 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRESCORE: LLM-Driven Simulation Recovery in Control Systems Research Papers
Apr 06, 2026Reconstructing numerical simulations from control systems research papers is often hindered by underspecified parameters and ambiguous implementation details. We define the task of Paper to Simulation Recoverability, the ability of an automated system to generate executable code that faithfully reproduces a paper's results. We curate a benchmark of 500 papers from the IEEE Conference on Decision and Control (CDC) and propose RESCORE, a three component LLM agentic framework, Analyzer, Coder, and Verifier. RESCORE uses iterative execution feedback and visual comparison to improve reconstruction fidelity. Our method successfully recovers task coherent simulations for 40.7% of benchmark instances, outperforming single pass generation. Notably, the RESCORE automated pipeline achieves an estimated 10X speedup over manual human replication, drastically cutting the time and effort required to verify published control methodologies. We will release our benchmark and agents to foster community progress in automated research replication.
MapleGrasp: Mask-guided Feature Pooling for Language-driven Efficient Robotic Grasping
Jun 06, 2025Robotic manipulation of unseen objects via natural language commands remains challenging. Language driven robotic grasping (LDRG) predicts stable grasp poses from natural language queries and RGB-D images. Here we introduce Mask-guided feature pooling, a lightweight enhancement to existing LDRG methods. Our approach employs a two-stage training strategy: first, a vision-language model generates feature maps from CLIP-fused embeddings, which are upsampled and weighted by text embeddings to produce segmentation masks. Next, the decoder generates separate feature maps for grasp prediction, pooling only token features within these masked regions to efficiently predict grasp poses. This targeted pooling approach reduces computational complexity, accelerating both training and inference. Incorporating mask pooling results in a 12% improvement over prior approaches on the OCID-VLG benchmark. Furthermore, we introduce RefGraspNet, an open-source dataset eight times larger than existing alternatives, significantly enhancing model generalization for open-vocabulary grasping. By extending 2D grasp predictions to 3D via depth mapping and inverse kinematics, our modular method achieves performance comparable to recent Vision-Language-Action (VLA) models on the LIBERO simulation benchmark, with improved generalization across different task suites. Real-world experiments on a 7 DoF Franka robotic arm demonstrate a 57% success rate with unseen objects, surpassing competitive baselines by 7%. Code will be released post publication.
3D CAVLA: Leveraging Depth and 3D Context to Generalize Vision Language Action Models for Unseen Tasks
May 09, 2025Robotic manipulation in 3D requires learning an $N$ degree-of-freedom joint space trajectory of a robot manipulator. Robots must possess semantic and visual perception abilities to transform real-world mappings of their workspace into the low-level control necessary for object manipulation. Recent work has demonstrated the capabilities of fine-tuning large Vision-Language Models (VLMs) to learn the mapping between RGB images, language instructions, and joint space control. These models typically take as input RGB images of the workspace and language instructions, and are trained on large datasets of teleoperated robot demonstrations. In this work, we explore methods to improve the scene context awareness of a popular recent Vision-Language-Action model by integrating chain-of-thought reasoning, depth perception, and task-oriented region of interest detection. Our experiments in the LIBERO simulation environment show that our proposed model, 3D-CAVLA, improves the success rate across various LIBERO task suites, achieving an average success rate of 98.1$\%$. We also evaluate the zero-shot capabilities of our method, demonstrating that 3D scene awareness leads to robust learning and adaptation for completely unseen tasks. 3D-CAVLA achieves an absolute improvement of 8.8$\%$ on unseen tasks. We will open-source our code and the unseen tasks dataset to promote community-driven research here: https://3d-cavla.github.io
HiFi-CS: Towards Open Vocabulary Visual Grounding For Robotic Grasping Using Vision-Language Models
Sep 16, 2024



Robots interacting with humans through natural language can unlock numerous applications such as Referring Grasp Synthesis (RGS). Given a text query, RGS determines a stable grasp pose to manipulate the referred object in the robot's workspace. RGS comprises two steps: visual grounding and grasp pose estimation. Recent studies leverage powerful Vision-Language Models (VLMs) for visually grounding free-flowing natural language in real-world robotic execution. However, comparisons in complex, cluttered environments with multiple instances of the same object are lacking. This paper introduces HiFi-CS, featuring hierarchical application of Featurewise Linear Modulation (FiLM) to fuse image and text embeddings, enhancing visual grounding for complex attribute rich text queries encountered in robotic grasping. Visual grounding associates an object in 2D/3D space with natural language input and is studied in two scenarios: Closed and Open Vocabulary. HiFi-CS features a lightweight decoder combined with a frozen VLM and outperforms competitive baselines in closed vocabulary settings while being 100x smaller in size. Our model can effectively guide open-set object detectors like GroundedSAM to enhance open-vocabulary performance. We validate our approach through real-world RGS experiments using a 7-DOF robotic arm, achieving 90.33\% visual grounding accuracy in 15 tabletop scenes. We include our codebase in the supplementary material.
Grounding LLMs For Robot Task Planning Using Closed-loop State Feedback
Feb 13, 2024Robotic planning algorithms direct agents to perform actions within diverse environments to accomplish a task. Large Language Models (LLMs) like PaLM 2, GPT-3.5, and GPT-4 have revolutionized this domain, using their embedded real-world knowledge to tackle complex tasks involving multiple agents and objects. This paper introduces an innovative planning algorithm that integrates LLMs into the robotics context, enhancing task-focused execution and success rates. Key to our algorithm is a closed-loop feedback which provides real-time environmental states and error messages, crucial for refining plans when discrepancies arise. The algorithm draws inspiration from the human neural system, emulating its brain-body architecture by dividing planning across two LLMs in a structured, hierarchical fashion. Our method not only surpasses baselines within the VirtualHome Environment, registering a notable 35% average increase in task-oriented success rates, but achieves an impressive execution score of 85%, approaching the human-level benchmark of 94%. Moreover, effectiveness of the algorithm in real robot scenarios is shown using a realistic physics simulator and the Franka Research 3 Arm.
DISCO: A Large Scale Human Annotated Corpus for Disfluency Correction in Indo-European Languages
Oct 25, 2023


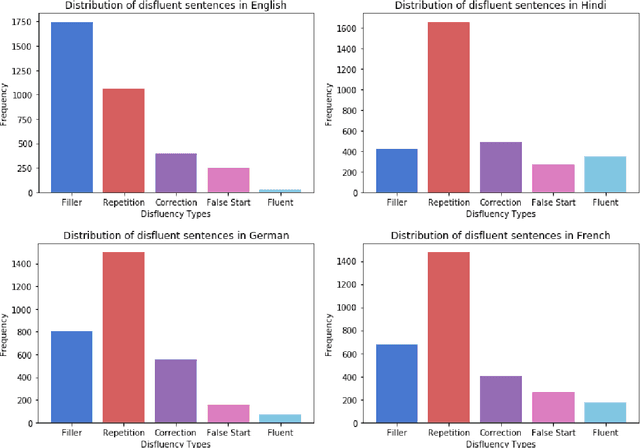
Disfluency correction (DC) is the process of removing disfluent elements like fillers, repetitions and corrections from spoken utterances to create readable and interpretable text. DC is a vital post-processing step applied to Automatic Speech Recognition (ASR) outputs, before subsequent processing by downstream language understanding tasks. Existing DC research has primarily focused on English due to the unavailability of large-scale open-source datasets. Towards the goal of multilingual disfluency correction, we present a high-quality human-annotated DC corpus covering four important Indo-European languages: English, Hindi, German and French. We provide extensive analysis of results of state-of-the-art DC models across all four languages obtaining F1 scores of 97.55 (English), 94.29 (Hindi), 95.89 (German) and 92.97 (French). To demonstrate the benefits of DC on downstream tasks, we show that DC leads to 5.65 points increase in BLEU scores on average when used in conjunction with a state-of-the-art Machine Translation (MT) system. We release code to run our experiments along with our annotated dataset here.
Adversarial Training For Low-Resource Disfluency Correction
Jun 10, 2023
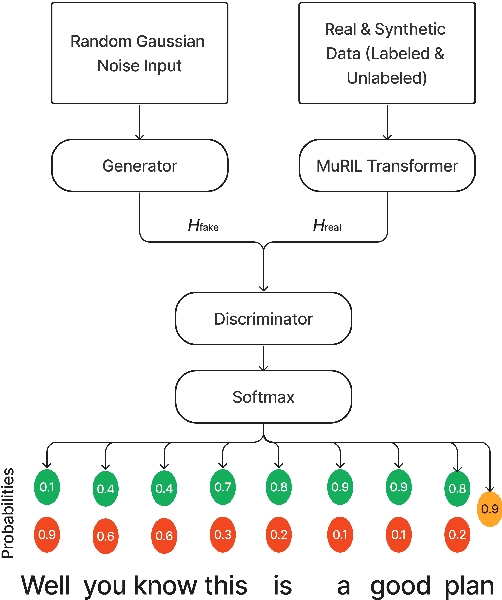

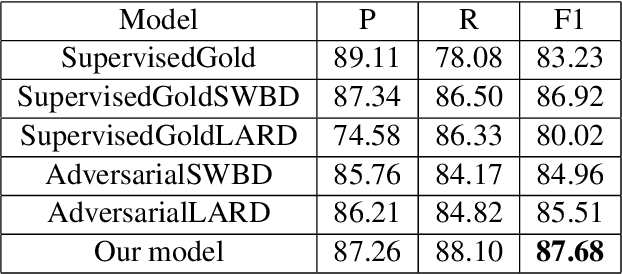
Disfluencies commonly occur in conversational speech. Speech with disfluencies can result in noisy Automatic Speech Recognition (ASR) transcripts, which affects downstream tasks like machine translation. In this paper, we propose an adversarially-trained sequence-tagging model for Disfluency Correction (DC) that utilizes a small amount of labeled real disfluent data in conjunction with a large amount of unlabeled data. We show the benefit of our proposed technique, which crucially depends on synthetically generated disfluent data, by evaluating it for DC in three Indian languages- Bengali, Hindi, and Marathi (all from the Indo-Aryan family). Our technique also performs well in removing stuttering disfluencies in ASR transcripts introduced by speech impairments. We achieve an average 6.15 points improvement in F1-score over competitive baselines across all three languages mentioned. To the best of our knowledge, we are the first to utilize adversarial training for DC and use it to correct stuttering disfluencies in English, establishing a new benchmark for this task.
DisfluencyFixer: A tool to enhance Language Learning through Speech To Speech Disfluency Correction
May 26, 2023

Conversational speech often consists of deviations from the speech plan, producing disfluent utterances that affect downstream NLP tasks. Removing these disfluencies is necessary to create fluent and coherent speech. This paper presents DisfluencyFixer, a tool that performs speech-to-speech disfluency correction in English and Hindi using a pipeline of Automatic Speech Recognition (ASR), Disfluency Correction (DC) and Text-To-Speech (TTS) models. Our proposed system removes disfluencies from input speech and returns fluent speech as output along with its transcript, disfluency type and total disfluency count in source utterance, providing a one-stop destination for language learners to improve the fluency of their speech. We evaluate the performance of our tool subjectively and receive scores of 4.26, 4.29 and 4.42 out of 5 in ASR performance, DC performance and ease-of-use of the system. Our tool can be accessed openly at the following link.
VAKTA-SETU: A Speech-to-Speech Machine Translation Service in Select Indic Languages
May 21, 2023



In this work, we present our deployment-ready Speech-to-Speech Machine Translation (SSMT) system for English-Hindi, English-Marathi, and Hindi-Marathi language pairs. We develop the SSMT system by cascading Automatic Speech Recognition (ASR), Disfluency Correction (DC), Machine Translation (MT), and Text-to-Speech Synthesis (TTS) models. We discuss the challenges faced during the research and development stage and the scalable deployment of the SSMT system as a publicly accessible web service. On the MT part of the pipeline too, we create a Text-to-Text Machine Translation (TTMT) service in all six translation directions involving English, Hindi, and Marathi. To mitigate data scarcity, we develop a LaBSE-based corpus filtering tool to select high-quality parallel sentences from a noisy pseudo-parallel corpus for training the TTMT system. All the data used for training the SSMT and TTMT systems and the best models are being made publicly available. Users of our system are (a) Govt. of India in the context of its new education policy (NEP), (b) tourists who criss-cross the multilingual landscape of India, (c) Indian Judiciary where a leading cause of the pendency of cases (to the order of 10 million as on date) is the translation of case papers, (d) farmers who need weather and price information and so on. We also share the feedback received from various stakeholders when our SSMT and TTMT systems were demonstrated in large public events.