 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Deeply Supervised Visual Descriptors for Dense Monocular Reconstruction
Paper and Code
Nov 16, 2017
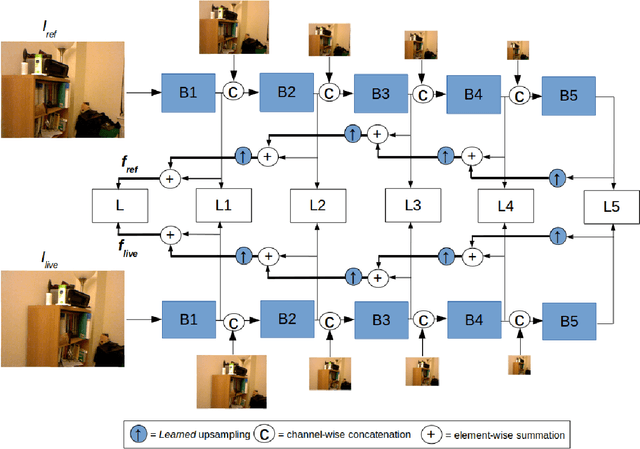


Visual SLAM (Simultaneous Localization and Mapping) methods typically rely on handcrafted visual features or raw RGB values for establishing correspondences between images. These features, while suitable for sparse mapping, often lead to ambiguous matches at texture-less regions when performing dense reconstruction due to the aperture problem. In this work, we explore the use of learned features for the matching task in dense monocular reconstruction. We propose a novel convolutional neural network (CNN) architecture along with a deeply supervised feature learning scheme for pixel-wise regression of visual descriptors from an image which are best suited for dense monocular SLAM. In particular, our learning scheme minimizes a multi-view matching cost-volume loss with respect to the regressed features at multiple stages within the network, for explicitly learning contextual features that are suitable for dense matching between images captured by a moving monocular camera along the epipolar line. We utilize the learned features from our model for depth estimation inside a real-time dense monocular SLAM framework, where photometric error is replaced by our learned descriptor error. Our evaluation on several challenging indoor scenes demonstrate greatly improved accuracy in dense reconstructions of the well celebrated dense SLAM systems like DTAM, without compromising their real-time performance.