 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Open-set Domain Adaptation by Dual-domain Collaboration
Apr 30, 2019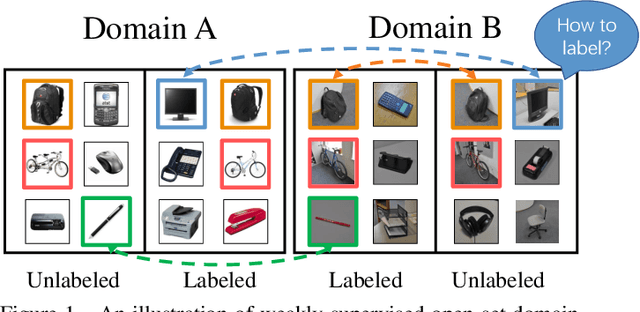
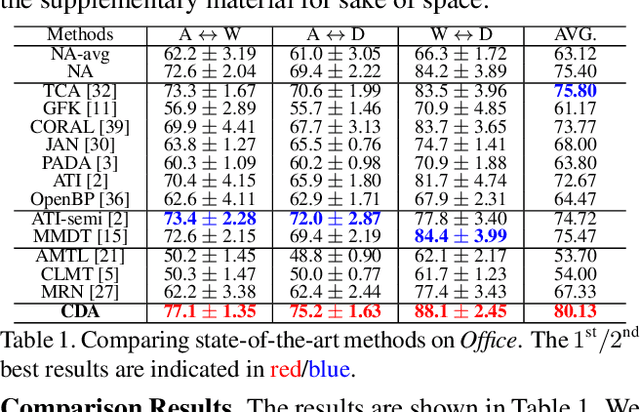
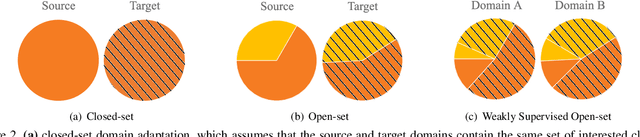

In conventional domain adaptation, a critical assumption is that there exists a fully labeled domain (source) that contains the same label space as another unlabeled or scarcely labeled domain (target). However, in the real world, there often exist application scenarios in which both domains are partially labeled and not all classes are shared between these two domains. Thus, it is meaningful to let partially labeled domains learn from each other to classify all the unlabeled samples in each domain under an open-set setting. We consider this problem as weakly supervised open-set domain adaptation. To address this practical setting, we propose the Collaborative Distribution Alignment (CDA) method, which performs knowledge transfer bilaterally and works collaboratively to classify unlabeled data and identify outlier samples. Extensive experiments on the Office benchmark and an application on person reidentification show that our method achieves state-of-the-art performance.