 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-like Semantic Navigation for Autonomous Driving using Knowledge Representation and Large Language Models
May 22, 2025Achieving full automation in self-driving vehicles remains a challenge, especially in dynamic urban environments where navigation requires real-time adaptability. Existing systems struggle to handle navigation plans when faced with unpredictable changes in road layouts, spontaneous detours, or missing map data, due to their heavy reliance on predefined cartographic information. In this work, we explore the use of Large Language Models to generate Answer Set Programming rules by translating informal navigation instructions into structured, logic-based reasoning. ASP provides non-monotonic reasoning, allowing autonomous vehicles to adapt to evolving scenarios without relying on predefined maps. We present an experimental evaluation in which LLMs generate ASP constraints that encode real-world urban driving logic into a formal knowledge representation. By automating the translation of informal navigation instructions into logical rules, our method improves adaptability and explainability in autonomous navigation. Results show that LLM-driven ASP rule generation supports semantic-based decision-making, offering an explainable framework for dynamic navigation planning that aligns closely with how humans communicate navigational intent.
Cross-cultural analysis of pedestrian group behaviour influence on crossing decisions in interactions with autonomous vehicles
Aug 06, 2024Understanding cultural backgrounds is crucial for the seamless integration of autonomous driving into daily life as it ensures that systems are attuned to diverse societal norms and behaviours, enhancing acceptance and safety in varied cultural contexts. In this work, we investigate the impact of co-located pedestrians on crossing behaviour, considering cultural and situational factors. To accomplish this, a full-scale virtual reality (VR) environment was created in the CARLA simulator, enabling the identical experiment to be replicated in both Spain and Australia. Participants (N=30) attempted to cross the road at an urban crosswalk alongside other pedestrians exhibiting conservative to more daring behaviours, while an autonomous vehicle (AV) approached with different driving styles. For the analysis of interactions, we utilized questionnaires and direct measures of the moment when participants entered the lane. Our findings indicate that pedestrians tend to cross the same traffic gap together, even though reckless behaviour by the group reduces confidence and makes the situation perceived as more complex. Australian participants were willing to take fewer risks than Spanish participants, adopting more cautious behaviour when it was uncertain whether the AV would yield.
Behavioural gap assessment of human-vehicle interaction in real and virtual reality-based scenarios in autonomous driving
Jul 04, 2024In the field of autonomous driving research, the use of immersive virtual reality (VR) techniques is widespread to enable a variety of studies under safe and controlled conditions. However, this methodology is only valid and consistent if the conduct of participants in the simulated setting mirrors their actions in an actual environment. In this paper, we present a first and innovative approach to evaluating what we term the behavioural gap, a concept that captures the disparity in a participant's conduct when engaging in a VR experiment compared to an equivalent real-world situation. To this end, we developed a digital twin of a pre-existed crosswalk and carried out a field experiment (N=18) to investigate pedestrian-autonomous vehicle interaction in both real and simulated driving conditions. In the experiment, the pedestrian attempts to cross the road in the presence of different driving styles and an external Human-Machine Interface (eHMI). By combining survey-based and behavioural analysis methodologies, we develop a quantitative approach to empirically assess the behavioural gap, as a mechanism to validate data obtained from real subjects interacting in a simulated VR-based environment. Results show that participants are more cautious and curious in VR, affecting their speed and decisions, and that VR interfaces significantly influence their actions.
RAG-based Explainable Prediction of Road Users Behaviors for Automated Driving using Knowledge Graphs and Large Language Models
May 01, 2024



Prediction of road users' behaviors in the context of autonomous driving has gained considerable attention by the scientific community in the last years. Most works focus on predicting behaviors based on kinematic information alone, a simplification of the reality since road users are humans, and as such they are highly influenced by their surrounding context. In addition, a large plethora of research works rely on powerful Deep Learning techniques, which exhibit high performance metrics in prediction tasks but may lack the ability to fully understand and exploit the contextual semantic information contained in the road scene, not to mention their inability to provide explainable predictions that can be understood by humans. In this work, we propose an explainable road users' behavior prediction system that integrates the reasoning abilities of Knowledge Graphs (KG) and the expressiveness capabilities of Large Language Models (LLM) by using Retrieval Augmented Generation (RAG) techniques. For that purpose, Knowledge Graph Embeddings (KGE) and Bayesian inference are combined to allow the deployment of a fully inductive reasoning system that enables the issuing of predictions that rely on legacy information contained in the graph as well as on current evidence gathered in real time by onboard sensors. Two use cases have been implemented following the proposed approach: 1) Prediction of pedestrians' crossing actions; 2) Prediction of lane change maneuvers. In both cases, the performance attained surpasses the current state of the art in terms of anticipation and F1-score, showing a promising avenue for future research in this field.
Pedestrian and Passenger Interaction with Autonomous Vehicles: Field Study in a Crosswalk Scenario
Dec 11, 2023This study presents the outcomes of empirical investigations pertaining to human-vehicle interactions involving an autonomous vehicle equipped with both internal and external Human Machine Interfaces (HMIs) within a crosswalk scenario. The internal and external HMIs were integrated with implicit communication techniques, incorporating a combination of gentle and aggressive braking maneuvers within the crosswalk. Data were collected through a combination of questionnaires and quantifiable metrics, including pedestrian decision to cross related to the vehicle distance and speed. The questionnaire responses reveal that pedestrians experience enhanced safety perceptions when the external HMI and gentle braking maneuvers are used in tandem. In contrast, the measured variables demonstrate that the external HMI proves effective when complemented by the gentle braking maneuver. Furthermore, the questionnaire results highlight that the internal HMI enhances passenger confidence only when paired with the aggressive braking maneuver.
Digital twin in virtual reality for human-vehicle interactions in the context of autonomous driving
Mar 20, 2023The traditional simulation methods present some limitations, such as the reality gap between simulated experiences and real-world performance. In the field of autonomous driving research, we propose the handling of an immersive virtual reality system for pedestrians to include in simulations real behaviors of agents that interact with the simulated environment in real time, to improve the quality of the virtual-world data and reduce the gap. In this paper we employ a digital twin to replicate a study on communication interfaces between autonomous vehicles and pedestrians, generating an equivalent virtual scenario to compare the results and establish qualitative and quantitative measurements of the discrepancy. The goal is to evaluate the effectiveness and acceptability of implicit and explicit forms of communication in both scenarios and to verify that the behavior carried out by the pedestrian inside the simulator through a virtual reality interface is directly comparable with their role performed in a real traffic situation.
Towards Trustworthy Multi-Modal Motion Prediction: Evaluation and Interpretability
Oct 28, 2022



Predicting the motion of other road agents enables autonomous vehicles to perform safe and efficient path planning. This task is very complex, as the behaviour of road agents depends on many factors and the number of possible future trajectories can be considerable (multi-modal). Most approaches proposed to address multi-modal motion prediction are based on complex machine learning systems that have limited interpretability. Moreover, the metrics used in current benchmarks do not evaluate all aspects of the problem, such as the diversity and admissibility of the output. In this work, we aim to advance towards the design of trustworthy motion prediction systems, based on some of the requirements for the design of Trustworthy Artificial Intelligence. We focus on evaluation criteria, robustness, and interpretability of outputs. First, we comprehensively analyse the evaluation metrics, identify the main gaps of current benchmarks, and propose a new holistic evaluation framework. In addition, we formulate a method for the assessment of spatial and temporal robustness by simulating noise in the perception system. We propose an intent prediction layer that can be attached to multi-modal motion prediction models to enhance the interpretability of the outputs and generate more balanced results in the proposed evaluation framework. Finally, the interpretability of the outputs is assessed by means of a survey that explores different elements in the visualization of the multi-modal trajectories and intentions.
Vehicle Trajectory Prediction on Highways Using Bird Eye View Representations and Deep Learning
Jul 04, 2022
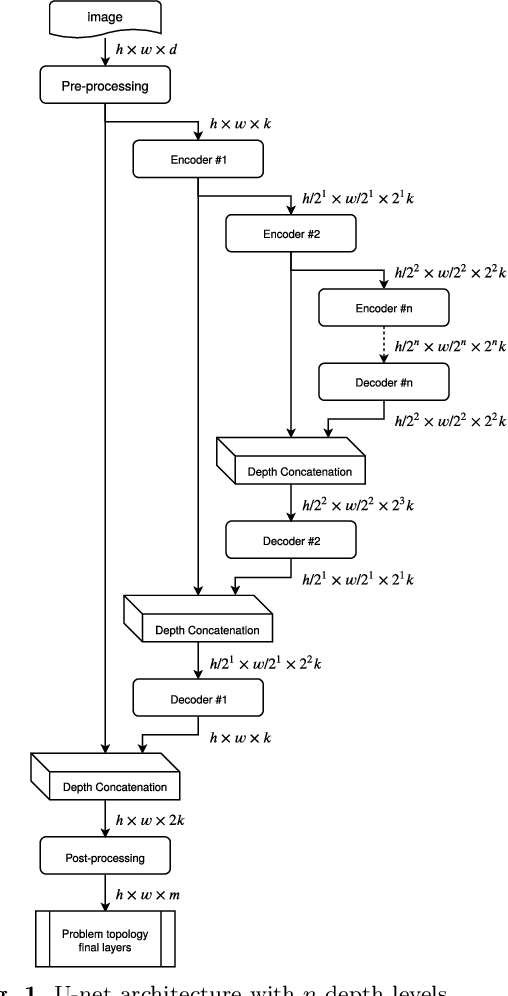


This work presents a novel method for predicting vehicle trajectories in highway scenarios using efficient bird's eye view representations and convolutional neural networks. Vehicle positions, motion histories, road configuration, and vehicle interactions are easily included in the prediction model using basic visual representations. The U-net model has been selected as the prediction kernel to generate future visual representations of the scene using an image-to-image regression approach. A method has been implemented to extract vehicle positions from the generated graphical representations to achieve subpixel resolution. The method has been trained and evaluated using the PREVENTION dataset, an on-board sensor dataset. Different network configurations and scene representations have been evaluated. This study found that U-net with 6 depth levels using a linear terminal layer and a Gaussian representation of the vehicles is the best performing configuration. The use of lane markings was found to produce no improvement in prediction performance. The average prediction error is 0.47 and 0.38 meters and the final prediction error is 0.76 and 0.53 meters for longitudinal and lateral coordinates, respectively, for a predicted trajectory length of 2.0 seconds. The prediction error is up to 50% lower compared to the baseline method.
Insertion of real agents behaviors in CARLA autonomous driving simulator
Jun 01, 2022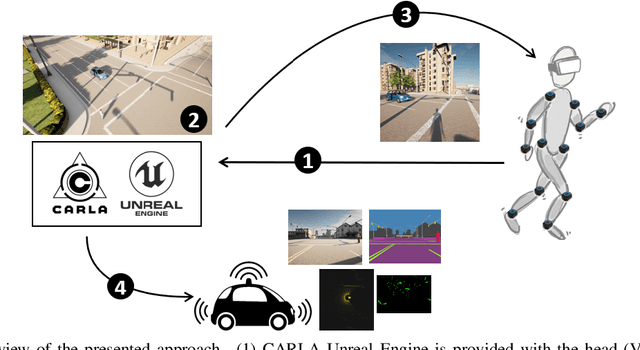
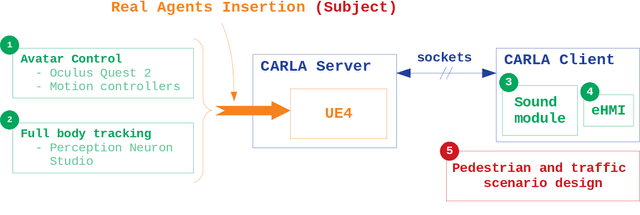

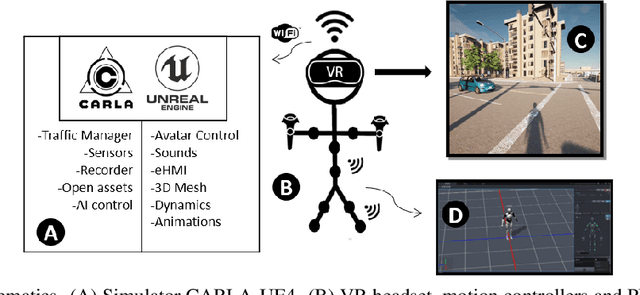
The role of simulation in autonomous driving is becoming increasingly important due to the need for rapid prototyping and extensive testing. The use of physics-based simulation involves multiple benefits and advantages at a reasonable cost while eliminating risks to prototypes, drivers and vulnerable road users. However, there are two main limitations. First, the well-known reality gap which refers to the discrepancy between reality and simulation that prevents simulated autonomous driving experience from enabling effective real-world performance. Second, the lack of empirical knowledge about the behavior of real agents, including backup drivers or passengers and other road users such as vehicles, pedestrians or cyclists. Agent simulation is usually pre-programmed deterministically, randomized probabilistically or generated based on real data, but it does not represent behaviors from real agents interacting with the specific simulated scenario. In this paper we present a preliminary framework to enable real-time interaction between real agents and the simulated environment (including autonomous vehicles) and generate synthetic sequences from simulated sensor data from multiple views that can be used for training predictive systems that rely on behavioral models. Our approach integrates immersive virtual reality and human motion capture systems with the CARLA simulator for autonomous driving. We describe the proposed hardware and software architecture, and discuss about the so-called behavioural gap or presence. We present preliminary, but promising, results that support the potential of this methodology and discuss about future steps.
Model Guided Road Intersection Classification
Apr 26, 2021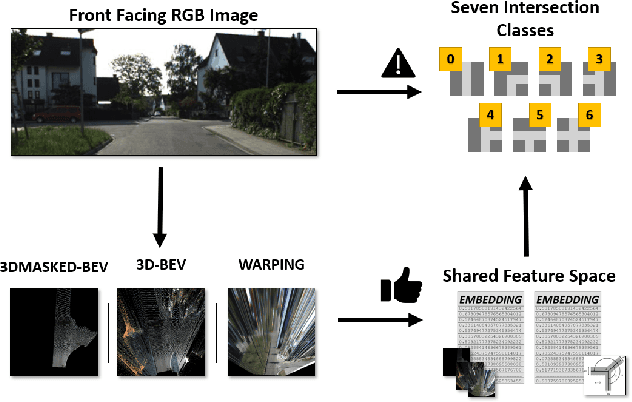
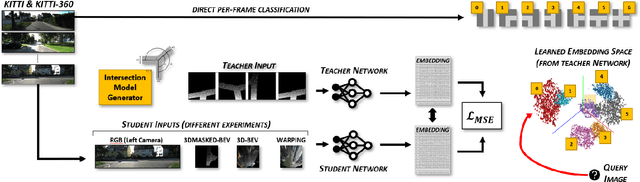
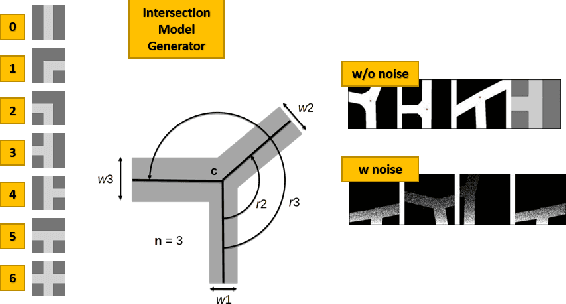
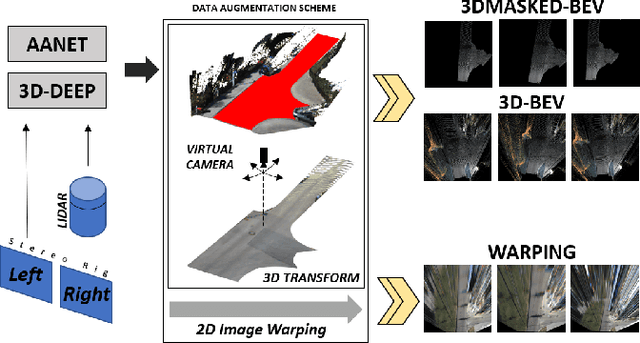
Understanding complex scenarios from in-vehicle cameras is essential for safely operating autonomous driving systems in densely populated areas. Among these, intersection areas are one of the most critical as they concentrate a considerable number of traffic accidents and fatalities. Detecting and understanding the scene configuration of these usually crowded areas is then of extreme importance for both autonomous vehicles and modern ADAS aimed at preventing road crashes and increasing the safety of vulnerable road users. This work investigates inter-section classification from RGB images using well-consolidate neural network approaches along with a method to enhance the results based on the teacher/student training paradigm. An extensive experimental activity aimed at identifying the best input configuration and evaluating different network parameters on both the well-known KITTI dataset and the new KITTI-360 sequences shows that our method outperforms current state-of-the-art approaches on a per-frame basis and prove the effectiveness of the proposed learning scheme.