 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Cut-informed Graph Embedding and Clustering
Mar 09, 2025Graph clustering aims to divide the graph into different clusters. The recently emerging deep graph clustering approaches are largely built on graph neural networks (GNN). However, GNN is designed for general graph encoding and there is a common issue of representation collapse in existing GNN-based deep graph clustering algorithms. We attribute two main reasons for such issue: (i) the inductive bias of GNN models: GNNs tend to generate similar representations for proximal nodes. Since graphs often contain a non-negligible amount of inter-cluster links, the bias results in error message passing and leads to biased clustering; (ii) the clustering guided loss function: most traditional approaches strive to make all samples closer to pre-learned cluster centers, which cause a degenerate solution assigning all data points to a single label thus make all samples and less discriminative. To address these challenges, we investigate graph clustering from a graph cut perspective and propose an innovative and non-GNN-based Deep Cut-informed Graph embedding and Clustering framework, namely DCGC. This framework includes two modules: (i) cut-informed graph encoding; (ii) self-supervised graph clustering via optimal transport. For the encoding module, we derive a cut-informed graph embedding objective to fuse graph structure and attributes by minimizing their joint normalized cut. For the clustering module, we utilize the optimal transport theory to obtain the clustering assignments, which can balance the guidance of proximity to the pre-learned cluster center. With the above two tailored designs, DCGC is more suitable for the graph clustering task, which can effectively alleviate the problem of representation collapse and achieve better performance. We conduct extensive experiments to demonstrate that our method is simple but effective compared with benchmarks.
Diversity-Oriented Data Augmentation with Large Language Models
Feb 17, 2025Data augmentation is an essential technique in natural language processing (NLP) for enriching training datasets by generating diverse samples. This process is crucial for improving the robustness and generalization capabilities of NLP models. However, a significant challenge remains: \textit{Insufficient Attention to Sample Distribution Diversity}. Most existing methods focus on increasing the sample numbers while neglecting the sample distribution diversity, which can lead to model overfitting. In response, we explore data augmentation's impact on dataset diversity and propose a \textbf{\underline{D}}iversity-\textbf{\underline{o}}riented data \textbf{\underline{Aug}}mentation framework (\textbf{DoAug}). % \(\mathscr{DoAug}\) Specifically, we utilize a diversity-oriented fine-tuning approach to train an LLM as a diverse paraphraser, which is capable of augmenting textual datasets by generating diversified paraphrases. Then, we apply the LLM paraphraser to a selected coreset of highly informative samples and integrate the paraphrases with the original data to create a more diverse augmented dataset. Finally, we conduct extensive experiments on 12 real-world textual datasets. The results show that our fine-tuned LLM augmenter improves diversity while preserving label consistency, thereby enhancing the robustness and performance of downstream tasks. Specifically, it achieves an average performance gain of \(10.52\%\), surpassing the runner-up baseline with more than three percentage points.
A Comprehensive Survey on Data Augmentation
May 17, 2024



Data augmentation is a series of techniques that generate high-quality artificial data by manipulating existing data samples. By leveraging data augmentation techniques, AI models can achieve significantly improved applicability in tasks involving scarce or imbalanced datasets, thereby substantially enhancing AI models' generalization capabilities. Existing literature surveys only focus on a certain type of specific modality data, and categorize these methods from modality-specific and operation-centric perspectives, which lacks a consistent summary of data augmentation methods across multiple modalities and limits the comprehension of how existing data samples serve the data augmentation process. To bridge this gap, we propose a more enlightening taxonomy that encompasses data augmentation techniques for different common data modalities. Specifically, from a data-centric perspective, this survey proposes a modality-independent taxonomy by investigating how to take advantage of the intrinsic relationship between data samples, including single-wise, pair-wise, and population-wise sample data augmentation methods. Additionally, we categorize data augmentation methods across five data modalities through a unified inductive approach.
TFWT: Tabular Feature Weighting with Transformer
May 17, 2024
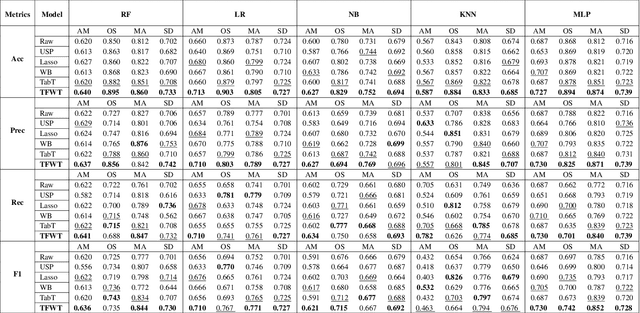

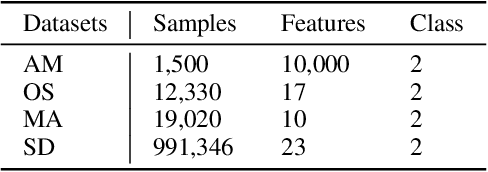
In this paper, we propose a novel feature weighting method to address the limitation of existing feature processing methods for tabular data. Typically the existing methods assume equal importance across all samples and features in one dataset. This simplified processing methods overlook the unique contributions of each feature, and thus may miss important feature information. As a result, it leads to suboptimal performance in complex datasets with rich features. To address this problem, we introduce Tabular Feature Weighting with Transformer, a novel feature weighting approach for tabular data. Our method adopts Transformer to capture complex feature dependencies and contextually assign appropriate weights to discrete and continuous features. Besides, we employ a reinforcement learning strategy to further fine-tune the weighting process. Our extensive experimental results across various real-world datasets and diverse downstream tasks show the effectiveness of TFWT and highlight the potential for enhancing feature weighting in tabular data analysis.