 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigital twins to alleviate the need for real field data in vision-based vehicle speed detection systems
Jul 11, 2024



Accurate vision-based speed estimation is much more cost-effective than traditional methods based on radar or LiDAR. However, it is also challenging due to the limitations of perspective projection on a discrete sensor, as well as the high sensitivity to calibration, lighting and weather conditions. Interestingly, deep learning approaches (which dominate the field of computer vision) are very limited in this context due to the lack of available data. Indeed, obtaining video sequences of real road traffic with accurate speed values associated with each vehicle is very complex and costly, and the number of available datasets is very limited. Recently, some approaches are focusing on the use of synthetic data. However, it is still unclear how models trained on synthetic data can be effectively applied to real world conditions. In this work, we propose the use of digital-twins using CARLA simulator to generate a large dataset representative of a specific real-world camera. The synthetic dataset contains a large variability of vehicle types, colours, speeds, lighting and weather conditions. A 3D CNN model is trained on the digital twin and tested on the real sequences. Unlike previous approaches that generate multi-camera sequences, we found that the gap between the the real and the virtual conditions is a key factor in obtaining low speed estimation errors. Even with a preliminary approach, the mean absolute error obtained remains below 3km/h.
Towards view-invariant vehicle speed detection from driving simulator images
Jun 01, 2022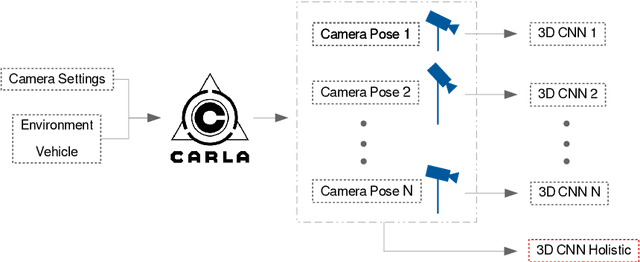
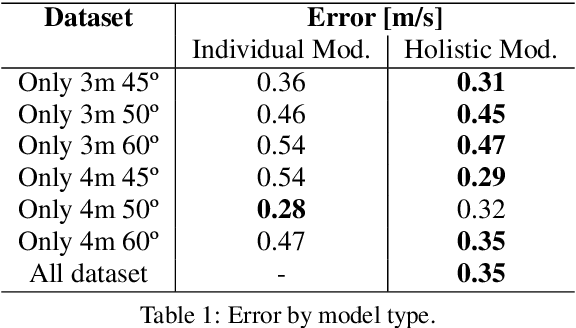
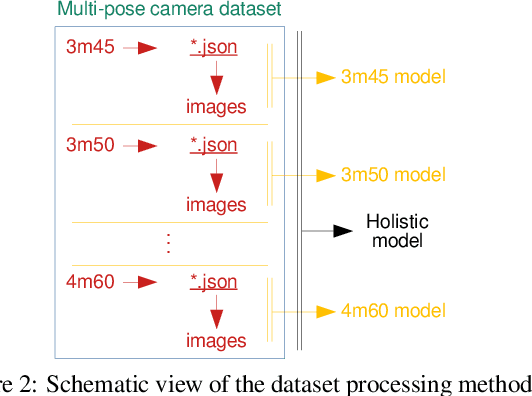

The use of cameras for vehicle speed measurement is much more cost effective compared to other technologies such as inductive loops, radar or laser. However, accurate speed measurement remains a challenge due to the inherent limitations of cameras to provide accurate range estimates. In addition, classical vision-based methods are very sensitive to extrinsic calibration between the camera and the road. In this context, the use of data-driven approaches appears as an interesting alternative. However, data collection requires a complex and costly setup to record videos under real traffic conditions from the camera synchronized with a high-precision speed sensor to generate the ground truth speed values. It has recently been demonstrated that the use of driving simulators (e.g., CARLA) can serve as a robust alternative for generating large synthetic datasets to enable the application of deep learning techniques for vehicle speed estimation for a single camera. In this paper, we study the same problem using multiple cameras in different virtual locations and with different extrinsic parameters. We address the question of whether complex 3D-CNN architectures are capable of implicitly learning view-invariant speeds using a single model, or whether view-specific models are more appropriate. The results are very promising as they show that a single model with data from multiple views reports even better accuracy than camera-specific models, paving the way towards a view-invariant vehicle speed measurement system.
Data-driven vehicle speed detection from synthetic driving simulator images
Apr 20, 2021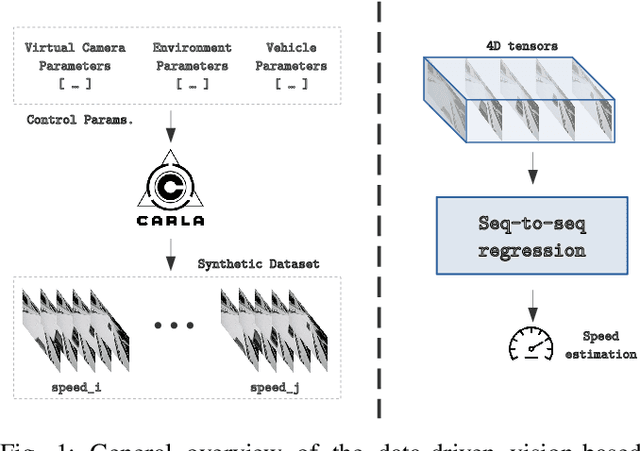
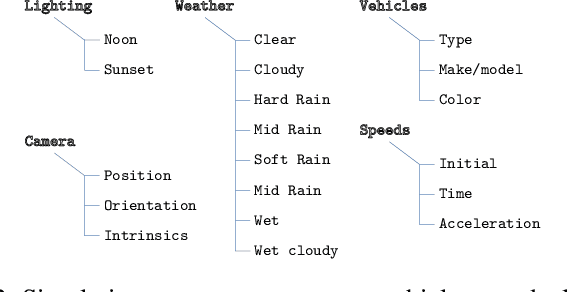
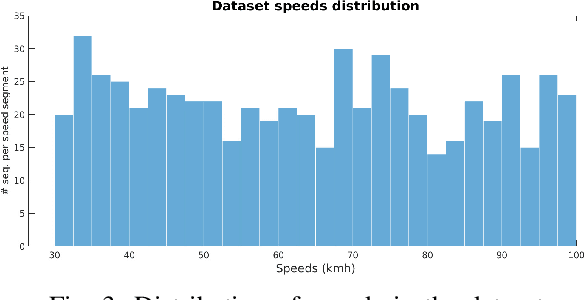

Despite all the challenges and limitations, vision-based vehicle speed detection is gaining research interest due to its great potential benefits such as cost reduction, and enhanced additional functions. As stated in a recent survey [1], the use of learning-based approaches to address this problem is still in its infancy. One of the main difficulties is the need for a large amount of data, which must contain the input sequences and, more importantly, the output values corresponding to the actual speed of the vehicles. Data collection in this context requires a complex and costly setup to capture the images from the camera synchronized with a high precision speed sensor to generate the ground truth speed values. In this paper we explore, for the first time, the use of synthetic images generated from a driving simulator (e.g., CARLA) to address vehicle speed detection using a learning-based approach. We simulate a virtual camera placed over a stretch of road, and generate thousands of images with variability corresponding to multiple speeds, different vehicle types and colors, and lighting and weather conditions. Two different approaches to map the sequence of images to an output speed (regression) are studied, including CNN-GRU and 3D-CNN. We present preliminary results that support the high potential of this approach to address vehicle speed detection.
Vision-based Vehicle Speed Estimation for ITS: A Survey
Jan 15, 2021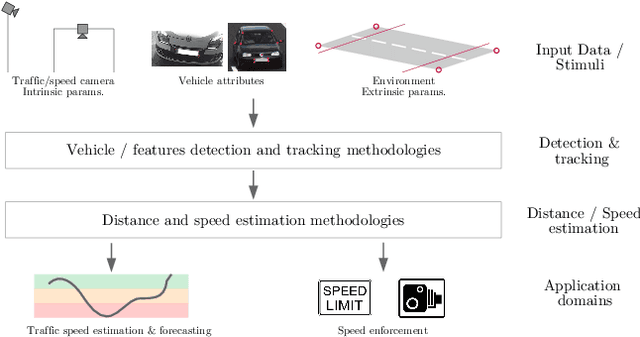


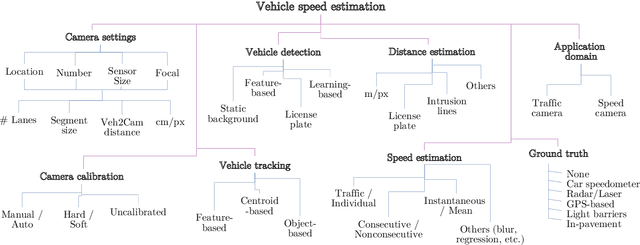
The need to accurately estimate the speed of road vehicles is becoming increasingly important for at least two main reasons. First, the number of speed cameras installed worldwide has been growing in recent years, as the introduction and enforcement of appropriate speed limits is considered one of the most effective means to increase the road safety. Second, traffic monitoring and forecasting in road networks plays a fundamental role to enhance traffic, emissions and energy consumption in smart cities, being the speed of the vehicles one of the most relevant parameters of the traffic state. Among the technologies available for the accurate detection of vehicle speed, the use of vision-based systems brings great challenges to be solved, but also great potential advantages, such as the drastic reduction of costs due to the absence of expensive range sensors, and the possibility of identifying vehicles accurately. This paper provides a review of vision-based vehicle speed estimation. We describe the terminology, the application domains, and propose a complete taxonomy of a large selection of works that categorizes all stages involved. An overview of performance evaluation metrics and available datasets is provided. Finally, we discuss current limitations and future directions.