 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Interpolation with Diffusion Models
Apr 01, 2024We present VIDIM, a generative model for video interpolation, which creates short videos given a start and end frame. In order to achieve high fidelity and generate motions unseen in the input data, VIDIM uses cascaded diffusion models to first generate the target video at low resolution, and then generate the high-resolution video conditioned on the low-resolution generated video. We compare VIDIM to previous state-of-the-art methods on video interpolation, and demonstrate how such works fail in most settings where the underlying motion is complex, nonlinear, or ambiguous while VIDIM can easily handle such cases. We additionally demonstrate how classifier-free guidance on the start and end frame and conditioning the super-resolution model on the original high-resolution frames without additional parameters unlocks high-fidelity results. VIDIM is fast to sample from as it jointly denoises all the frames to be generated, requires less than a billion parameters per diffusion model to produce compelling results, and still enjoys scalability and improved quality at larger parameter counts.
Performance evaluation of deep neural networks for forecasting time-series with multiple structural breaks and high volatility
Nov 14, 2019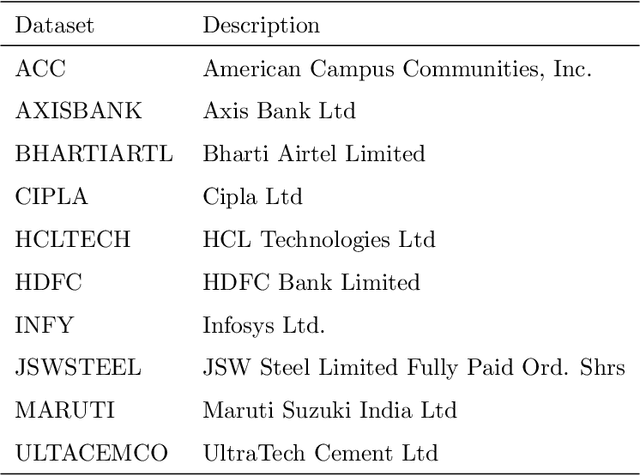
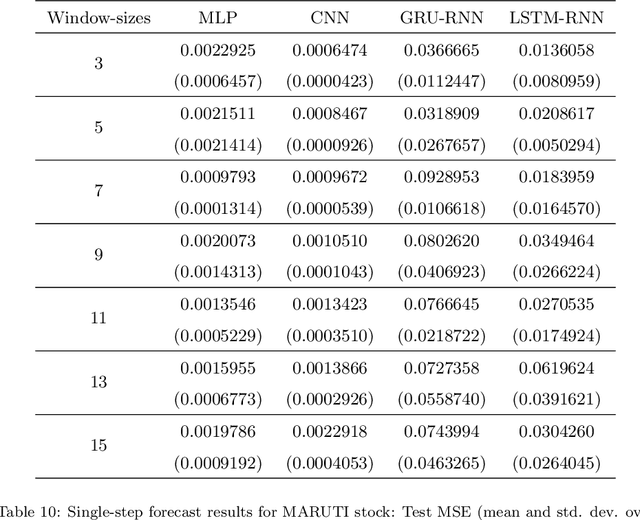
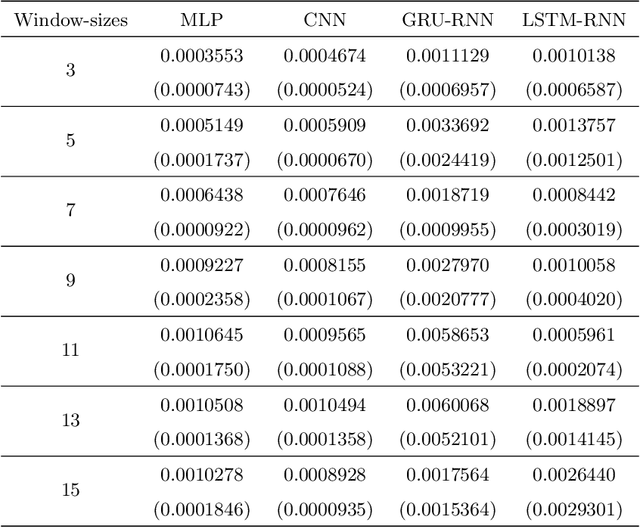
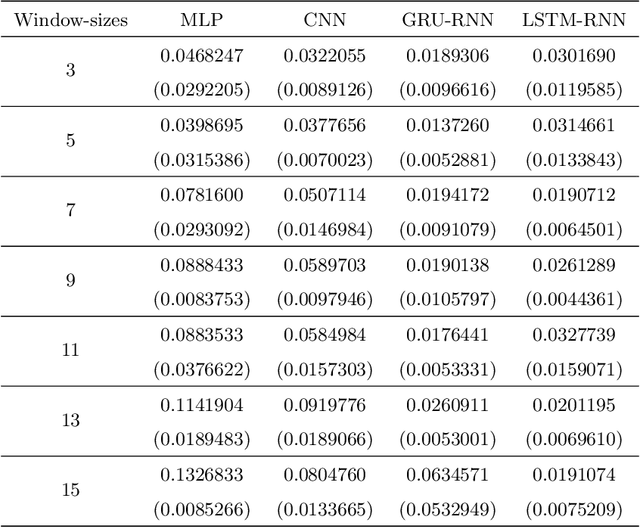
The problem of automatic forecasting of time-series data has been a long-standing challenge for the machine learning and forecasting community. The problem is relatively simple when the series is stationary. However, the majority of the real-world time-series problems have non-stationary characteristics making the understanding of the trend and seasonality very complex. Further, it is assumed that the future response is dependent on the past data and, therefore, can be modeled using a function approximator. Our interest in this paper is to study the applicability of the popular deep neural networks (DNN) comprehensively as function approximators for non-stationary time-series forecasting. We employ the following DNN models: Multi-layer Perceptron (MLP), Convolutional Neural Network (CNN), and RNN with Long-Short Term Memory (LSTM-RNN) and RNN with Gated-Recurrent Unit (GRU-RNN). These powerful DNN methods have been evaluated over popular Indian financial stocks data comprising of five stocks from National Stock Exchange Nifty-50 (NSE-Nifty50), and five stocks from Bombay Stock Exchange 30 (BSE-30). Further, the performance evaluation of these DNNs in terms of their predictive power has been done using two fashions: (1) single-step forecasting, (2) multi-step forecasting. Our extensive simulation experiments on these ten datasets report that the performance of these DNNs for single-step forecasting is pretty convincing as the predictions are found to follow the truely observed values closely. However, we also find that all these DNN models perform miserably in the case of multi-step time-series forecasting, based on the datasets used by us. Consequently, we observe that none of these DNN models are reliable for multi-step time-series forecasting.
Few-Shot Point Cloud Region Annotation with Human in the Loop
Jun 11, 2019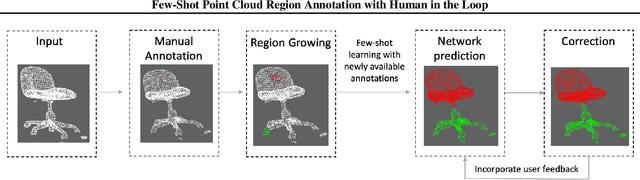
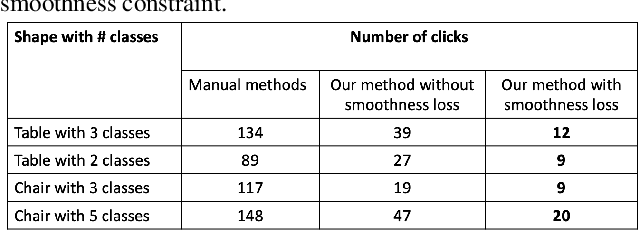

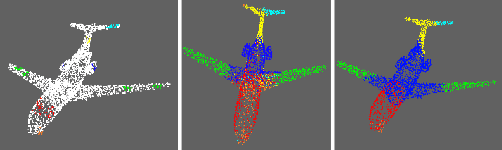
We propose a point cloud annotation framework that employs human-in-loop learning to enable the creation of large point cloud datasets with per-point annotations. Sparse labels from a human annotator are iteratively propagated to generate a full segmentation of the network by fine-tuning a pre-trained model of an allied task via a few-shot learning paradigm. We show that the proposed framework significantly reduces the amount of human interaction needed in annotating point clouds, without sacrificing on the quality of the annotations. Our experiments also suggest the suitability of the framework in annotating large datasets by noting a reduction in human interaction as the number of full annotations completed by the system increases. Finally, we demonstrate the flexibility of the framework to support multiple different annotations of the same point cloud enabling the creation of datasets with different granularities of annotation.
An Amalgamation of Classical and Quantum Machine Learning For the Classification of Adenocarcinoma and Squamous Cell Carcinoma Patients
Oct 29, 2018
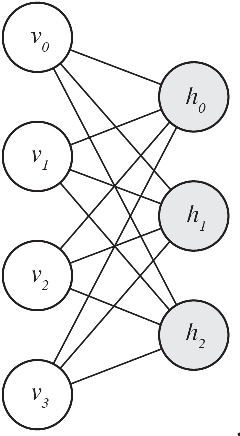
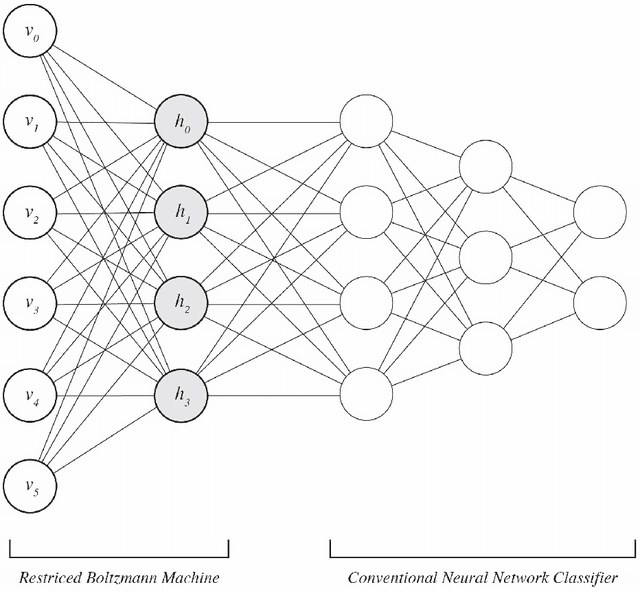
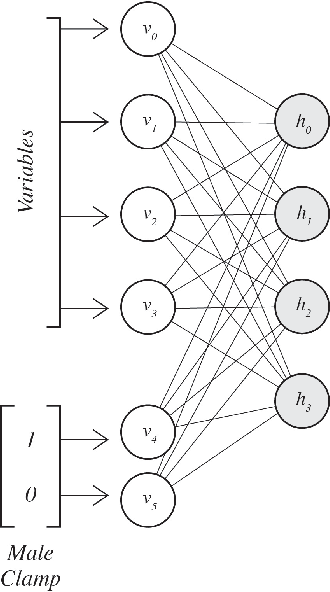
The ability to accurately classify disease subtypes is of vital importance, especially in oncology where this capability could have a life saving impact. Here we report a classification between two subtypes of non-small cell lung cancer, namely Adeno- carcinoma vs Squamous cell carcinoma. The data consists of approximately 20,000 gene expression values for each of 104 patients. The data was curated from [1] [2]. We used an amalgamation of classical and and quantum machine learning models to successfully classify these patients. We utilized feature selection methods based on univariate statistics in addition to XGBoost [3]. A novel and proprietary data representation method developed by one of the authors called QCrush was also used as it was designed to incorporate a maximal amount of information under the size constraints of the D-Wave quantum annealing computer. The machine learning was performed by a Quantum Boltzmann Machine. This paper will report our results, the various classical methods, and the quantum machine learning approach we utilized.
BigHand2.2M Benchmark: Hand Pose Dataset and State of the Art Analysis
Dec 09, 2017
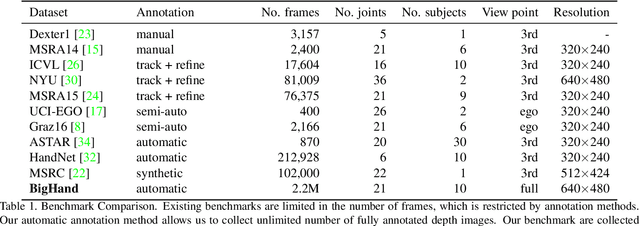
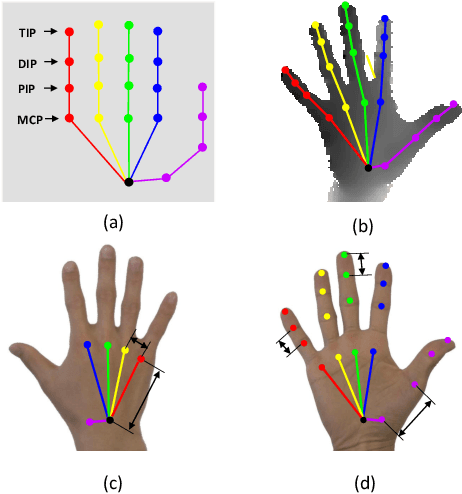

In this paper we introduce a large-scale hand pose dataset, collected using a novel capture method. Existing datasets are either generated synthetically or captured using depth sensors: synthetic datasets exhibit a certain level of appearance difference from real depth images, and real datasets are limited in quantity and coverage, mainly due to the difficulty to annotate them. We propose a tracking system with six 6D magnetic sensors and inverse kinematics to automatically obtain 21-joints hand pose annotations of depth maps captured with minimal restriction on the range of motion. The capture protocol aims to fully cover the natural hand pose space. As shown in embedding plots, the new dataset exhibits a significantly wider and denser range of hand poses compared to existing benchmarks. Current state-of-the-art methods are evaluated on the dataset, and we demonstrate significant improvements in cross-benchmark performance. We also show significant improvements in egocentric hand pose estimation with a CNN trained on the new dataset.