 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShapes of Emotions: Multimodal Emotion Recognition in Conversations via Emotion Shifts
Paper and Code
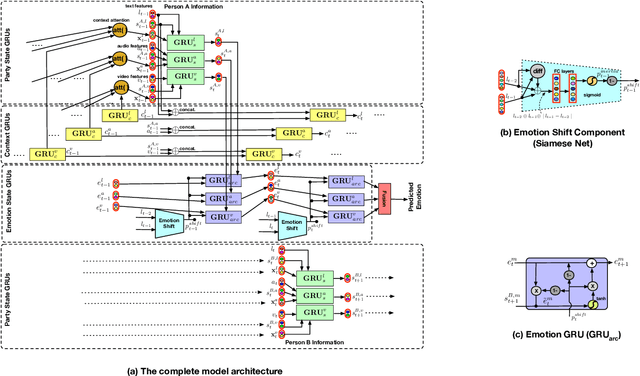
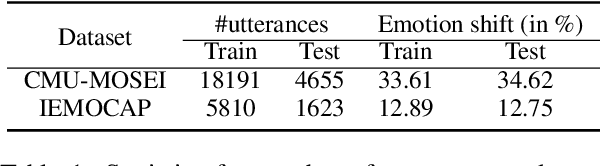
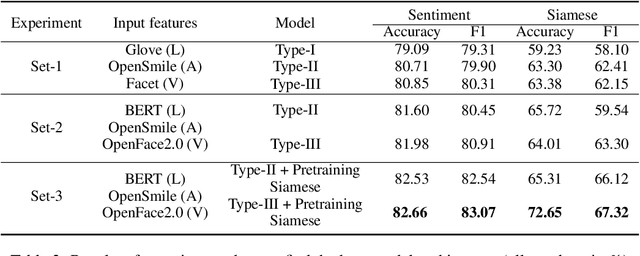
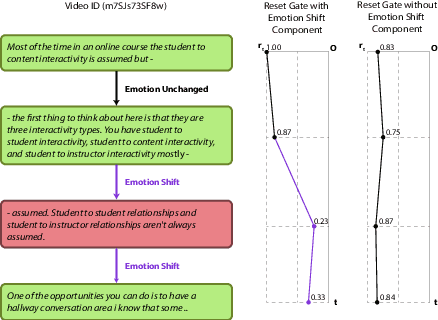
Emotion Recognition in Conversations (ERC) is an important and active research problem. Recent work has shown the benefits of using multiple modalities (e.g., text, audio, and video) for the ERC task. In a conversation, participants tend to maintain a particular emotional state unless some external stimuli evokes a change. There is a continuous ebb and flow of emotions in a conversation. Inspired by this observation, we propose a multimodal ERC model and augment it with an emotion-shift component. The proposed emotion-shift component is modular and can be added to any existing multimodal ERC model (with a few modifications), to improve emotion recognition. We experiment with different variants of the model, and results show that the inclusion of emotion shift signal helps the model to outperform existing multimodal models for ERC and hence showing the state-of-the-art performance on MOSEI and IEMOCAP datasets.