 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRubikSQL: Lifelong Learning Agentic Knowledge Base as an Industrial NL2SQL System
Aug 25, 2025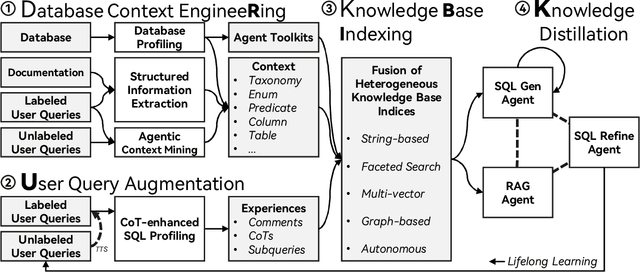
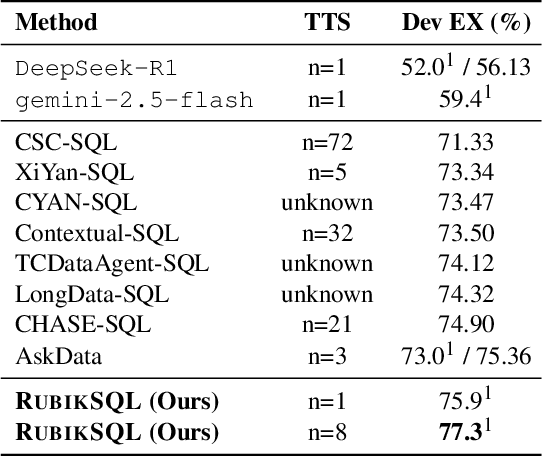
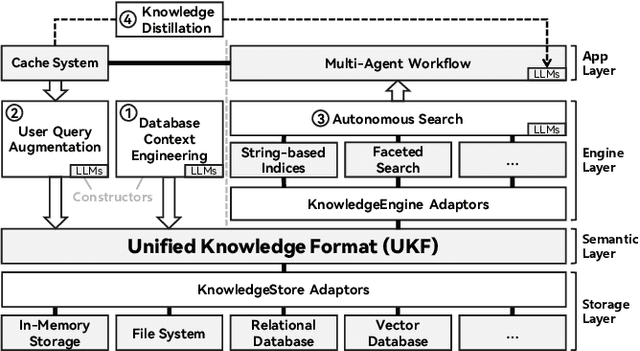
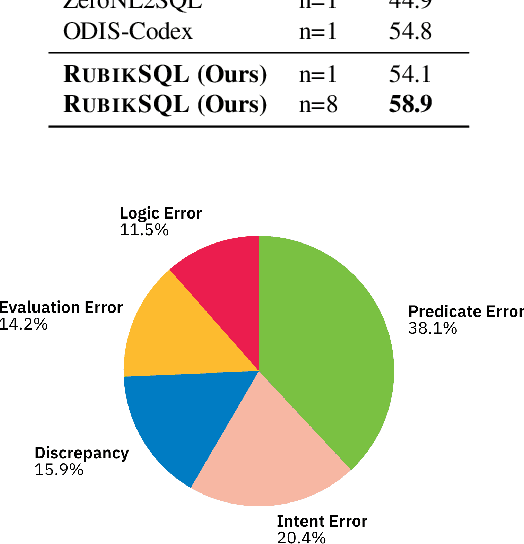
We present RubikSQL, a novel NL2SQL system designed to address key challenges in real-world enterprise-level NL2SQL, such as implicit intents and domain-specific terminology. RubikSQL frames NL2SQL as a lifelong learning task, demanding both Knowledge Base (KB) maintenance and SQL generation. RubikSQL systematically builds and refines its KB through techniques including database profiling, structured information extraction, agentic rule mining, and Chain-of-Thought (CoT)-enhanced SQL profiling. RubikSQL then employs a multi-agent workflow to leverage this curated KB, generating accurate SQLs. RubikSQL achieves SOTA performance on both the KaggleDBQA and BIRD Mini-Dev datasets. Finally, we release the RubikBench benchmark, a new benchmark specifically designed to capture vital traits of industrial NL2SQL scenarios, providing a valuable resource for future research.
Step-Audio-AQAA: a Fully End-to-End Expressive Large Audio Language Model
Jun 10, 2025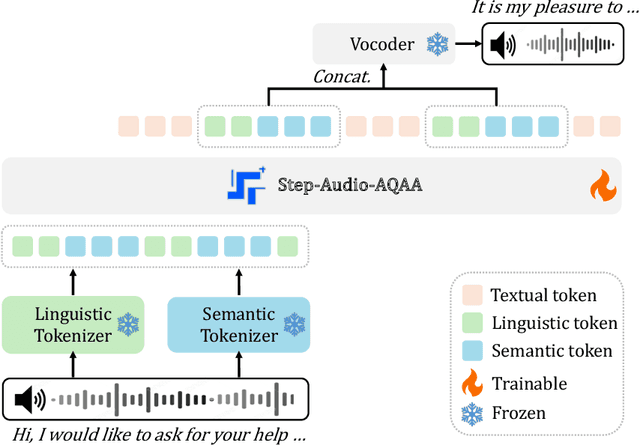
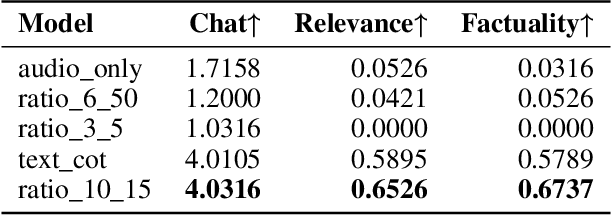
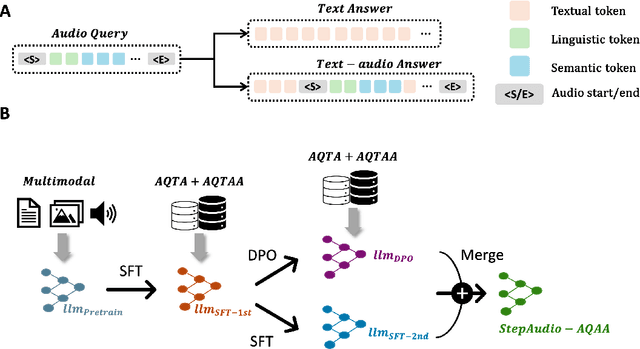

Large Audio-Language Models (LALMs) have significantly advanced intelligent human-computer interaction, yet their reliance on text-based outputs limits their ability to generate natural speech responses directly, hindering seamless audio interactions. To address this, we introduce Step-Audio-AQAA, a fully end-to-end LALM designed for Audio Query-Audio Answer (AQAA) tasks. The model integrates a dual-codebook audio tokenizer for linguistic and semantic feature extraction, a 130-billion-parameter backbone LLM and a neural vocoder for high-fidelity speech synthesis. Our post-training approach employs interleaved token-output of text and audio to enhance semantic coherence and combines Direct Preference Optimization (DPO) with model merge to improve performance. Evaluations on the StepEval-Audio-360 benchmark demonstrate that Step-Audio-AQAA excels especially in speech control, outperforming the state-of-art LALMs in key areas. This work contributes a promising solution for end-to-end LALMs and highlights the critical role of token-based vocoder in enhancing overall performance for AQAA tasks.
Step-Video-TI2V Technical Report: A State-of-the-Art Text-Driven Image-to-Video Generation Model
Mar 14, 2025We present Step-Video-TI2V, a state-of-the-art text-driven image-to-video generation model with 30B parameters, capable of generating videos up to 102 frames based on both text and image inputs. We build Step-Video-TI2V-Eval as a new benchmark for the text-driven image-to-video task and compare Step-Video-TI2V with open-source and commercial TI2V engines using this dataset. Experimental results demonstrate the state-of-the-art performance of Step-Video-TI2V in the image-to-video generation task. Both Step-Video-TI2V and Step-Video-TI2V-Eval are available at https://github.com/stepfun-ai/Step-Video-TI2V.
Step-Audio: Unified Understanding and Generation in Intelligent Speech Interaction
Feb 18, 2025Real-time speech interaction, serving as a fundamental interface for human-machine collaboration, holds immense potential. However, current open-source models face limitations such as high costs in voice data collection, weakness in dynamic control, and limited intelligence. To address these challenges, this paper introduces Step-Audio, the first production-ready open-source solution. Key contributions include: 1) a 130B-parameter unified speech-text multi-modal model that achieves unified understanding and generation, with the Step-Audio-Chat version open-sourced; 2) a generative speech data engine that establishes an affordable voice cloning framework and produces the open-sourced lightweight Step-Audio-TTS-3B model through distillation; 3) an instruction-driven fine control system enabling dynamic adjustments across dialects, emotions, singing, and RAP; 4) an enhanced cognitive architecture augmented with tool calling and role-playing abilities to manage complex tasks effectively. Based on our new StepEval-Audio-360 evaluation benchmark, Step-Audio achieves state-of-the-art performance in human evaluations, especially in terms of instruction following. On open-source benchmarks like LLaMA Question, shows 9.3% average performance improvement, demonstrating our commitment to advancing the development of open-source multi-modal language technologies. Our code and models are available at https://github.com/stepfun-ai/Step-Audio.
Diversity-Oriented Data Augmentation with Large Language Models
Feb 17, 2025Data augmentation is an essential technique in natural language processing (NLP) for enriching training datasets by generating diverse samples. This process is crucial for improving the robustness and generalization capabilities of NLP models. However, a significant challenge remains: \textit{Insufficient Attention to Sample Distribution Diversity}. Most existing methods focus on increasing the sample numbers while neglecting the sample distribution diversity, which can lead to model overfitting. In response, we explore data augmentation's impact on dataset diversity and propose a \textbf{\underline{D}}iversity-\textbf{\underline{o}}riented data \textbf{\underline{Aug}}mentation framework (\textbf{DoAug}). % \(\mathscr{DoAug}\) Specifically, we utilize a diversity-oriented fine-tuning approach to train an LLM as a diverse paraphraser, which is capable of augmenting textual datasets by generating diversified paraphrases. Then, we apply the LLM paraphraser to a selected coreset of highly informative samples and integrate the paraphrases with the original data to create a more diverse augmented dataset. Finally, we conduct extensive experiments on 12 real-world textual datasets. The results show that our fine-tuned LLM augmenter improves diversity while preserving label consistency, thereby enhancing the robustness and performance of downstream tasks. Specifically, it achieves an average performance gain of \(10.52\%\), surpassing the runner-up baseline with more than three percentage points.
LEKA:LLM-Enhanced Knowledge Augmentation
Jan 29, 2025



Humans excel in analogical learning and knowledge transfer and, more importantly, possess a unique understanding of identifying appropriate sources of knowledge. From a model's perspective, this presents an interesting challenge. If models could autonomously retrieve knowledge useful for transfer or decision-making to solve problems, they would transition from passively acquiring to actively accessing and learning from knowledge. However, filling models with knowledge is relatively straightforward -- it simply requires more training and accessible knowledge bases. The more complex task is teaching models about which knowledge can be analogized and transferred. Therefore, we design a knowledge augmentation method LEKA for knowledge transfer that actively searches for suitable knowledge sources that can enrich the target domain's knowledge. This LEKA method extracts key information from textual information from the target domain, retrieves pertinent data from external data libraries, and harmonizes retrieved data with the target domain data in feature space and marginal probability measures. We validate the effectiveness of our approach through extensive experiments across various domains and demonstrate significant improvements over traditional methods in reducing computational costs, automating data alignment, and optimizing transfer learning outcomes.
Scoring with Large Language Models: A Study on Measuring Empathy of Responses in Dialogues
Dec 28, 2024In recent years, Large Language Models (LLMs) have become increasingly more powerful in their ability to complete complex tasks. One such task in which LLMs are often employed is scoring, i.e., assigning a numerical value from a certain scale to a subject. In this paper, we strive to understand how LLMs score, specifically in the context of empathy scoring. We develop a novel and comprehensive framework for investigating how effective LLMs are at measuring and scoring empathy of responses in dialogues, and what methods can be employed to deepen our understanding of LLM scoring. Our strategy is to approximate the performance of state-of-the-art and fine-tuned LLMs with explicit and explainable features. We train classifiers using various features of dialogues including embeddings, the Motivational Interviewing Treatment Integrity (MITI) Code, a set of explicit subfactors of empathy as proposed by LLMs, and a combination of the MITI Code and the explicit subfactors. Our results show that when only using embeddings, it is possible to achieve performance close to that of generic LLMs, and when utilizing the MITI Code and explicit subfactors scored by an LLM, the trained classifiers can closely match the performance of fine-tuned LLMs. We employ feature selection methods to derive the most crucial features in the process of empathy scoring. Our work provides a new perspective toward understanding LLM empathy scoring and helps the LLM community explore the potential of LLM scoring in social science studies.
Enhancing Risk Assessment in Transformers with Loss-at-Risk Functions
Nov 04, 2024



In the financial field, precise risk assessment tools are essential for decision-making. Recent studies have challenged the notion that traditional network loss functions like Mean Square Error (MSE) are adequate, especially under extreme risk conditions that can lead to significant losses during market upheavals. Transformers and Transformer-based models are now widely used in financial forecasting according to their outstanding performance in time-series-related predictions. However, these models typically lack sensitivity to extreme risks and often underestimate great financial losses. To address this problem, we introduce a novel loss function, the Loss-at-Risk, which incorporates Value at Risk (VaR) and Conditional Value at Risk (CVaR) into Transformer models. This integration allows Transformer models to recognize potential extreme losses and further improves their capability to handle high-stakes financial decisions. Moreover, we conduct a series of experiments with highly volatile financial datasets to demonstrate that our Loss-at-Risk function improves the Transformers' risk prediction and management capabilities without compromising their decision-making accuracy or efficiency. The results demonstrate that integrating risk-aware metrics during training enhances the Transformers' risk assessment capabilities while preserving their core strengths in decision-making and reasoning across diverse scenarios.
Dynamic Weight Adjusting Deep Q-Networks for Real-Time Environmental Adaptation
Nov 04, 2024



Deep Reinforcement Learning has shown excellent performance in generating efficient solutions for complex tasks. However, its efficacy is often limited by static training modes and heavy reliance on vast data from stable environments. To address these shortcomings, this study explores integrating dynamic weight adjustments into Deep Q-Networks (DQN) to enhance their adaptability. We implement these adjustments by modifying the sampling probabilities in the experience replay to make the model focus more on pivotal transitions as indicated by real-time environmental feedback and performance metrics. We design a novel Interactive Dynamic Evaluation Method (IDEM) for DQN that successfully navigates dynamic environments by prioritizing significant transitions based on environmental feedback and learning progress. Additionally, when faced with rapid changes in environmental conditions, IDEM-DQN shows improved performance compared to baseline methods. Our results indicate that under circumstances requiring rapid adaptation, IDEM-DQN can more effectively generalize and stabilize learning. Extensive experiments across various settings confirm that IDEM-DQN outperforms standard DQN models, particularly in environments characterized by frequent and unpredictable changes.
TIFG: Text-Informed Feature Generation with Large Language Models
Jun 17, 2024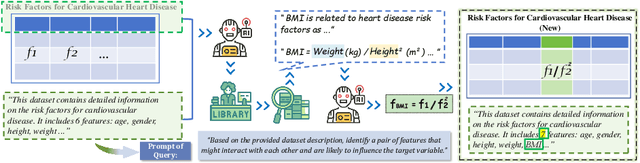
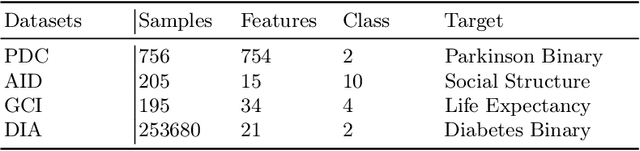
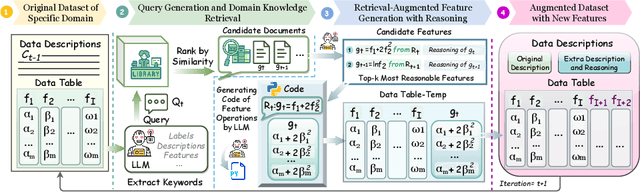

Textual information of data is of vital importance for data mining and feature engineering. However, existing methods focus on learning the data structures and overlook the textual information along with the data. Consequently, they waste this valuable resource and miss out on the deeper data relationships embedded within the texts. In this paper, we introduce Text-Informed Feature Generation (TIFG), a novel LLM-based text-informed feature generation framework. TIFG utilizes the textual information to generate features by retrieving possible relevant features within external knowledge with Retrieval Augmented Generation (RAG) technology. In this approach, the TIFG can generate new explainable features to enrich the feature space and further mine feature relationships. We design the TIFG to be an automated framework that continuously optimizes the feature generation process, adapts to new data inputs, and improves downstream task performance over iterations. A broad range of experiments in various downstream tasks showcases that our approach can generate high-quality and meaningful features, and is significantly superior to existing methods.