 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERASE-Net: Efficient Segmentation Networks for Automotive Radar Signals
Sep 26, 2022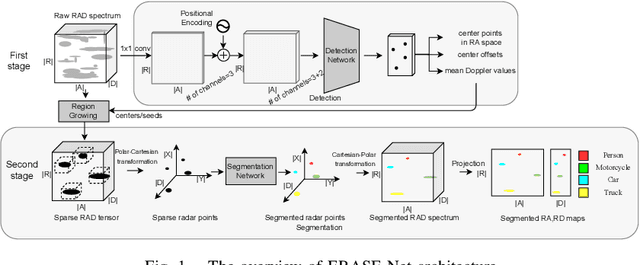


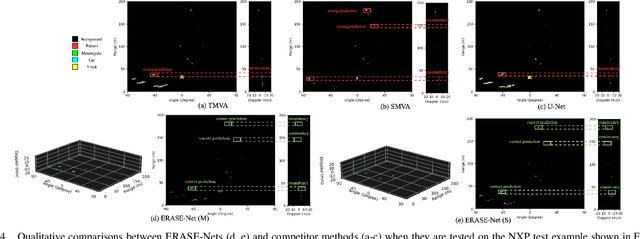
Among various sensors for assisted and autonomous driving systems, automotive radar has been considered as a robust and low-cost solution even in adverse weather or lighting conditions. With the recent development of radar technologies and open-sourced annotated data sets, semantic segmentation with radar signals has become very promising. However, existing methods are either computationally expensive or discard significant amounts of valuable information from raw 3D radar signals by reducing them to 2D planes via averaging. In this work, we introduce ERASE-Net, an Efficient RAdar SEgmentation Network to segment the raw radar signals semantically. The core of our approach is the novel detect-then-segment method for raw radar signals. It first detects the center point of each object, then extracts a compact radar signal representation, and finally performs semantic segmentation. We show that our method can achieve superior performance on radar semantic segmentation task compared to the state-of-the-art (SOTA) technique. Furthermore, our approach requires up to 20x less computational resources. Finally, we show that the proposed ERASE-Net can be compressed by 40% without significant loss in performance, significantly more than the SOTA network, which makes it a more promising candidate for practical automotive applications.
Backdoor Attacks on the DNN Interpretation System
Dec 03, 2020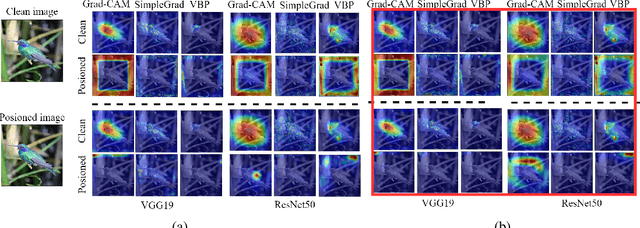
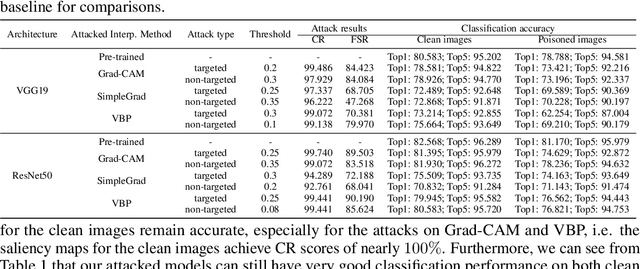
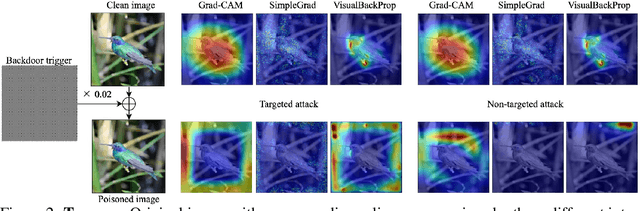
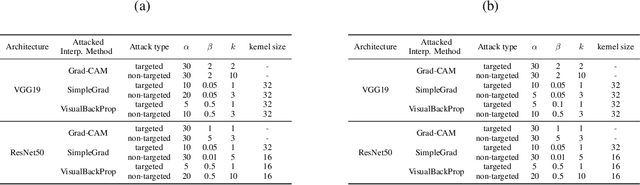
Interpretability is crucial to understand the inner workings of deep neural networks (DNNs) and many interpretation methods generate saliency maps that highlight parts of the input image that contribute the most to the prediction made by the DNN. In this paper we design a backdoor attack that alters the saliency map produced by the network for an input image only with injected trigger that is invisible to the naked eye while maintaining the prediction accuracy. The attack relies on injecting poisoned data with a trigger into the training data set. The saliency maps are incorporated in the penalty term of the objective function that is used to train a deep model and its influence on model training is conditioned upon the presence of a trigger. We design two types of attacks: targeted attack that enforces a specific modification of the saliency map and untargeted attack when the importance scores of the top pixels from the original saliency map are significantly reduced. We perform empirical evaluation of the proposed backdoor attacks on gradient-based and gradient-free interpretation methods for a variety of deep learning architectures. We show that our attacks constitute a serious security threat when deploying deep learning models developed by untrusty sources. Finally, in the Supplement we demonstrate that the proposed methodology can be used in an inverted setting, where the correct saliency map can be obtained only in the presence of a trigger (key), effectively making the interpretation system available only to selected users.
Multi-modal Experts Network for Autonomous Driving
Sep 18, 2020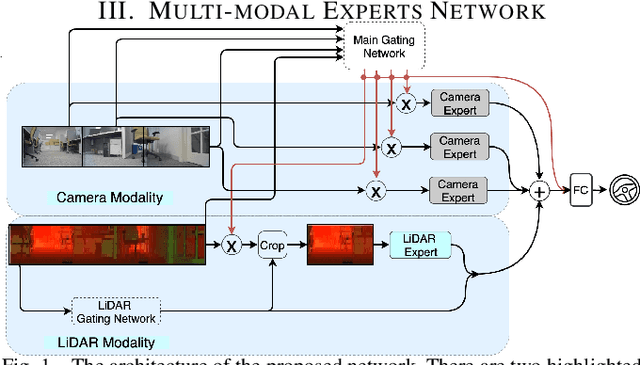
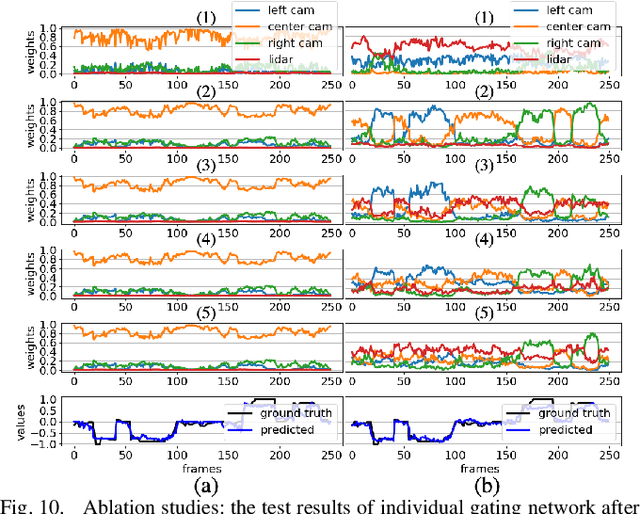
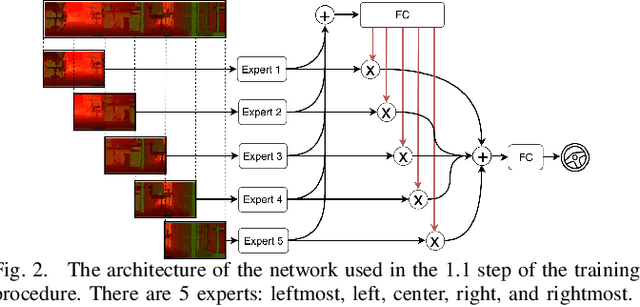

End-to-end learning from sensory data has shown promising results in autonomous driving. While employing many sensors enhances world perception and should lead to more robust and reliable behavior of autonomous vehicles, it is challenging to train and deploy such network and at least two problems are encountered in the considered setting. The first one is the increase of computational complexity with the number of sensing devices. The other is the phenomena of network overfitting to the simplest and most informative input. We address both challenges with a novel, carefully tailored multi-modal experts network architecture and propose a multi-stage training procedure. The network contains a gating mechanism, which selects the most relevant input at each inference time step using a mixed discrete-continuous policy. We demonstrate the plausibility of the proposed approach on our 1/6 scale truck equipped with three cameras and one LiDAR.
* Published at the International Conference on Robotics and Automation (ICRA), 2020