 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttribute Annotation and Bias Evaluation in Visual Datasets for Autonomous Driving
Dec 11, 2023This paper addresses the often overlooked issue of fairness in the autonomous driving domain, particularly in vision-based perception and prediction systems, which play a pivotal role in the overall functioning of Autonomous Vehicles (AVs). We focus our analysis on biases present in some of the most commonly used visual datasets for training person and vehicle detection systems. We introduce an annotation methodology and a specialised annotation tool, both designed to annotate protected attributes of agents in visual datasets. We validate our methodology through an inter-rater agreement analysis and provide the distribution of attributes across all datasets. These include annotations for the attributes age, sex, skin tone, group, and means of transport for more than 90K people, as well as vehicle type, colour, and car type for over 50K vehicles. Generally, diversity is very low for most attributes, with some groups, such as children, wheelchair users, or personal mobility vehicle users, being extremely underrepresented in the analysed datasets. The study contributes significantly to efforts to consider fairness in the evaluation of perception and prediction systems for AVs. This paper follows reproducibility principles. The annotation tool, scripts and the annotated attributes can be accessed publicly at https://github.com/ec-jrc/humaint_annotator.
Vehicle Trajectory Prediction on Highways Using Bird Eye View Representations and Deep Learning
Jul 04, 2022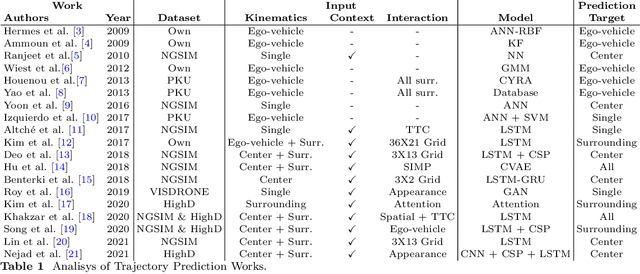
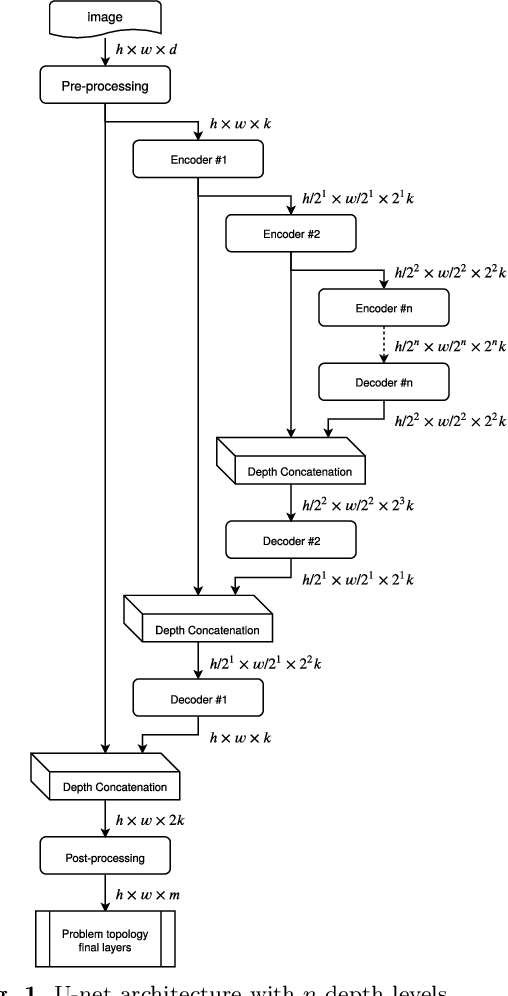


This work presents a novel method for predicting vehicle trajectories in highway scenarios using efficient bird's eye view representations and convolutional neural networks. Vehicle positions, motion histories, road configuration, and vehicle interactions are easily included in the prediction model using basic visual representations. The U-net model has been selected as the prediction kernel to generate future visual representations of the scene using an image-to-image regression approach. A method has been implemented to extract vehicle positions from the generated graphical representations to achieve subpixel resolution. The method has been trained and evaluated using the PREVENTION dataset, an on-board sensor dataset. Different network configurations and scene representations have been evaluated. This study found that U-net with 6 depth levels using a linear terminal layer and a Gaussian representation of the vehicles is the best performing configuration. The use of lane markings was found to produce no improvement in prediction performance. The average prediction error is 0.47 and 0.38 meters and the final prediction error is 0.76 and 0.53 meters for longitudinal and lateral coordinates, respectively, for a predicted trajectory length of 2.0 seconds. The prediction error is up to 50% lower compared to the baseline method.
WiFiNet: WiFi-based indoor localisation using CNNs
Apr 14, 2021
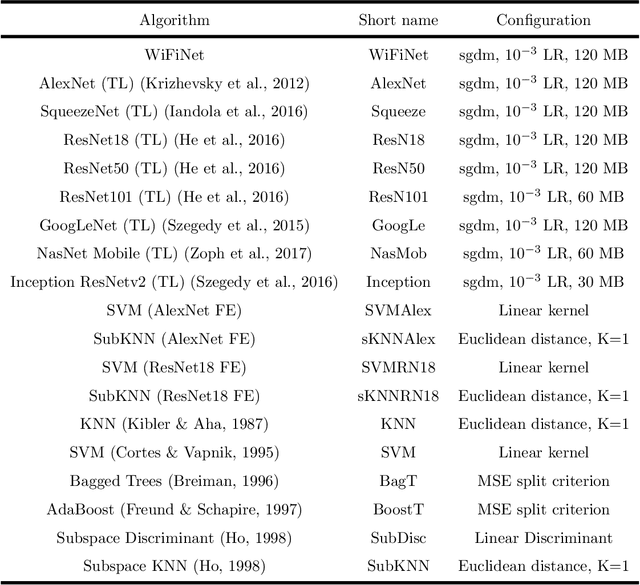
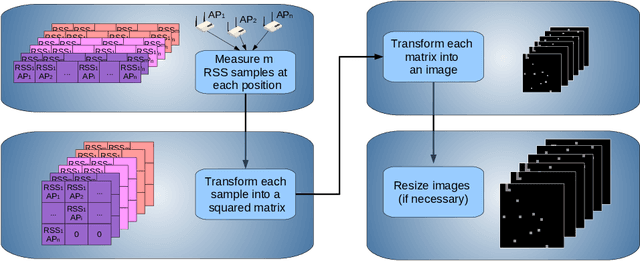

Different technologies have been proposed to provide indoor localisation: magnetic field, bluetooth , WiFi, etc. Among them, WiFi is the one with the highest availability and highest accuracy. This fact allows for an ubiquitous accurate localisation available for almost any environment and any device. However, WiFi-based localisation is still an open problem. In this article, we propose a new WiFi-based indoor localisation system that takes advantage of the great ability of Convolutional Neural Networks in classification problems. Three different approaches were used to achieve this goal: a custom architecture called WiFiNet designed and trained specifically to solve this problem and the most popular pre-trained networks using both transfer learning and feature extraction. Results indicate that WiFiNet is as a great approach for indoor localisation in a medium-sized environment (30 positions and 113 access points) as it reduces the mean localisation error (33%) and the processing time when compared with state-of-the-art WiFi indoor localisation algorithms such as SVM.
RNN-based Pedestrian Crossing Prediction using Activity and Pose-related Features
Aug 26, 2020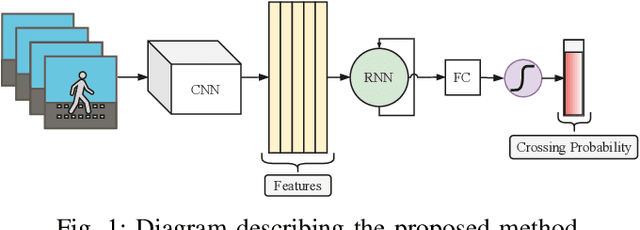
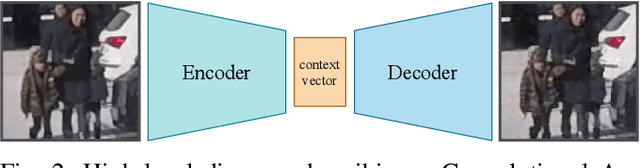

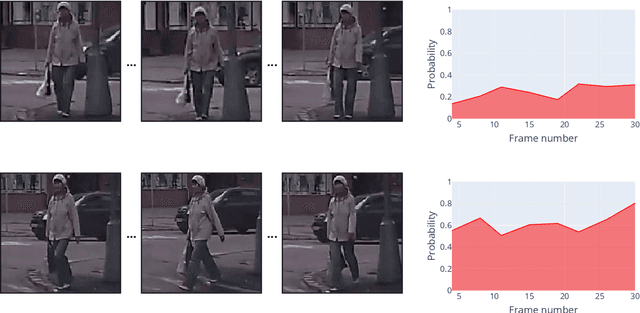
Pedestrian crossing prediction is a crucial task for autonomous driving. Numerous studies show that an early estimation of the pedestrian's intention can decrease or even avoid a high percentage of accidents. In this paper, different variations of a deep learning system are proposed to attempt to solve this problem. The proposed models are composed of two parts: a CNN-based feature extractor and an RNN module. All the models were trained and tested on the JAAD dataset. The results obtained indicate that the choice of the features extraction method, the inclusion of additional variables such as pedestrian gaze direction and discrete orientation, and the chosen RNN type have a significant impact on the final performance.
Pedestrian Path, Pose and Intention Prediction through Gaussian Process Dynamical Models and Pedestrian Activity Recognition
Apr 30, 2020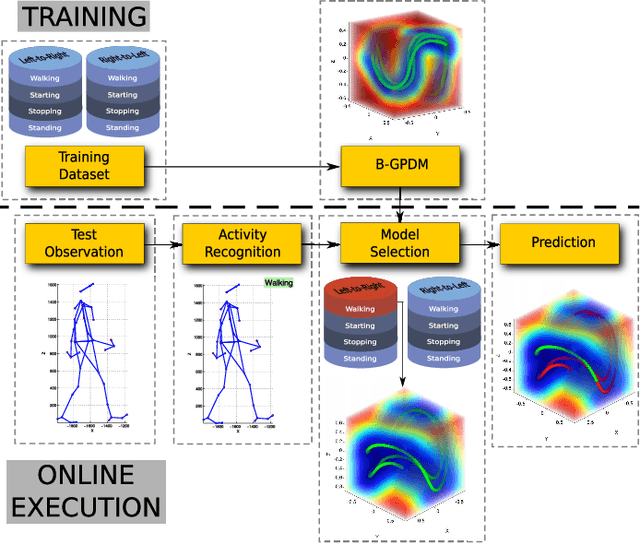
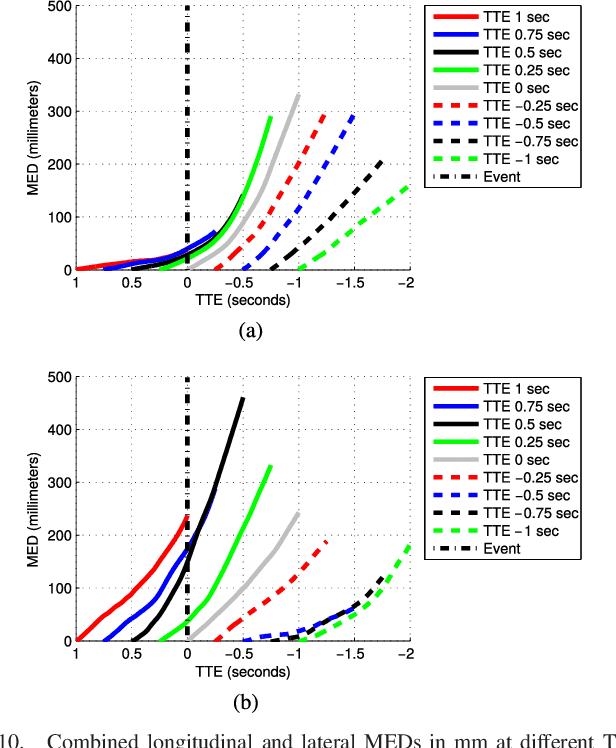
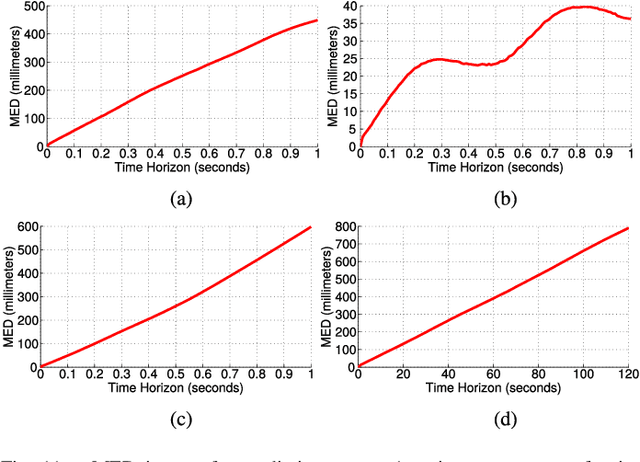
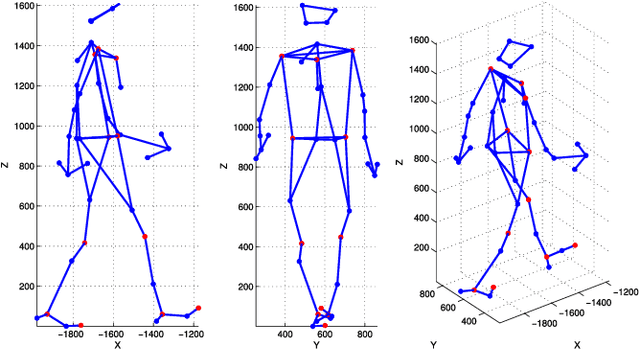
According to several reports published by worldwide organisations, thousands of pedestrians die in road accidents every year. Due to this fact, vehicular technologies have been evolving with the intent of reducing these fatalities. This evolution has not finished yet since, for instance, the predictions of pedestrian paths could improve the current Automatic Emergency Braking Systems (AEBS). For this reason, this paper proposes a method to predict future pedestrian paths, poses and intentions up to 1s in advance. This method is based on Balanced Gaussian Process Dynamical Models (B-GPDMs), which reduce the 3D time-related information extracted from keypoints or joints placed along pedestrian bodies into low-dimensional spaces. The B-GPDM is also capable of inferring future latent positions and reconstruct their associated observations. However, learning a generic model for all kind of pedestrian activities normally provides less ccurate predictions. For this reason, the proposed method obtains multiple models of four types of activity, i.e. walking, stopping, starting and standing, and selects the most similar model to estimate future pedestrian states. This method detects starting activities 125ms after the gait initiation with an accuracy of 80% and recognises stopping intentions 58.33ms before the event with an accuracy of 70%. Concerning the path prediction, the mean error for stopping activities at a Time-To-Event (TTE) of 1s is 238.01mm and, for starting actions, the mean error at a TTE of 0s is 331.93mm.