 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Ambiguity to Action: A POMDP Perspective on Partial Multi-Label Ambiguity and Its Horizon-One Resolution
Feb 04, 2026In partial multi-label learning (PML), the true labels are unobserved, which makes label disambiguation important but difficult. A key challenge is that ambiguous candidate labels can propagate errors into downstream tasks such as feature engineering. To solve this issue, we jointly model the disambiguation and feature selection tasks as Partially Observable Markov Decision Processes (POMDP) to turn PML risk minimization into expected-return maximization. Stage 1 trains a transformer policy via reinforcement learning to produce high-quality hard pseudo-labels; Stage 2 describes feature selection as a sequential reinforcement learning problem, selecting features step by step and outputting an interpretable global ranking. We further provide the theoretical analysis of PML-POMDP correspondence and the excess-risk bound that decompose the error into pseudo label quality term and sample size. Experiments in multiple metrics and data sets verify the advantages of the framework.
The Semantic Architect: How FEAML Bridges Structured Data and LLMs for Multi-Label Tasks
Dec 17, 2025Existing feature engineering methods based on large language models (LLMs) have not yet been applied to multi-label learning tasks. They lack the ability to model complex label dependencies and are not specifically adapted to the characteristics of multi-label tasks. To address the above issues, we propose Feature Engineering Automation for Multi-Label Learning (FEAML), an automated feature engineering method for multi-label classification which leverages the code generation capabilities of LLMs. By utilizing metadata and label co-occurrence matrices, LLMs are guided to understand the relationships between data features and task objectives, based on which high-quality features are generated. The newly generated features are evaluated in terms of model accuracy to assess their effectiveness, while Pearson correlation coefficients are used to detect redundancy. FEAML further incorporates the evaluation results as feedback to drive LLMs to continuously optimize code generation in subsequent iterations. By integrating LLMs with a feedback mechanism, FEAML realizes an efficient, interpretable and self-improving feature engineering paradigm. Empirical results on various multi-label datasets demonstrate that our FEAML outperforms other feature engineering methods.
Combining LLM Semantic Reasoning with GNN Structural Modeling for Multi-View Multi-Label Feature Selection
Nov 19, 2025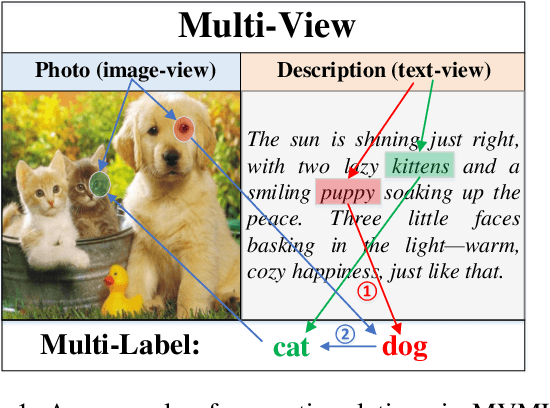



Multi-view multi-label feature selection aims to identify informative features from heterogeneous views, where each sample is associated with multiple interdependent labels. This problem is particularly important in machine learning involving high-dimensional, multimodal data such as social media, bioinformatics or recommendation systems. Existing Multi-View Multi-Label Feature Selection (MVMLFS) methods mainly focus on analyzing statistical information of data, but seldom consider semantic information. In this paper, we aim to use these two types of information jointly and propose a method that combines Large Language Models (LLMs) semantic reasoning with Graph Neural Networks (GNNs) structural modeling for MVMLFS. Specifically, the method consists of three main components. (1) LLM is first used as an evaluation agent to assess the latent semantic relevance among feature, view, and label descriptions. (2) A semantic-aware heterogeneous graph with two levels is designed to represent relations among features, views and labels: one is a semantic graph representing semantic relations, and the other is a statistical graph. (3) A lightweight Graph Attention Network (GAT) is applied to learn node embedding in the heterogeneous graph as feature saliency scores for ranking and selection. Experimental results on multiple benchmark datasets demonstrate the superiority of our method over state-of-the-art baselines, and it is still effective when applied to small-scale datasets, showcasing its robustness, flexibility, and generalization ability.
Redundancy-optimized Multi-head Attention Networks for Multi-View Multi-Label Feature Selection
Nov 16, 2025Multi-view multi-label data offers richer perspectives for artificial intelligence, but simultaneously presents significant challenges for feature selection due to the inherent complexity of interrelations among features, views and labels. Attention mechanisms provide an effective way for analyzing these intricate relationships. They can compute importance weights for information by aggregating correlations between Query and Key matrices to focus on pertinent values. However, existing attention-based feature selection methods predominantly focus on intra-view relationships, neglecting the complementarity of inter-view features and the critical feature-label correlations. Moreover, they often fail to account for feature redundancy, potentially leading to suboptimal feature subsets. To overcome these limitations, we propose a novel method based on Redundancy-optimized Multi-head Attention Networks for Multi-view Multi-label Feature Selection (RMAN-MMFS). Specifically, we employ each individual attention head to model intra-view feature relationships and use the cross-attention mechanisms between different heads to capture inter-view feature complementarity. Furthermore, we design static and dynamic feature redundancy terms: the static term mitigates redundancy within each view, while the dynamic term explicitly models redundancy between unselected and selected features across the entire selection process, thereby promoting feature compactness. Comprehensive evaluations on six real-world datasets, compared against six multi-view multi-label feature selection methods, demonstrate the superior performance of the proposed method.
Noise-Resistant Label Reconstruction Feature Selection for Partial Multi-Label Learning
Jun 05, 2025The "Curse of dimensionality" is prevalent across various data patterns, which increases the risk of model overfitting and leads to a decline in model classification performance. However, few studies have focused on this issue in Partial Multi-label Learning (PML), where each sample is associated with a set of candidate labels, at least one of which is correct. Existing PML methods addressing this problem are mainly based on the low-rank assumption. However, low-rank assumption is difficult to be satisfied in practical situations and may lead to loss of high-dimensional information. Furthermore, we find that existing methods have poor ability to identify positive labels, which is important in real-world scenarios. In this paper, a PML feature selection method is proposed considering two important characteristics of dataset: label relationship's noise-resistance and label connectivity. Our proposed method utilizes label relationship's noise-resistance to disambiguate labels. Then the learning process is designed through the reformed low-rank assumption. Finally, representative labels are found through label connectivity, and the weight matrix is reconstructed to select features with strong identification ability to these labels. The experimental results on benchmark datasets demonstrate the superiority of the proposed method.
Graph Random Walk with Feature-Label Space Alignment: A Multi-Label Feature Selection Method
May 29, 2025



The rapid growth in feature dimension may introduce implicit associations between features and labels in multi-label datasets, making the relationships between features and labels increasingly complex. Moreover, existing methods often adopt low-dimensional linear decomposition to explore the associations between features and labels. However, linear decomposition struggles to capture complex nonlinear associations and may lead to misalignment between the feature space and the label space. To address these two critical challenges, we propose innovative solutions. First, we design a random walk graph that integrates feature-feature, label-label, and feature-label relationships to accurately capture nonlinear and implicit indirect associations, while optimizing the latent representations of associations between features and labels after low-rank decomposition. Second, we align the variable spaces by leveraging low-dimensional representation coefficients, while preserving the manifold structure between the original high-dimensional multi-label data and the low-dimensional representation space. Extensive experiments and ablation studies conducted on seven benchmark datasets and three representative datasets using various evaluation metrics demonstrate the superiority of the proposed method\footnote{Code: https://github.com/Heilong623/-GRW-}.
Two-Stage Feature Generation with Transformer and Reinforcement Learning
May 28, 2025Feature generation is a critical step in machine learning, aiming to enhance model performance by capturing complex relationships within the data and generating meaningful new features. Traditional feature generation methods heavily rely on domain expertise and manual intervention, making the process labor-intensive and challenging to adapt to different scenarios. Although automated feature generation techniques address these issues to some extent, they often face challenges such as feature redundancy, inefficiency in feature space exploration, and limited adaptability to diverse datasets and tasks. To address these problems, we propose a Two-Stage Feature Generation (TSFG) framework, which integrates a Transformer-based encoder-decoder architecture with Proximal Policy Optimization (PPO). The encoder-decoder model in TSFG leverages the Transformer's self-attention mechanism to efficiently represent and transform features, capturing complex dependencies within the data. PPO further enhances TSFG by dynamically adjusting the feature generation strategy based on task-specific feedback, optimizing the process for improved performance and adaptability. TSFG dynamically generates high-quality feature sets, significantly improving the predictive performance of machine learning models. Experimental results demonstrate that TSFG outperforms existing state-of-the-art methods in terms of feature quality and adaptability.
Dual-Agent Reinforcement Learning for Automated Feature Generation
May 19, 2025Feature generation involves creating new features from raw data to capture complex relationships among the original features, improving model robustness and machine learning performance. Current methods using reinforcement learning for feature generation have made feature exploration more flexible and efficient. However, several challenges remain: first, during feature expansion, a large number of redundant features are generated. When removing them, current methods only retain the best features each round, neglecting those that perform poorly initially but could improve later. Second, the state representation used by current methods fails to fully capture complex feature relationships. Third, there are significant differences between discrete and continuous features in tabular data, requiring different operations for each type. To address these challenges, we propose a novel dual-agent reinforcement learning method for feature generation. Two agents are designed: the first generates new features, and the second determines whether they should be preserved. A self-attention mechanism enhances state representation, and diverse operations distinguish interactions between discrete and continuous features. The experimental results on multiple datasets demonstrate that the proposed method is effective. The code is available at https://github.com/extess0/DARL.
Collaboration and Controversy Among Experts: Rumor Early Detection by Tuning a Comment Generator
Apr 05, 2025Over the past decade, social media platforms have been key in spreading rumors, leading to significant negative impacts. To counter this, the community has developed various Rumor Detection (RD) algorithms to automatically identify them using user comments as evidence. However, these RD methods often fail in the early stages of rumor propagation when only limited user comments are available, leading the community to focus on a more challenging topic named Rumor Early Detection (RED). Typically, existing RED methods learn from limited semantics in early comments. However, our preliminary experiment reveals that the RED models always perform best when the number of training and test comments is consistent and extensive. This inspires us to address the RED issue by generating more human-like comments to support this hypothesis. To implement this idea, we tune a comment generator by simulating expert collaboration and controversy and propose a new RED framework named CAMERED. Specifically, we integrate a mixture-of-expert structure into a generative language model and present a novel routing network for expert collaboration. Additionally, we synthesize a knowledgeable dataset and design an adversarial learning strategy to align the style of generated comments with real-world comments. We further integrate generated and original comments with a mutual controversy fusion module. Experimental results show that CAMERED outperforms state-of-the-art RED baseline models and generation methods, demonstrating its effectiveness.
Entropy-based Exploration Conduction for Multi-step Reasoning
Mar 20, 2025In large language model (LLM) reasoning, multi-step processes have proven effective for solving complex tasks. However, the depth of exploration can significantly affect the reasoning performance. Existing methods to automatically decide the depth often bring high costs and lack flexibility, and thus undermine the model's reasoning accuracy. To address these issues, we propose Entropy-based Exploration Depth Conduction (Entro-duction), a novel method that dynamically adjusts the exploration depth during multi-step reasoning by monitoring LLM's output entropy and variance entropy. We employ these two metrics to capture the model's current uncertainty and the fluctuation of uncertainty across consecutive reasoning steps. Based on the observed changes, the LLM selects whether to deepen, expand or stop exploration according to the probability. In this way, we balance the reasoning accuracy and exploration effectiveness. Experimental results across four benchmark datasets demonstrate the efficacy of Entro-duction. We further conduct experiments and analysis on the components of Entro-duction to discuss their contributions to reasoning performance.