 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLM-5: from Vibe Coding to Agentic Engineering
Feb 17, 2026We present GLM-5, a next-generation foundation model designed to transition the paradigm of vibe coding to agentic engineering. Building upon the agentic, reasoning, and coding (ARC) capabilities of its predecessor, GLM-5 adopts DSA to significantly reduce training and inference costs while maintaining long-context fidelity. To advance model alignment and autonomy, we implement a new asynchronous reinforcement learning infrastructure that drastically improves post-training efficiency by decoupling generation from training. Furthermore, we propose novel asynchronous agent RL algorithms that further improve RL quality, enabling the model to learn from complex, long-horizon interactions more effectively. Through these innovations, GLM-5 achieves state-of-the-art performance on major open benchmarks. Most critically, GLM-5 demonstrates unprecedented capability in real-world coding tasks, surpassing previous baselines in handling end-to-end software engineering challenges. Code, models, and more information are available at https://github.com/zai-org/GLM-5.
Debate over Mixed-knowledge: A Robust Multi-Agent Framework for Incomplete Knowledge Graph Question Answering
Nov 15, 2025Knowledge Graph Question Answering (KGQA) aims to improve factual accuracy by leveraging structured knowledge. However, real-world Knowledge Graphs (KGs) are often incomplete, leading to the problem of Incomplete KGQA (IKGQA). A common solution is to incorporate external data to fill knowledge gaps, but existing methods lack the capacity to adaptively and contextually fuse multiple sources, failing to fully exploit their complementary strengths. To this end, we propose Debate over Mixed-knowledge (DoM), a novel framework that enables dynamic integration of structured and unstructured knowledge for IKGQA. Built upon the Multi-Agent Debate paradigm, DoM assigns specialized agents to perform inference over knowledge graphs and external texts separately, and coordinates their outputs through iterative interaction. It decomposes the input question into sub-questions, retrieves evidence via dual agents (KG and Retrieval-Augmented Generation, RAG), and employs a judge agent to evaluate and aggregate intermediate answers. This collaboration exploits knowledge complementarity and enhances robustness to KG incompleteness. In addition, existing IKGQA datasets simulate incompleteness by randomly removing triples, failing to capture the irregular and unpredictable nature of real-world knowledge incompleteness. To address this, we introduce a new dataset, Incomplete Knowledge Graph WebQuestions, constructed by leveraging real-world knowledge updates. These updates reflect knowledge beyond the static scope of KGs, yielding a more realistic and challenging benchmark. Through extensive experiments, we show that DoM consistently outperforms state-of-the-art baselines.
Distributed Graph Neural Network Inference With Just-In-Time Compilation For Industry-Scale Graphs
Mar 08, 2025Graph neural networks (GNNs) have delivered remarkable results in various fields. However, the rapid increase in the scale of graph data has introduced significant performance bottlenecks for GNN inference. Both computational complexity and memory usage have risen dramatically, with memory becoming a critical limitation. Although graph sampling-based subgraph learning methods can help mitigate computational and memory demands, they come with drawbacks such as information loss and high redundant computation among subgraphs. This paper introduces an innovative processing paradgim for distributed graph learning that abstracts GNNs with a new set of programming interfaces and leverages Just-In-Time (JIT) compilation technology to its full potential. This paradigm enables GNNs to highly exploit the computational resources of distributed clusters by eliminating the drawbacks of subgraph learning methods, leading to a more efficient inference process. Our experimental results demonstrate that on industry-scale graphs of up to \textbf{500 million nodes and 22.4 billion edges}, our method can produce a performance boost of up to \textbf{27.4 times}.
Wavelet-based Mamba with Fourier Adjustment for Low-light Image Enhancement
Oct 27, 2024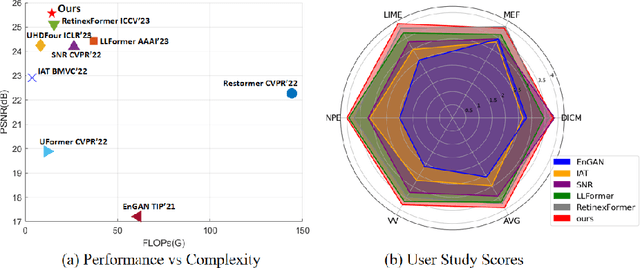
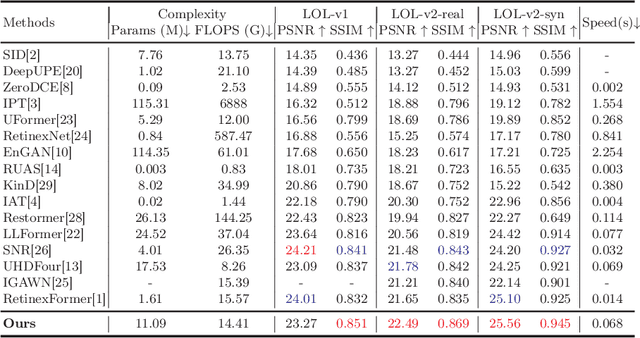
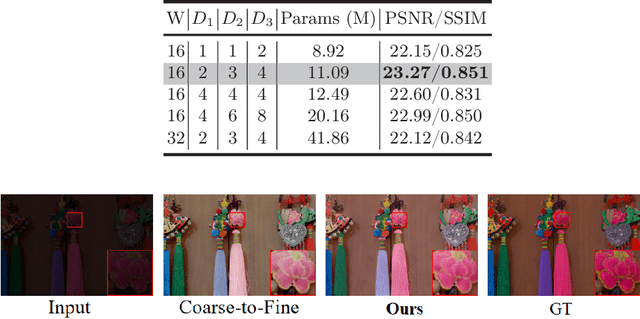
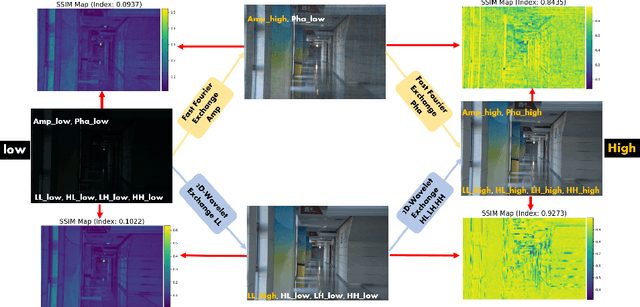
Frequency information (e.g., Discrete Wavelet Transform and Fast Fourier Transform) has been widely applied to solve the issue of Low-Light Image Enhancement (LLIE). However, existing frequency-based models primarily operate in the simple wavelet or Fourier space of images, which lacks utilization of valid global and local information in each space. We found that wavelet frequency information is more sensitive to global brightness due to its low-frequency component while Fourier frequency information is more sensitive to local details due to its phase component. In order to achieve superior preliminary brightness enhancement by optimally integrating spatial channel information with low-frequency components in the wavelet transform, we introduce channel-wise Mamba, which compensates for the long-range dependencies of CNNs and has lower complexity compared to Diffusion and Transformer models. So in this work, we propose a novel Wavelet-based Mamba with Fourier Adjustment model called WalMaFa, consisting of a Wavelet-based Mamba Block (WMB) and a Fast Fourier Adjustment Block (FFAB). We employ an Encoder-Latent-Decoder structure to accomplish the end-to-end transformation. Specifically, WMB is adopted in the Encoder and Decoder to enhance global brightness while FFAB is adopted in the Latent to fine-tune local texture details and alleviate ambiguity. Extensive experiments demonstrate that our proposed WalMaFa achieves state-of-the-art performance with fewer computational resources and faster speed. Code is now available at: https://github.com/mcpaulgeorge/WalMaFa.
Gradient-Aware Logit Adjustment Loss for Long-tailed Classifier
Mar 14, 2024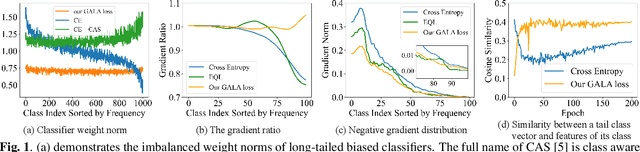

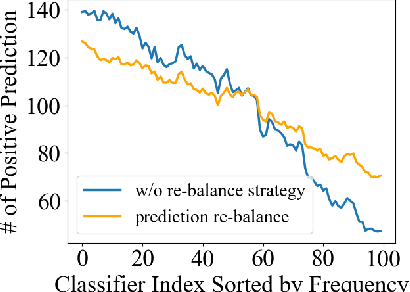

In the real-world setting, data often follows a long-tailed distribution, where head classes contain significantly more training samples than tail classes. Consequently, models trained on such data tend to be biased toward head classes. The medium of this bias is imbalanced gradients, which include not only the ratio of scale between positive and negative gradients but also imbalanced gradients from different negative classes. Therefore, we propose the Gradient-Aware Logit Adjustment (GALA) loss, which adjusts the logits based on accumulated gradients to balance the optimization process. Additionally, We find that most of the solutions to long-tailed problems are still biased towards head classes in the end, and we propose a simple and post hoc prediction re-balancing strategy to further mitigate the basis toward head class. Extensive experiments are conducted on multiple popular long-tailed recognition benchmark datasets to evaluate the effectiveness of these two designs. Our approach achieves top-1 accuracy of 48.5\%, 41.4\%, and 73.3\% on CIFAR100-LT, Places-LT, and iNaturalist, outperforming the state-of-the-art method GCL by a significant margin of 3.62\%, 0.76\% and 1.2\%, respectively. Code is available at https://github.com/lt-project-repository/lt-project.
Analyzing and Reducing Catastrophic Forgetting in Parameter Efficient Tuning
Feb 29, 2024Existing research has shown that large language models (LLMs) exhibit remarkable performance in language understanding and generation. However, when LLMs are continuously fine-tuned on complex and diverse domain-specific downstream tasks, the inference performance on historical tasks decreases dramatically, which is known as a catastrophic forgetting problem. A trade-off needs to be kept between learning plasticity and memory stability. Plenty of existing works have explored strategies like memory replay, regularization and parameter isolation, but little is known about the geometric connection of various adjacent minima in the continual LLMs fine-tuning scenarios. In this work, we investigate the geometric connections of different minima through the lens of mode connectivity, which means different minima can be connected by a low-loss valley. Through extensive experiments, we uncover the mode connectivity phenomenon in the LLMs continual learning scenario and find that it can strike a balance between plasticity and stability. Building upon these findings, we propose a simple yet effective method called Interpolation-based LoRA (I-LoRA), which constructs a dual-memory experience replay framework based on LoRA parameter interpolations. Extensive experiments and analysis on eight domain-specific CL benchmarks demonstrate that I-LoRA consistently show significant improvement over the previous state-of-the-art approaches with up to $11\%$ performance gains, providing a strong baseline and insights for future research on the large language model continual learning problem. Our code is available at \url{https://github.com/which47/LLMCL}.
Improving Zero-shot Visual Question Answering via Large Language Models with Reasoning Question Prompts
Nov 15, 2023



Zero-shot Visual Question Answering (VQA) is a prominent vision-language task that examines both the visual and textual understanding capability of systems in the absence of training data. Recently, by converting the images into captions, information across multi-modalities is bridged and Large Language Models (LLMs) can apply their strong zero-shot generalization capability to unseen questions. To design ideal prompts for solving VQA via LLMs, several studies have explored different strategies to select or generate question-answer pairs as the exemplar prompts, which guide LLMs to answer the current questions effectively. However, they totally ignore the role of question prompts. The original questions in VQA tasks usually encounter ellipses and ambiguity which require intermediate reasoning. To this end, we present Reasoning Question Prompts for VQA tasks, which can further activate the potential of LLMs in zero-shot scenarios. Specifically, for each question, we first generate self-contained questions as reasoning question prompts via an unsupervised question edition module considering sentence fluency, semantic integrity and syntactic invariance. Each reasoning question prompt clearly indicates the intent of the original question. This results in a set of candidate answers. Then, the candidate answers associated with their confidence scores acting as answer heuristics are fed into LLMs and produce the final answer. We evaluate reasoning question prompts on three VQA challenges, experimental results demonstrate that they can significantly improve the results of LLMs on zero-shot setting and outperform existing state-of-the-art zero-shot methods on three out of four data sets. Our source code is publicly released at \url{https://github.com/ECNU-DASE-NLP/RQP}.
T-SaS: Toward Shift-aware Dynamic Adaptation for Streaming Data
Sep 05, 2023



In many real-world scenarios, distribution shifts exist in the streaming data across time steps. Many complex sequential data can be effectively divided into distinct regimes that exhibit persistent dynamics. Discovering the shifted behaviors and the evolving patterns underlying the streaming data are important to understand the dynamic system. Existing methods typically train one robust model to work for the evolving data of distinct distributions or sequentially adapt the model utilizing explicitly given regime boundaries. However, there are two challenges: (1) shifts in data streams could happen drastically and abruptly without precursors. Boundaries of distribution shifts are usually unavailable, and (2) training a shared model for all domains could fail to capture varying patterns. This paper aims to solve the problem of sequential data modeling in the presence of sudden distribution shifts that occur without any precursors. Specifically, we design a Bayesian framework, dubbed as T-SaS, with a discrete distribution-modeling variable to capture abrupt shifts of data. Then, we design a model that enable adaptation with dynamic network selection conditioned on that discrete variable. The proposed method learns specific model parameters for each distribution by learning which neurons should be activated in the full network. A dynamic masking strategy is adopted here to support inter-distribution transfer through the overlapping of a set of sparse networks. Extensive experiments show that our proposed method is superior in both accurately detecting shift boundaries to get segments of varying distributions and effectively adapting to downstream forecast or classification tasks.
Graph Relation Aware Continual Learning
Aug 16, 2023



Continual graph learning (CGL) studies the problem of learning from an infinite stream of graph data, consolidating historical knowledge, and generalizing it to the future task. At once, only current graph data are available. Although some recent attempts have been made to handle this task, we still face two potential challenges: 1) most of existing works only manipulate on the intermediate graph embedding and ignore intrinsic properties of graphs. It is non-trivial to differentiate the transferred information across graphs. 2) recent attempts take a parameter-sharing policy to transfer knowledge across time steps or progressively expand new architecture given shifted graph distribution. Learning a single model could loss discriminative information for each graph task while the model expansion scheme suffers from high model complexity. In this paper, we point out that latent relations behind graph edges can be attributed as an invariant factor for the evolving graphs and the statistical information of latent relations evolves. Motivated by this, we design a relation-aware adaptive model, dubbed as RAM-CG, that consists of a relation-discovery modular to explore latent relations behind edges and a task-awareness masking classifier to accounts for the shifted. Extensive experiments show that RAM-CG provides significant 2.2%, 6.9% and 6.6% accuracy improvements over the state-of-the-art results on CitationNet, OGBN-arxiv and TWITCH dataset, respective.
Read, Diagnose and Chat: Towards Explainable and Interactive LLMs-Augmented Depression Detection in Social Media
May 09, 2023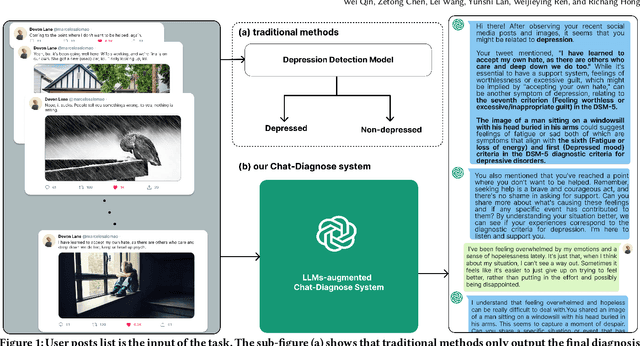
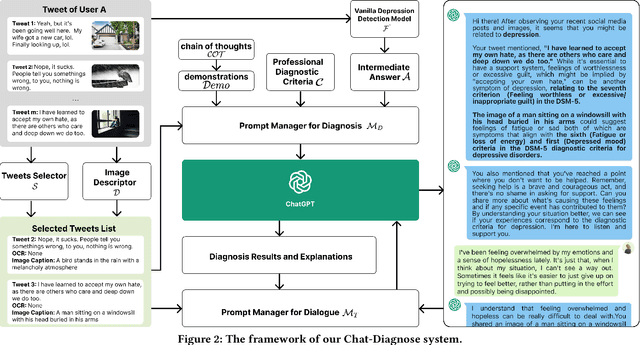
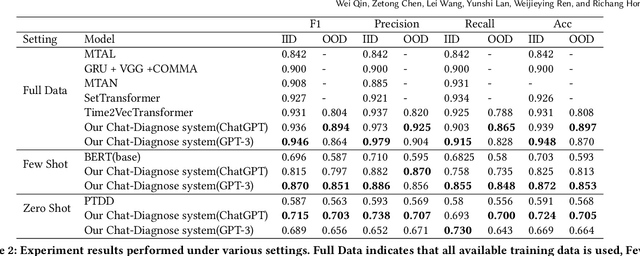
This paper proposes a new depression detection system based on LLMs that is both interpretable and interactive. It not only provides a diagnosis, but also diagnostic evidence and personalized recommendations based on natural language dialogue with the user. We address challenges such as the processing of large amounts of text and integrate professional diagnostic criteria. Our system outperforms traditional methods across various settings and is demonstrated through case studies.