 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackdoor Attacks on the DNN Interpretation System
Paper and Code
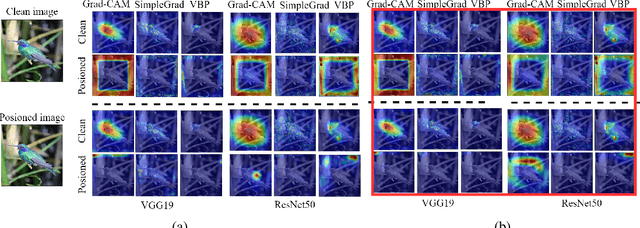
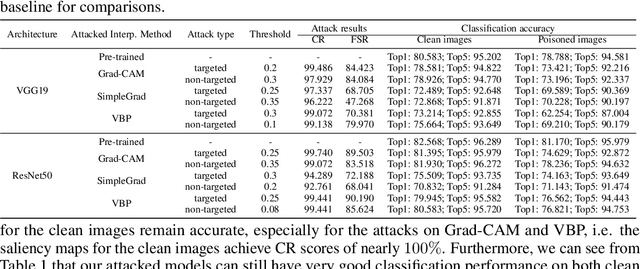
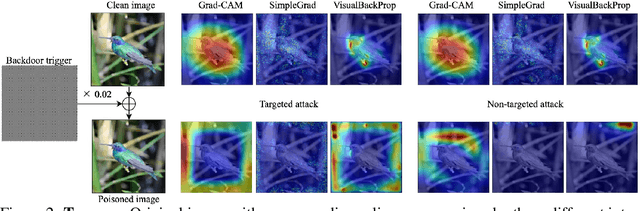
Interpretability is crucial to understand the inner workings of deep neural networks (DNNs) and many interpretation methods generate saliency maps that highlight parts of the input image that contribute the most to the prediction made by the DNN. In this paper we design a backdoor attack that alters the saliency map produced by the network for an input image only with injected trigger that is invisible to the naked eye while maintaining the prediction accuracy. The attack relies on injecting poisoned data with a trigger into the training data set. The saliency maps are incorporated in the penalty term of the objective function that is used to train a deep model and its influence on model training is conditioned upon the presence of a trigger. We design two types of attacks: targeted attack that enforces a specific modification of the saliency map and untargeted attack when the importance scores of the top pixels from the original saliency map are significantly reduced. We perform empirical evaluation of the proposed backdoor attacks on gradient-based and gradient-free interpretation methods for a variety of deep learning architectures. We show that our attacks constitute a serious security threat when deploying deep learning models developed by untrusty sources. Finally, in the Supplement we demonstrate that the proposed methodology can be used in an inverted setting, where the correct saliency map can be obtained only in the presence of a trigger (key), effectively making the interpretation system available only to selected users.