 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised Learning for Singing Synthesis Timbre
Nov 05, 2020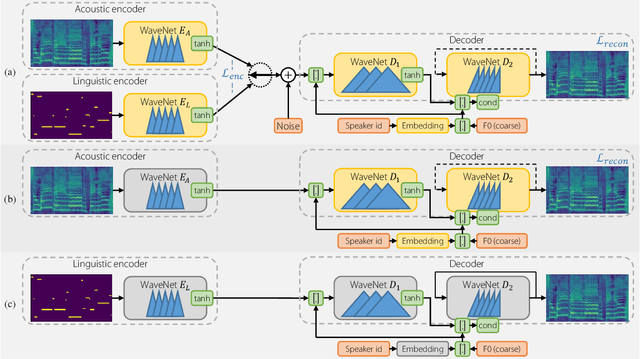
We propose a semi-supervised singing synthesizer, which is able to learn new voices from audio data only, without any annotations such as phonetic segmentation. Our system is an encoder-decoder model with two encoders, linguistic and acoustic, and one (acoustic) decoder. In a first step, the system is trained in a supervised manner, using a labelled multi-singer dataset. Here, we ensure that the embeddings produced by both encoders are similar, so that we can later use the model with either acoustic or linguistic input features. To learn a new voice in an unsupervised manner, the pretrained acoustic encoder is used to train a decoder for the target singer. Finally, at inference, the pretrained linguistic encoder is used together with the decoder of the new voice, to produce acoustic features from linguistic input. We evaluate our system with a listening test and show that the results are comparable to those obtained with an equivalent supervised approach.
Deep Learning Based Source Separation Applied To Choir Ensembles
Aug 17, 2020
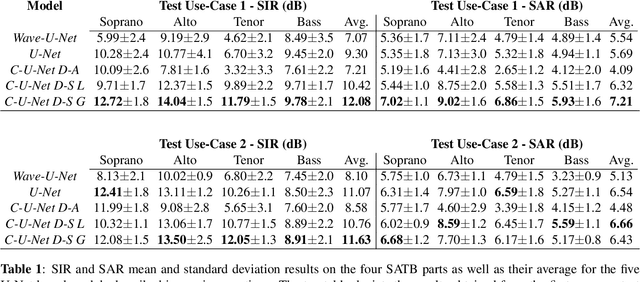
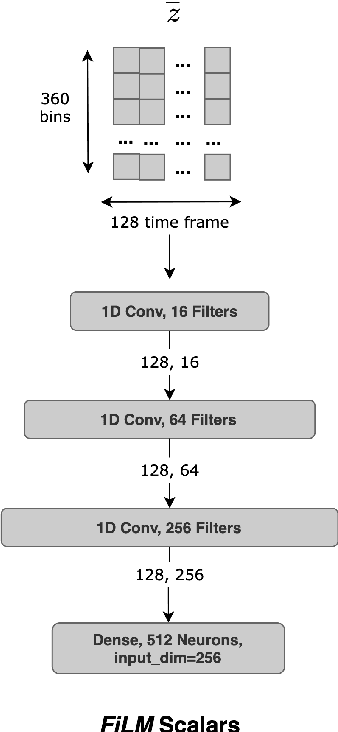
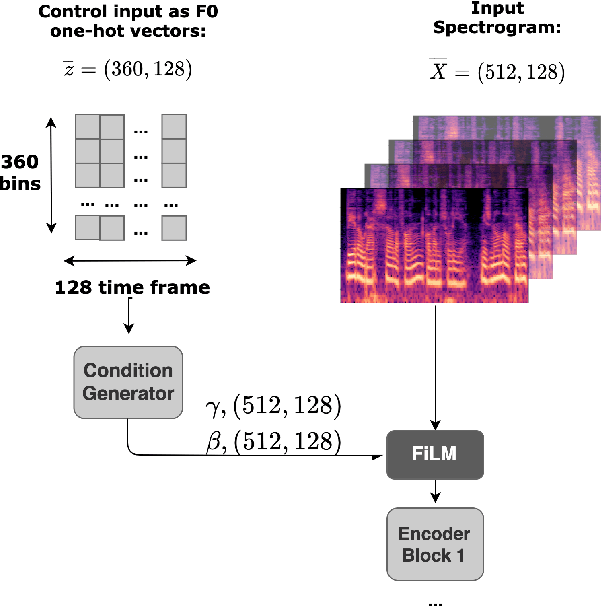
Choral singing is a widely practiced form of ensemble singing wherein a group of people sing simultaneously in polyphonic harmony. The most commonly practiced setting for choir ensembles consists of four parts; Soprano, Alto, Tenor and Bass (SATB), each with its own range of fundamental frequencies (F$0$s). The task of source separation for this choral setting entails separating the SATB mixture into the constituent parts. Source separation for musical mixtures is well studied and many deep learning based methodologies have been proposed for the same. However, most of the research has been focused on a typical case which consists in separating vocal, percussion and bass sources from a mixture, each of which has a distinct spectral structure. In contrast, the simultaneous and harmonic nature of ensemble singing leads to high structural similarity and overlap between the spectral components of the sources in a choral mixture, making source separation for choirs a harder task than the typical case. This, along with the lack of an appropriate consolidated dataset has led to a dearth of research in the field so far. In this paper we first assess how well some of the recently developed methodologies for musical source separation perform for the case of SATB choirs. We then propose a novel domain-specific adaptation for conditioning the recently proposed U-Net architecture for musical source separation using the fundamental frequency contour of each of the singing groups and demonstrate that our proposed approach surpasses results from domain-agnostic architectures.
Content Based Singing Voice Extraction From a Musical Mixture
Feb 17, 2020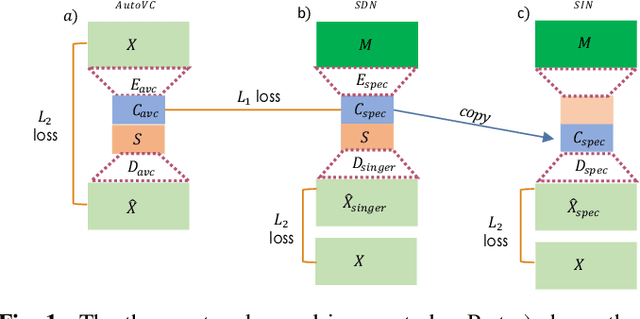
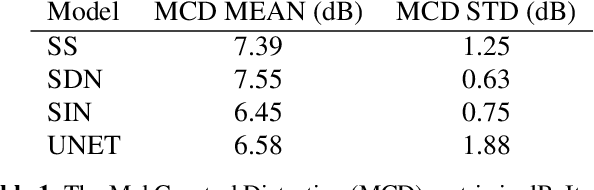
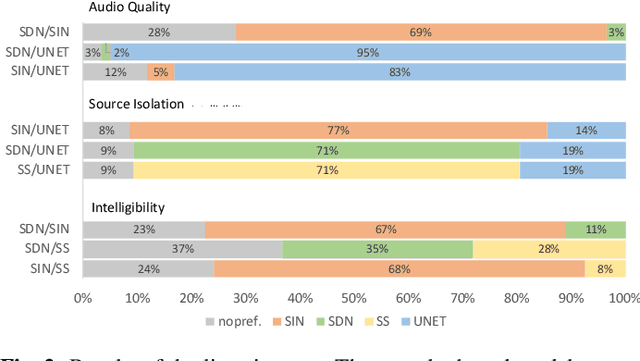
We present a deep learning based methodology for extracting the singing voice signal from a musical mixture based on the underlying linguistic content. Our model follows an encoder decoder architecture and takes as input the magnitude component of the spectrogram of a musical mixture with vocals. The encoder part of the model is trained via knowledge distillation using a teacher network to learn a content embedding, which is decoded to generate the corresponding vocoder features. Using this methodology, we are able to extract the unprocessed raw vocal signal from the mixture even for a processed mixture dataset with singers not seen during training. While the nature of our system makes it incongruous with traditional objective evaluation metrics, we use subjective evaluation via listening tests to compare the methodology to state-of-the-art deep learning based source separation algorithms. We also provide sound examples and source code for reproducibility.
* To be published in ICASSP 2020
Sequence-to-sequence Singing Synthesis Using the Feed-forward Transformer
Oct 22, 2019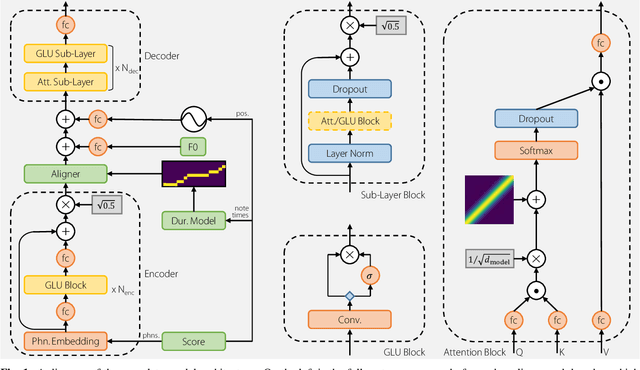

We propose a sequence-to-sequence singing synthesizer, which avoids the need for training data with pre-aligned phonetic and acoustic features. Rather than the more common approach of a content-based attention mechanism combined with an autoregressive decoder, we use a different mechanism suitable for feed-forward synthesis. Given that phonetic timings in singing are highly constrained by the musical score, we derive an approximate initial alignment with the help of a simple duration model. Then, using a decoder based on a feed-forward variant of the Transformer model, a series of self-attention and convolutional layers refines the result of the initial alignment to reach the target acoustic features. Advantages of this approach include faster inference and avoiding the exposure bias issues that affect autoregressive models trained by teacher forcing. We evaluate the effectiveness of this model compared to an autoregressive baseline, the importance of self-attention, and the importance of the accuracy of the duration model.
Data Efficient Voice Cloning for Neural Singing Synthesis
Feb 19, 2019


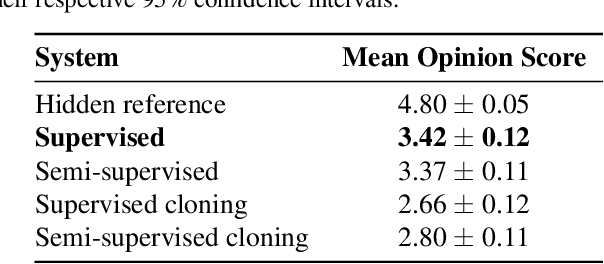
There are many use cases in singing synthesis where creating voices from small amounts of data is desirable. In text-to-speech there have been several promising results that apply voice cloning techniques to modern deep learning based models. In this work, we adapt one such technique to the case of singing synthesis. By leveraging data from many speakers to first create a multispeaker model, small amounts of target data can then efficiently adapt the model to new unseen voices. We evaluate the system using listening tests across a number of different use cases, languages and kinds of data.
Deep Learning for Singing Processing: Achievements, Challenges and Impact on Singers and Listeners
Jul 09, 2018
This paper summarizes some recent advances on a set of tasks related to the processing of singing using state-of-the-art deep learning techniques. We discuss their achievements in terms of accuracy and sound quality, and the current challenges, such as availability of data and computing resources. We also discuss the impact that these advances do and will have on listeners and singers when they are integrated in commercial applications.
A Neural Parametric Singing Synthesizer
Aug 17, 2017

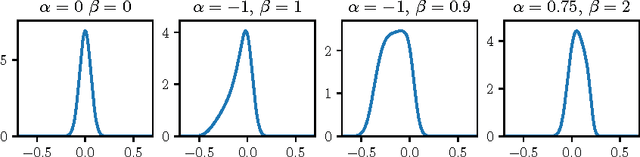
We present a new model for singing synthesis based on a modified version of the WaveNet architecture. Instead of modeling raw waveform, we model features produced by a parametric vocoder that separates the influence of pitch and timbre. This allows conveniently modifying pitch to match any target melody, facilitates training on more modest dataset sizes, and significantly reduces training and generation times. Our model makes frame-wise predictions using mixture density outputs rather than categorical outputs in order to reduce the required parameter count. As we found overfitting to be an issue with the relatively small datasets used in our experiments, we propose a method to regularize the model and make the autoregressive generation process more robust to prediction errors. Using a simple multi-stream architecture, harmonic, aperiodic and voiced/unvoiced components can all be predicted in a coherent manner. We compare our method to existing parametric statistical and state-of-the-art concatenative methods using quantitative metrics and a listening test. While naive implementations of the autoregressive generation algorithm tend to be inefficient, using a smart algorithm we can greatly speed up the process and obtain a system that's competitive in both speed and quality.