is able to simultaneously reconstruct and recognise speech in real time. The results in terms of estimated speech quality and intelligibility show the effectiveness of our method, which exhibits an improvement over existing video-to-speech approaches.
Input complexity and out-of-distribution detection with likelihood-based generative models
Sep 25, 2019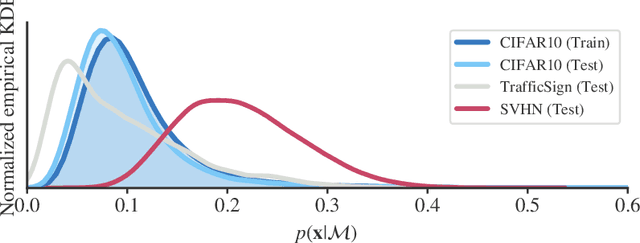
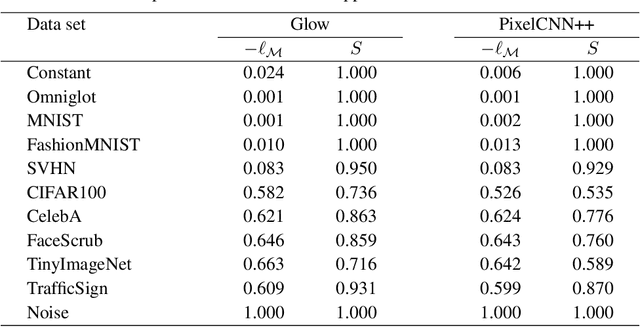

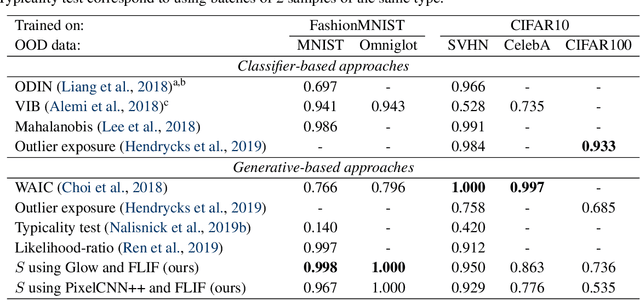
Likelihood-based generative models are a promising resource to detect out-of-distribution (OOD) inputs which could compromise the robustness or reliability of a machine learning system. However, likelihoods derived from such models have been shown to be problematic for detecting certain types of inputs that significantly differ from training data. In this paper, we pose that this problem is due to the excessive influence that input complexity has in generative models' likelihoods. We report a set of experiments supporting this hypothesis, and use an estimate of input complexity to derive an efficient and parameter-free OOD score, which can be seen as a likelihood-ratio test akin to Bayesian model comparison. We find such score to perform comparably to, or even better than, existing OOD detection approaches under a wide range of data sets, models, and complexity estimates.
A Case Study of Deep-Learned Activations via Hand-Crafted Audio Features
Jul 03, 2019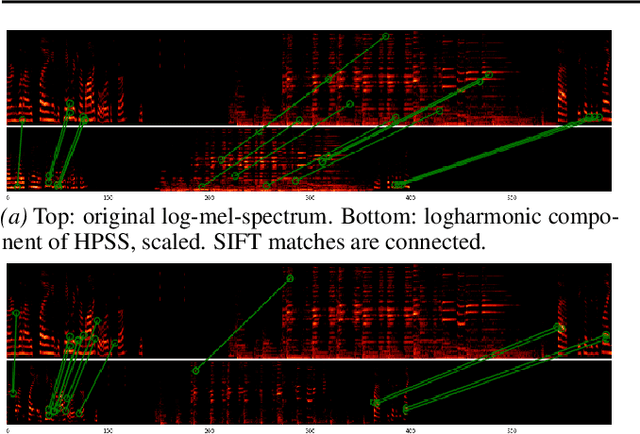

The explainability of Convolutional Neural Networks (CNNs) is a particularly challenging task in all areas of application, and it is notably under-researched in music and audio domain. In this paper, we approach explainability by exploiting the knowledge we have on hand-crafted audio features. Our study focuses on a well-defined MIR task, the recognition of musical instruments from user-generated music recordings. We compute the similarity between a set of traditional audio features and representations learned by CNNs. We also propose a technique for measuring the similarity between activation maps and audio features which typically presented in the form of a matrix, such as chromagrams or spectrograms. We observe that some neurons' activations correspond to well-known classical audio features. In particular, for shallow layers, we found similarities between activations and harmonic and percussive components of the spectrum. For deeper layers, we compare chromagrams with high-level activation maps as well as loudness and onset rate with deep-learned embeddings.
End-to-End Sound Source Separation Conditioned On Instrument Labels
Nov 05, 2018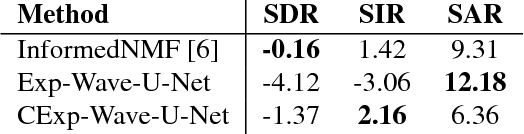
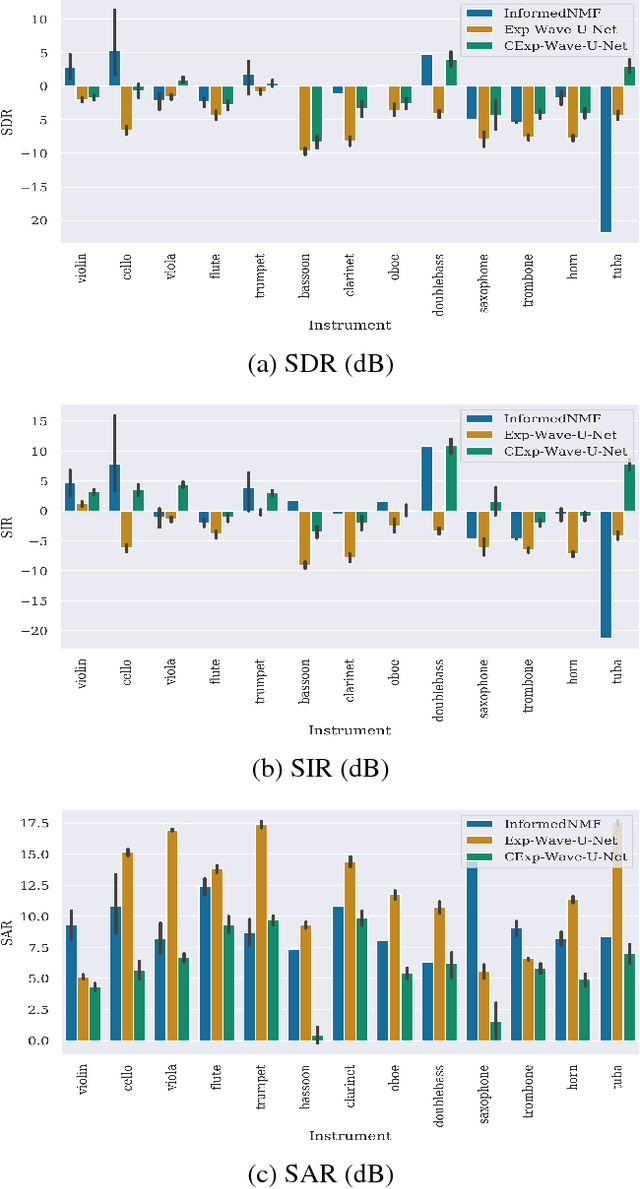
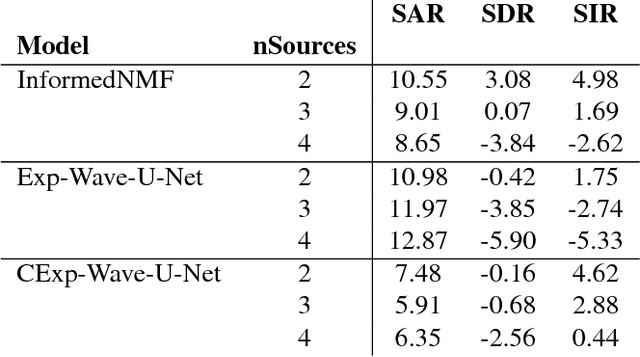
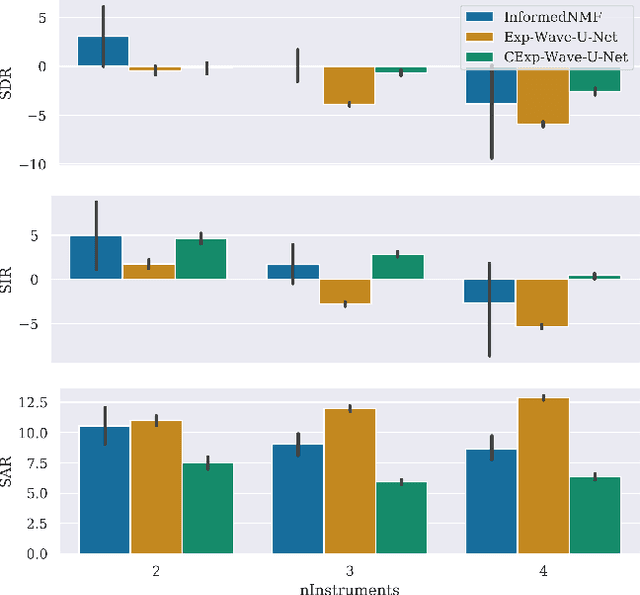
Can we perform an end-to-end sound source separation (SSS) with a variable number of sources using a deep learning model? This paper presents an extension of the Wave-U-Net model which allows end-to-end monaural source separation with a non-fixed number of sources. Furthermore, we propose multiplicative conditioning with instrument labels at the bottleneck of the Wave-U-Net and show its effect on the separation results. This approach can be further extended to other types of conditioning such as audio-visual SSS and score-informed SSS.