 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Causal Transition Matrix for Instance-dependent Label Noise
Dec 18, 2024



Noisy labels are both inevitable and problematic in machine learning methods, as they negatively impact models' generalization ability by causing overfitting. In the context of learning with noise, the transition matrix plays a crucial role in the design of statistically consistent algorithms. However, the transition matrix is often considered unidentifiable. One strand of methods typically addresses this problem by assuming that the transition matrix is instance-independent; that is, the probability of mislabeling a particular instance is not influenced by its characteristics or attributes. This assumption is clearly invalid in complex real-world scenarios. To better understand the transition relationship and relax this assumption, we propose to study the data generation process of noisy labels from a causal perspective. We discover that an unobservable latent variable can affect either the instance itself, the label annotation procedure, or both, which complicates the identification of the transition matrix. To address various scenarios, we have unified these observations within a new causal graph. In this graph, the input instance is divided into a noise-resistant component and a noise-sensitive component based on whether they are affected by the latent variable. These two components contribute to identifying the ``causal transition matrix'', which approximates the true transition matrix with theoretical guarantee. In line with this, we have designed a novel training framework that explicitly models this causal relationship and, as a result, achieves a more accurate model for inferring the clean label.
ESCM$^2$: Entire Space Counterfactual Multi-Task Model for Post-Click Conversion Rate Estimation
Apr 03, 2022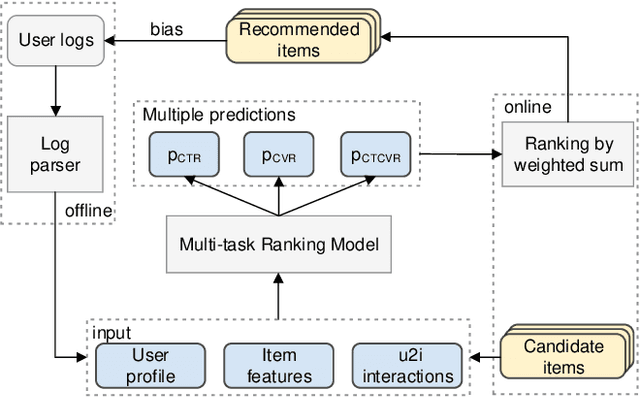

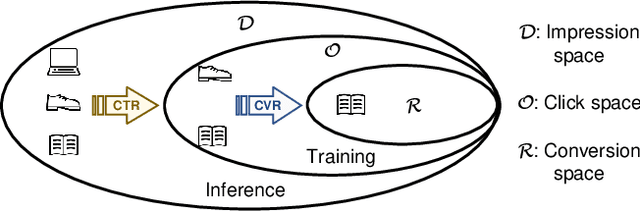
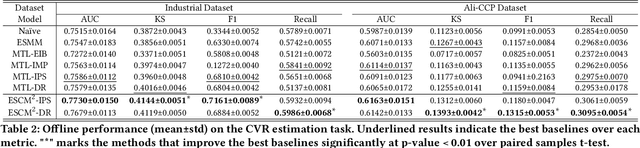
Accurate estimation of post-click conversion rate is critical for building recommender systems, which has long been confronted with sample selection bias and data sparsity issues. Methods in the Entire Space Multi-task Model (ESMM) family leverage the sequential pattern of user actions, i.e. $impression\rightarrow click \rightarrow conversion$ to address data sparsity issue. However, they still fail to ensure the unbiasedness of CVR estimates. In this paper, we theoretically demonstrate that ESMM suffers from the following two problems: (1) Inherent Estimation Bias (IEB), where the estimated CVR of ESMM is inherently higher than the ground truth; (2) Potential Independence Priority (PIP) for CTCVR estimation, where there is a risk that the ESMM overlooks the causality from click to conversion. To this end, we devise a principled approach named Entire Space Counterfactual Multi-task Modelling (ESCM$^2$), which employs a counterfactual risk miminizer as a regularizer in ESMM to address both IEB and PIP issues simultaneously. Extensive experiments on offline datasets and online environments demonstrate that our proposed ESCM$^2$ can largely mitigate the inherent IEB and PIP issues and achieve better performance than baseline models.