 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnatomically-aware Uncertainty for Semi-supervised Image Segmentation
Oct 24, 2023Semi-supervised learning relaxes the need of large pixel-wise labeled datasets for image segmentation by leveraging unlabeled data. A prominent way to exploit unlabeled data is to regularize model predictions. Since the predictions of unlabeled data can be unreliable, uncertainty-aware schemes are typically employed to gradually learn from meaningful and reliable predictions. Uncertainty estimation methods, however, rely on multiple inferences from the model predictions that must be computed for each training step, which is computationally expensive. Moreover, these uncertainty maps capture pixel-wise disparities and do not consider global information. This work proposes a novel method to estimate segmentation uncertainty by leveraging global information from the segmentation masks. More precisely, an anatomically-aware representation is first learnt to model the available segmentation masks. The learnt representation thereupon maps the prediction of a new segmentation into an anatomically-plausible segmentation. The deviation from the plausible segmentation aids in estimating the underlying pixel-level uncertainty in order to further guide the segmentation network. The proposed method consequently estimates the uncertainty using a single inference from our representation, thereby reducing the total computation. We evaluate our method on two publicly available segmentation datasets of left atria in cardiac MRIs and of multiple organs in abdominal CTs. Our anatomically-aware method improves the segmentation accuracy over the state-of-the-art semi-supervised methods in terms of two commonly used evaluation metrics.
Trust your neighbours: Penalty-based constraints for model calibration
Mar 11, 2023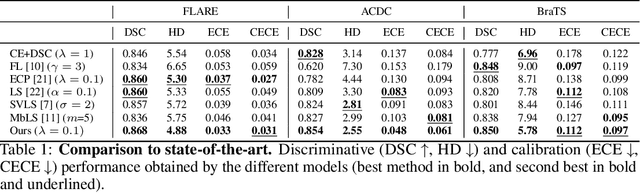
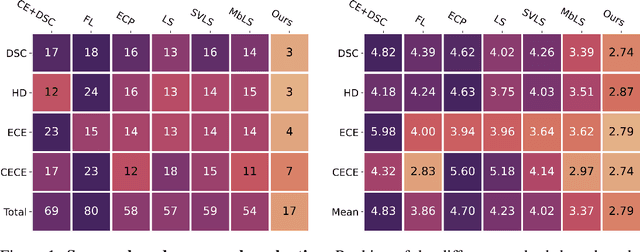

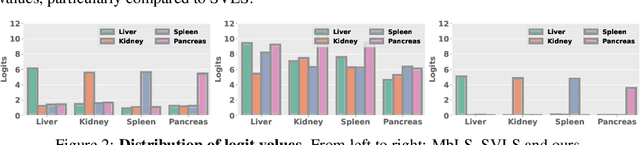
Ensuring reliable confidence scores from deep networks is of pivotal importance in critical decision-making systems, notably in the medical domain. While recent literature on calibrating deep segmentation networks has led to significant progress, their uncertainty is usually modeled by leveraging the information of individual pixels, which disregards the local structure of the object of interest. In particular, only the recent Spatially Varying Label Smoothing (SVLS) approach addresses this issue by softening the pixel label assignments with a discrete spatial Gaussian kernel. In this work, we first present a constrained optimization perspective of SVLS and demonstrate that it enforces an implicit constraint on soft class proportions of surrounding pixels. Furthermore, our analysis shows that SVLS lacks a mechanism to balance the contribution of the constraint with the primary objective, potentially hindering the optimization process. Based on these observations, we propose a principled and simple solution based on equality constraints on the logit values, which enables to control explicitly both the enforced constraint and the weight of the penalty, offering more flexibility. Comprehensive experiments on a variety of well-known segmentation benchmarks demonstrate the superior performance of the proposed approach.
Attention-based Dynamic Subspace Learners for Medical Image Analysis
Jun 18, 2022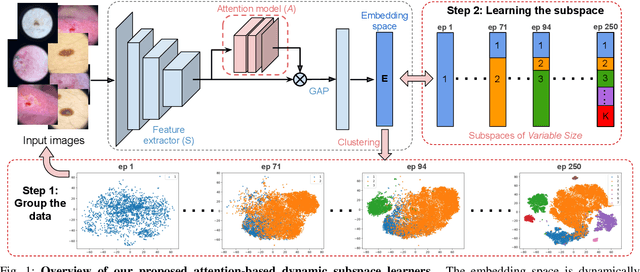
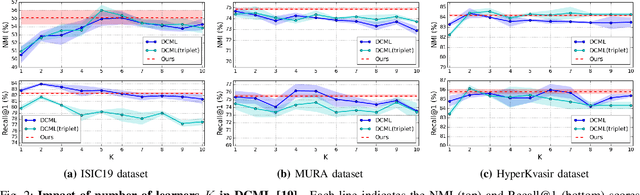
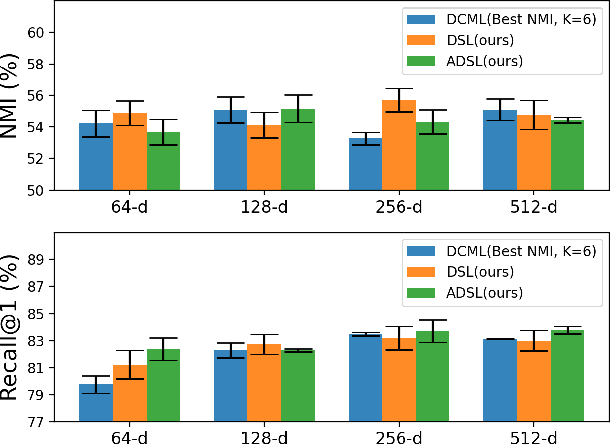
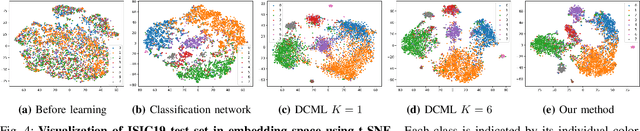
Learning similarity is a key aspect in medical image analysis, particularly in recommendation systems or in uncovering the interpretation of anatomical data in images. Most existing methods learn such similarities in the embedding space over image sets using a single metric learner. Images, however, have a variety of object attributes such as color, shape, or artifacts. Encoding such attributes using a single metric learner is inadequate and may fail to generalize. Instead, multiple learners could focus on separate aspects of these attributes in subspaces of an overarching embedding. This, however, implies the number of learners to be found empirically for each new dataset. This work, Dynamic Subspace Learners, proposes to dynamically exploit multiple learners by removing the need of knowing apriori the number of learners and aggregating new subspace learners during training. Furthermore, the visual interpretability of such subspace learning is enforced by integrating an attention module into our method. This integrated attention mechanism provides a visual insight of discriminative image features that contribute to the clustering of image sets and a visual explanation of the embedding features. The benefits of our attention-based dynamic subspace learners are evaluated in the application of image clustering, image retrieval, and weakly supervised segmentation. Our method achieves competitive results with the performances of multiple learners baselines and significantly outperforms the classification network in terms of clustering and retrieval scores on three different public benchmark datasets. Moreover, our attention maps offer a proxy-labels, which improves the segmentation accuracy up to 15% in Dice scores when compared to state-of-the-art interpretation techniques.
Leveraging Labeling Representations in Uncertainty-based Semi-supervised Segmentation
Mar 10, 2022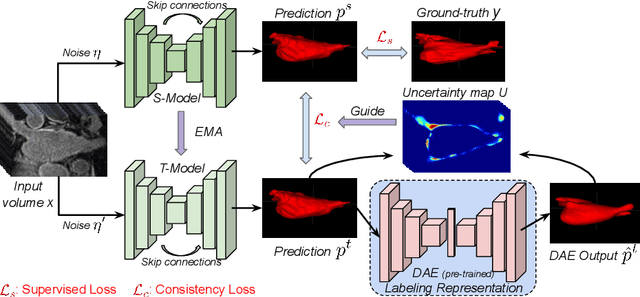
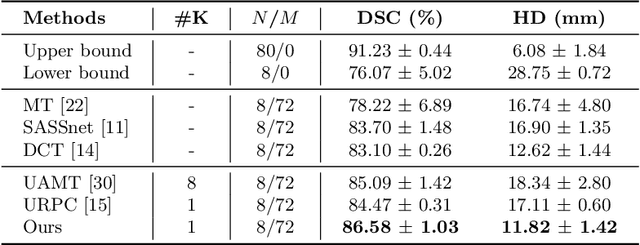
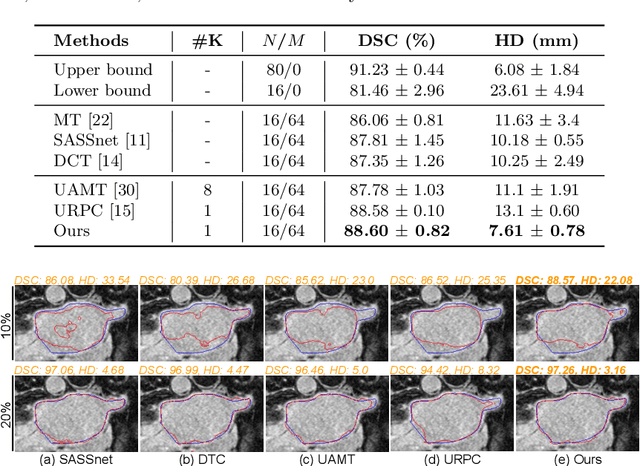
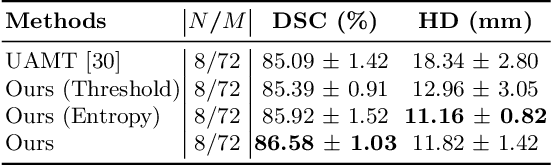
Semi-supervised segmentation tackles the scarcity of annotations by leveraging unlabeled data with a small amount of labeled data. A prominent way to utilize the unlabeled data is by consistency training which commonly uses a teacher-student network, where a teacher guides a student segmentation. The predictions of unlabeled data are not reliable, therefore, uncertainty-aware methods have been proposed to gradually learn from meaningful and reliable predictions. Uncertainty estimation, however, relies on multiple inferences from model predictions that need to be computed for each training step, which is computationally expensive. This work proposes a novel method to estimate the pixel-level uncertainty by leveraging the labeling representation of segmentation masks. On the one hand, a labeling representation is learnt to represent the available segmentation masks. The learnt labeling representation is used to map the prediction of the segmentation into a set of plausible masks. Such a reconstructed segmentation mask aids in estimating the pixel-level uncertainty guiding the segmentation network. The proposed method estimates the uncertainty with a single inference from the labeling representation, thereby reducing the total computation. We evaluate our method on the 3D segmentation of left atrium in MRI, and we show that our uncertainty estimates from our labeling representation improve the segmentation accuracy over state-of-the-art methods.
Manifold-driven Attention Maps for Weakly Supervised Segmentation
Apr 07, 2020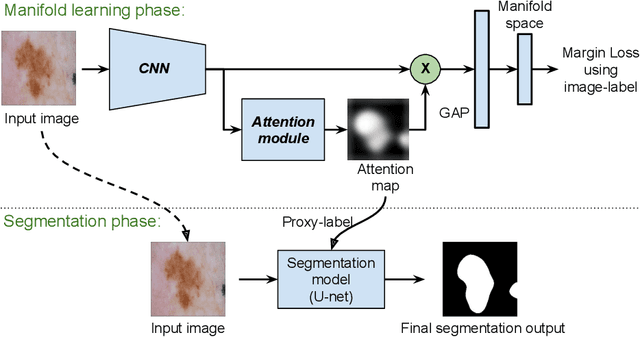
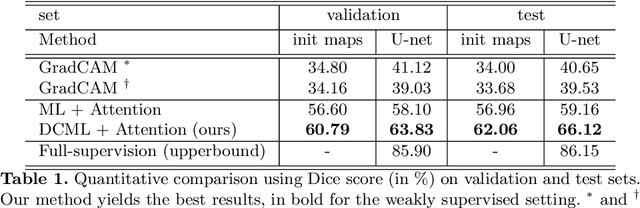
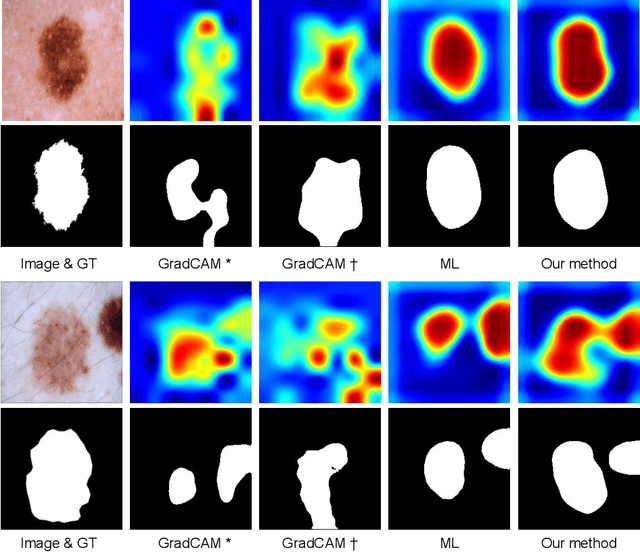
Segmentation using deep learning has shown promising directions in medical imaging as it aids in the analysis and diagnosis of diseases. Nevertheless, a main drawback of deep models is that they require a large amount of pixel-level labels, which are laborious and expensive to obtain. To mitigate this problem, weakly supervised learning has emerged as an efficient alternative, which employs image-level labels, scribbles, points, or bounding boxes as supervision. Among these, image-level labels are easier to obtain. However, since this type of annotation only contains object category information, the segmentation task under this learning paradigm is a challenging problem. To address this issue, visual salient regions derived from trained classification networks are typically used. Despite their success to identify important regions on classification tasks, these saliency regions only focus on the most discriminant areas of an image, limiting their use in semantic segmentation. In this work, we propose a manifold driven attention-based network to enhance visual salient regions, thereby improving segmentation accuracy in a weakly supervised setting. Our method generates superior attention maps directly during inference without the need of extra computations. We evaluate the benefits of our approach in the task of segmentation using a public benchmark on skin lesion images. Results demonstrate that our method outperforms the state-of-the-art GradCAM by a margin of ~22% in terms of Dice score.
FPD-M-net: Fingerprint Image Denoising and Inpainting Using M-Net Based Convolutional Neural Networks
Dec 26, 2018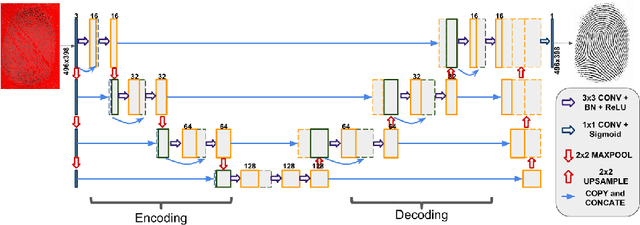
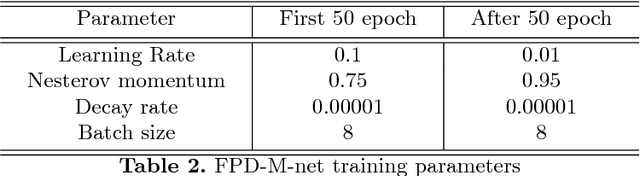

The fingerprint is a common biometric used for authentication and verification of an individual. These images are degraded when fingers are wet, dirty, dry or wounded and due to the failure of the sensors, etc. The extraction of the fingerprint from a degraded image requires denoising and inpainting. We propose to address these problems with an end-to-end trainable Convolutional Neural Network based architecture called FPD-M-net, by posing the fingerprint denoising and inpainting problem as a segmentation (foreground) task. Our architecture is based on the M-net with a change: structure similarity loss function, used for better extraction of the fingerprint from the noisy background. Our method outperforms the baseline method and achieves an overall 3rd rank in the Chalearn LAP Inpainting Competition Track 3 - Fingerprint Denoising and Inpainting, ECCV 2018