 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverse Reinforcement Learning with Explicit Policy Estimates
Mar 04, 2021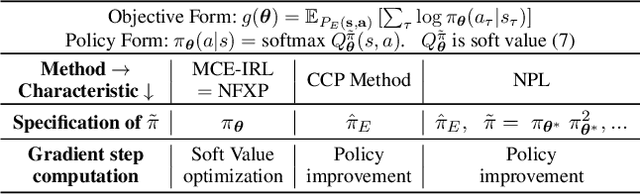


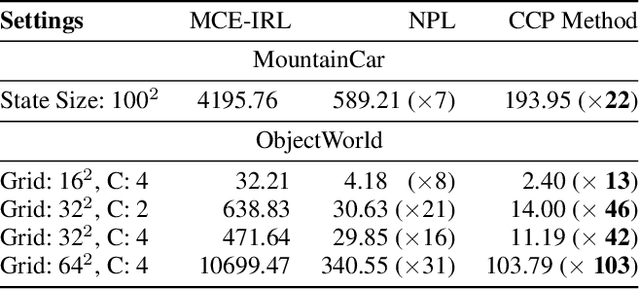
Various methods for solving the inverse reinforcement learning (IRL) problem have been developed independently in machine learning and economics. In particular, the method of Maximum Causal Entropy IRL is based on the perspective of entropy maximization, while related advances in the field of economics instead assume the existence of unobserved action shocks to explain expert behavior (Nested Fixed Point Algorithm, Conditional Choice Probability method, Nested Pseudo-Likelihood Algorithm). In this work, we make previously unknown connections between these related methods from both fields. We achieve this by showing that they all belong to a class of optimization problems, characterized by a common form of the objective, the associated policy and the objective gradient. We demonstrate key computational and algorithmic differences which arise between the methods due to an approximation of the optimal soft value function, and describe how this leads to more efficient algorithms. Using insights which emerge from our study of this class of optimization problems, we identify various problem scenarios and investigate each method's suitability for these problems.
DeepBLE: Generalizing RSSI-based Localization Across Different Devices
Feb 27, 2021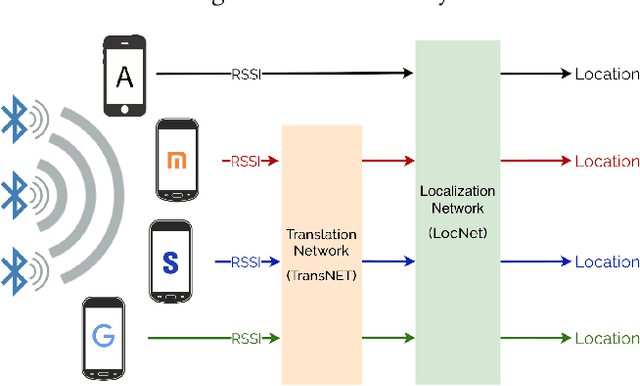
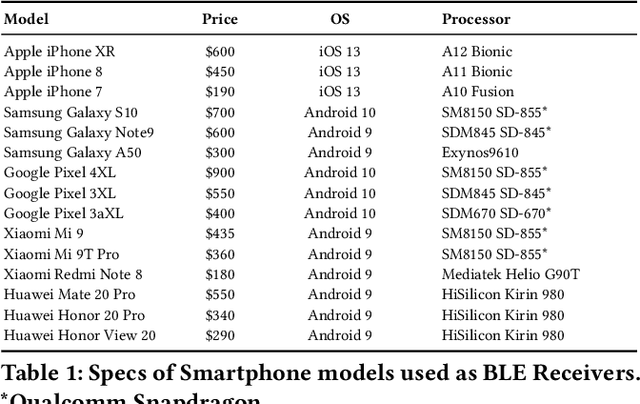
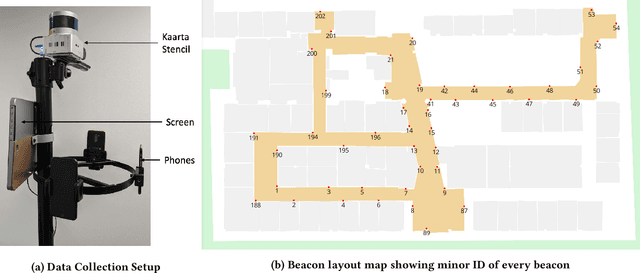
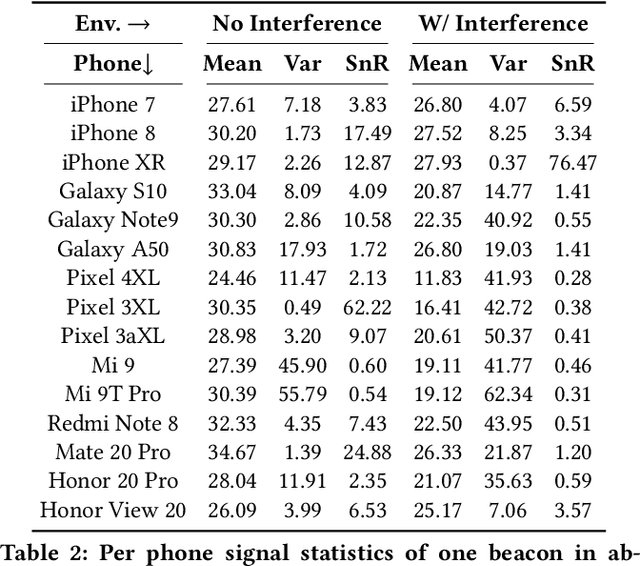
Accurate smartphone localization (< 1-meter error) for indoor navigation using only RSSI received from a set of BLE beacons remains a challenging problem, due to the inherent noise of RSSI measurements. To overcome the large variance in RSSI measurements, we propose a data-driven approach that uses a deep recurrent network, DeepBLE, to localize the smartphone using RSSI measured from multiple beacons in an environment. In particular, we focus on the ability of our approach to generalize across many smartphone brands (e.g., Apple, Samsung) and models (e.g., iPhone 8, S10). Towards this end, we collect a large-scale dataset of 15 hours of smartphone data, which consists of over 50,000 BLE beacon RSSI measurements collected from 47 beacons in a single building using 15 different popular smartphone models, along with precise 2D location annotations. Our experiments show that there is a very high variability of RSSI measurements across smartphone models (especially across brand), making it very difficult to apply supervised learning using only a subset of smartphone models. To address this challenge, we propose a novel statistic similarity loss (SSL) which enables our model to generalize to unseen phones using a semi-supervised learning approach. For known phones, the iPhone XR achieves the best mean distance error of 0.84 meters. For unknown phones, the Huawei Mate20 Pro shows the greatest improvement, cutting error by over 38\% from 2.62 meters to 1.63 meters error using our semi-supervised adaptation method.
Modeling Social Group Communication with Multi-Agent Imitation Learning
Mar 04, 2019

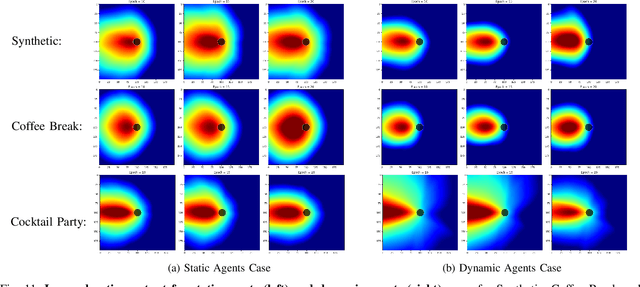
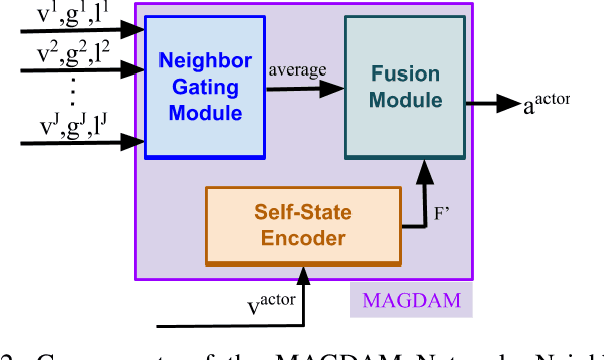
In crowded social scenarios with a myriad of external stimuli, human brains exhibit a natural ability to filter out irrelevant information and narrowly focus their attention. In the midst of multiple groups of people, humans use such sensory gating to effectively further their own group's interactional goals. In this work, we consider the design of a policy network to model multi-group multi-person communication. Our policy takes as input the state of the world such as an agent's gaze direction, body pose of other agents or history of past actions, and outputs an optimal action such as speaking, listening or responding (communication modes). Inspired by humans' natural neurobiological filtering process, a central component of our policy network design is an information gating function, termed the Kinesic-Proxemic-Message Gate (KPM-Gate), that models the ability of an agent to selectively gather information from specific neighboring agents. The degree of influence of a neighbor is based on dynamic non-verbal cues such as body motion, head pose (kinesics) and interpersonal space (proxemics). We further show that the KPM-Gate can be used to discover social groups using its natural interpretation as a social attention mechanism. We pose the communication policy learning problem as a multi-agent imitation learning problem. We learn a single policy shared by all agents under the assumption of a decentralized Markov decision process. We term our policy network as the Multi-Agent Group Discovery and Communication Mode Network (MAGDAM network), as it learns social group structure in addition to the dynamics of group communication. Our experimental validation on both synthetic and real world data shows that our model is able to both discover social group structure and learn an accurate multi-agent communication policy.