 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed-supervised segmentation: Confidence maximization helps knowledge distillation
Paper and Code
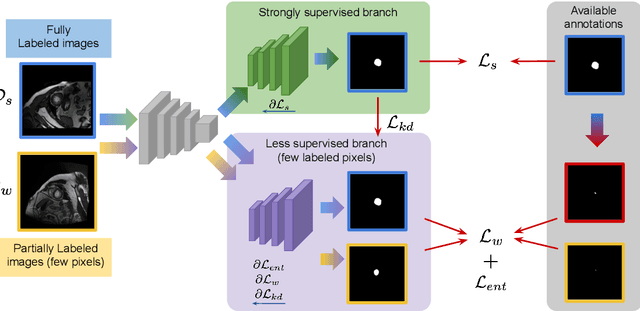
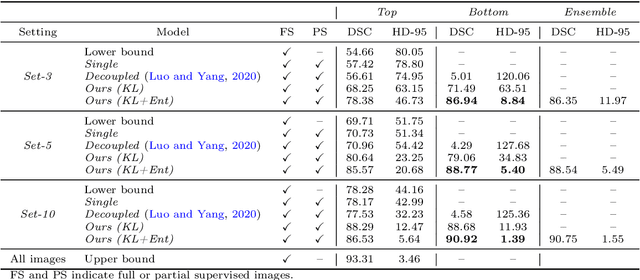
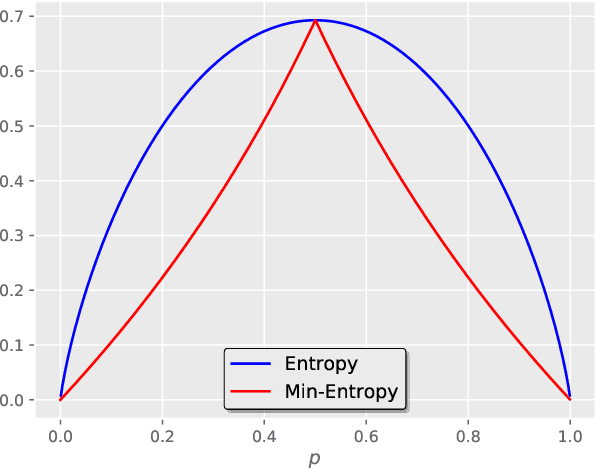

Despite achieving promising results in a breadth of medical image segmentation tasks, deep neural networks require large training datasets with pixel-wise annotations. Obtaining these curated datasets is a cumbersome process which limits the application in scenarios where annotated images are scarce. Mixed supervision is an appealing alternative for mitigating this obstacle, where only a small fraction of the data contains complete pixel-wise annotations and other images have a weaker form of supervision. In this work, we propose a dual-branch architecture, where the upper branch (teacher) receives strong annotations, while the bottom one (student) is driven by limited supervision and guided by the upper branch. Combined with a standard cross-entropy loss over the labeled pixels, our novel formulation integrates two important terms: (i) a Shannon entropy loss defined over the less-supervised images, which encourages confident student predictions in the bottom branch; and (ii) a Kullback-Leibler (KL) divergence term, which transfers the knowledge of the strongly supervised branch to the less-supervised branch and guides the entropy (student-confidence) term to avoid trivial solutions. We show that the synergy between the entropy and KL divergence yields substantial improvements in performance. We also discuss an interesting link between Shannon-entropy minimization and standard pseudo-mask generation, and argue that the former should be preferred over the latter for leveraging information from unlabeled pixels. Quantitative and qualitative results on two publicly available datasets demonstrate that our method significantly outperforms other strategies for semantic segmentation within a mixed-supervision framework, as well as recent semi-supervised approaches. Moreover, we show that the branch trained with reduced supervision and guided by the top branch largely outperforms the latter.