 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-Aware Logit Adjustment Loss for Long-tailed Classifier
Paper and Code
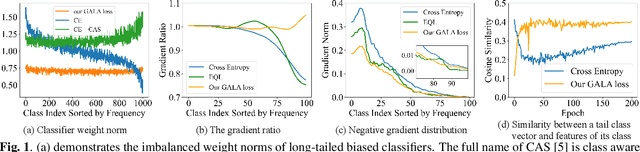

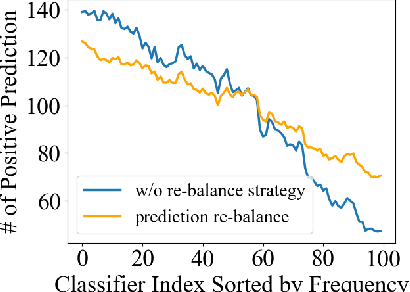

In the real-world setting, data often follows a long-tailed distribution, where head classes contain significantly more training samples than tail classes. Consequently, models trained on such data tend to be biased toward head classes. The medium of this bias is imbalanced gradients, which include not only the ratio of scale between positive and negative gradients but also imbalanced gradients from different negative classes. Therefore, we propose the Gradient-Aware Logit Adjustment (GALA) loss, which adjusts the logits based on accumulated gradients to balance the optimization process. Additionally, We find that most of the solutions to long-tailed problems are still biased towards head classes in the end, and we propose a simple and post hoc prediction re-balancing strategy to further mitigate the basis toward head class. Extensive experiments are conducted on multiple popular long-tailed recognition benchmark datasets to evaluate the effectiveness of these two designs. Our approach achieves top-1 accuracy of 48.5\%, 41.4\%, and 73.3\% on CIFAR100-LT, Places-LT, and iNaturalist, outperforming the state-of-the-art method GCL by a significant margin of 3.62\%, 0.76\% and 1.2\%, respectively. Code is available at https://github.com/lt-project-repository/lt-project.