 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWavelet-based Mamba with Fourier Adjustment for Low-light Image Enhancement
Oct 27, 2024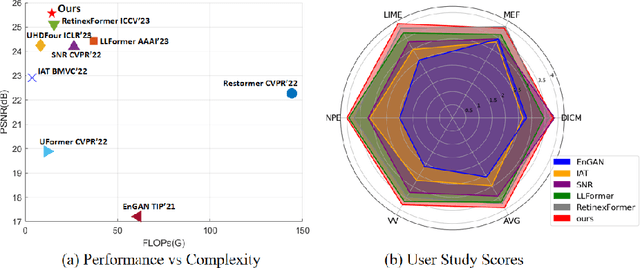
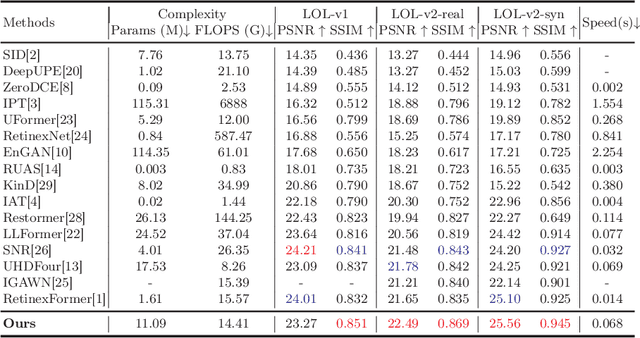
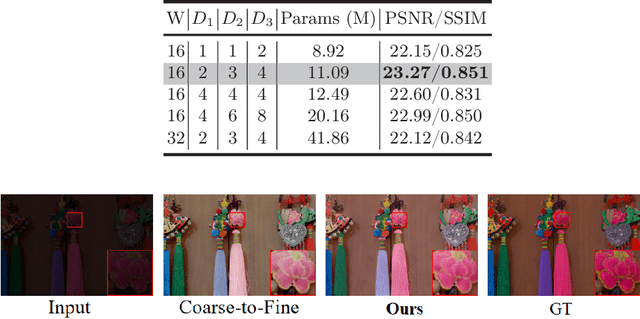
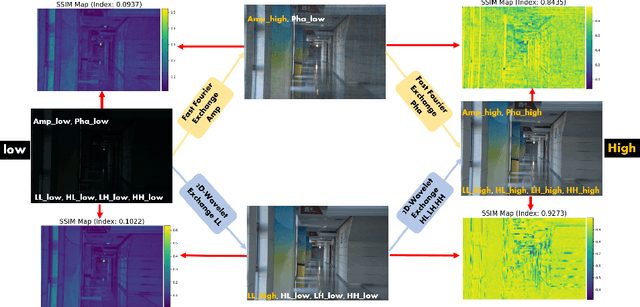
Frequency information (e.g., Discrete Wavelet Transform and Fast Fourier Transform) has been widely applied to solve the issue of Low-Light Image Enhancement (LLIE). However, existing frequency-based models primarily operate in the simple wavelet or Fourier space of images, which lacks utilization of valid global and local information in each space. We found that wavelet frequency information is more sensitive to global brightness due to its low-frequency component while Fourier frequency information is more sensitive to local details due to its phase component. In order to achieve superior preliminary brightness enhancement by optimally integrating spatial channel information with low-frequency components in the wavelet transform, we introduce channel-wise Mamba, which compensates for the long-range dependencies of CNNs and has lower complexity compared to Diffusion and Transformer models. So in this work, we propose a novel Wavelet-based Mamba with Fourier Adjustment model called WalMaFa, consisting of a Wavelet-based Mamba Block (WMB) and a Fast Fourier Adjustment Block (FFAB). We employ an Encoder-Latent-Decoder structure to accomplish the end-to-end transformation. Specifically, WMB is adopted in the Encoder and Decoder to enhance global brightness while FFAB is adopted in the Latent to fine-tune local texture details and alleviate ambiguity. Extensive experiments demonstrate that our proposed WalMaFa achieves state-of-the-art performance with fewer computational resources and faster speed. Code is now available at: https://github.com/mcpaulgeorge/WalMaFa.
Why Misinformation is Created? Detecting them by Integrating Intent Features
Jul 27, 2024



Various social media platforms, e.g., Twitter and Reddit, allow people to disseminate a plethora of information more efficiently and conveniently. However, they are inevitably full of misinformation, causing damage to diverse aspects of our daily lives. To reduce the negative impact, timely identification of misinformation, namely Misinformation Detection (MD), has become an active research topic receiving widespread attention. As a complex phenomenon, the veracity of an article is influenced by various aspects. In this paper, we are inspired by the opposition of intents between misinformation and real information. Accordingly, we propose to reason the intent of articles and form the corresponding intent features to promote the veracity discrimination of article features. To achieve this, we build a hierarchy of a set of intents for both misinformation and real information by referring to the existing psychological theories, and we apply it to reason the intent of articles by progressively generating binary answers with an encoder-decoder structure. We form the corresponding intent features and integrate it with the token features to achieve more discriminative article features for MD. Upon these ideas, we suggest a novel MD method, namely Detecting Misinformation by Integrating Intent featuRes (DM-INTER). To evaluate the performance of DM-INTER, we conduct extensive experiments on benchmark MD datasets. The experimental results validate that DM-INTER can outperform the existing baseline MD methods.
Localized Traffic Sign Detection with Multi-scale Deconvolution Networks
May 03, 2018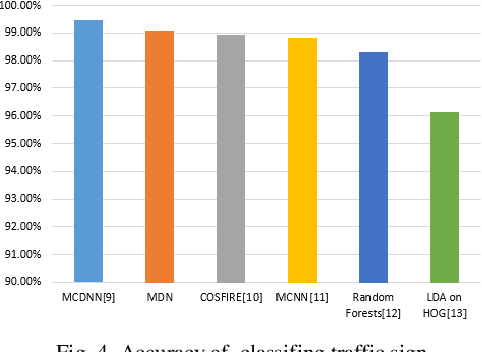
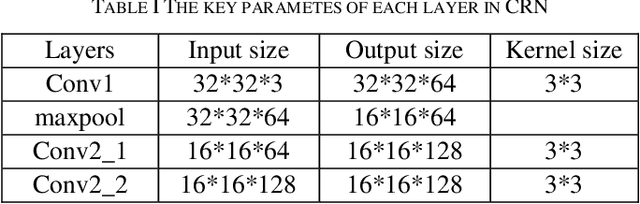
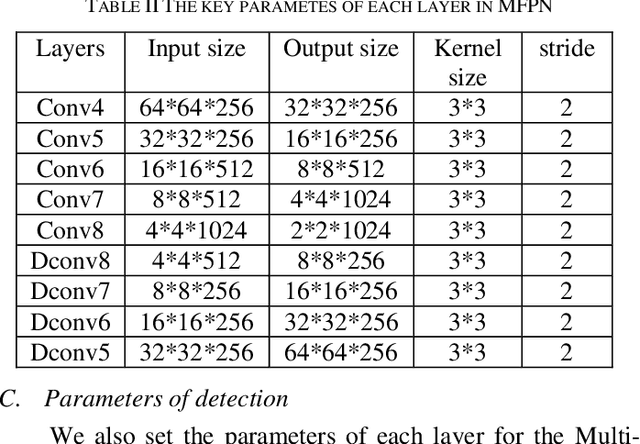
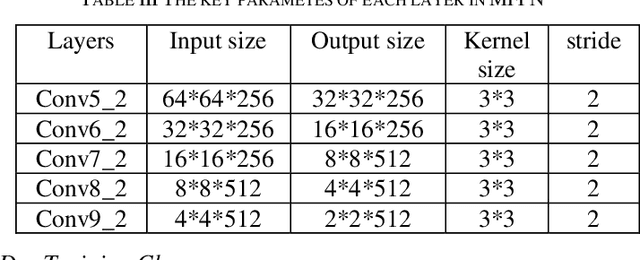
Autonomous driving is becoming a future practical lifestyle greatly driven by deep learning. Specifically, an effective traffic sign detection by deep learning plays a critical role for it. However, different countries have different sets of traffic signs, making localized traffic sign recognition model training a tedious and daunting task. To address the issues of taking amount of time to compute complicate algorithm and low ratio of detecting blurred and sub-pixel images of localized traffic signs, we propose Multi-Scale Deconvolution Networks (MDN), which flexibly combines multi-scale convolutional neural network with deconvolution sub-network, leading to efficient and reliable localized traffic sign recognition model training. It is demonstrated that the proposed MDN is effective compared with classical algorithms on the benchmarks of the localized traffic sign, such as Chinese Traffic Sign Dataset (CTSD), and the German Traffic Sign Benchmarks (GTSRB).
Teaching Autonomous Driving Using a Modular and Integrated Approach
Feb 27, 2018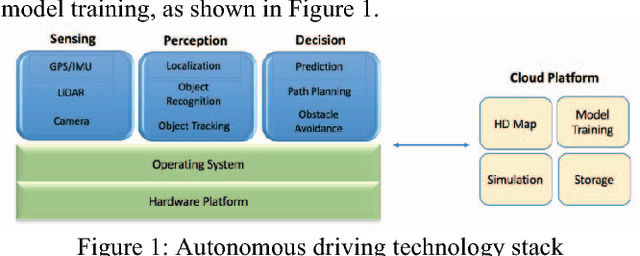

Autonomous driving is not one single technology but rather a complex system integrating many technologies, which means that teaching autonomous driving is a challenging task. Indeed, most existing autonomous driving classes focus on one of the technologies involved. This not only fails to provide a comprehensive coverage, but also sets a high entry barrier for students with different technology backgrounds. In this paper, we present a modular, integrated approach to teaching autonomous driving. Specifically, we organize the technologies used in autonomous driving into modules. This is described in the textbook we have developed as well as a series of multimedia online lectures designed to provide technical overview for each module. Then, once the students have understood these modules, the experimental platforms for integration we have developed allow the students to fully understand how the modules interact with each other. To verify this teaching approach, we present three case studies: an introductory class on autonomous driving for students with only a basic technology background; a new session in an existing embedded systems class to demonstrate how embedded system technologies can be applied to autonomous driving; and an industry professional training session to quickly bring up experienced engineers to work in autonomous driving. The results show that students can maintain a high interest level and make great progress by starting with familiar concepts before moving onto other modules.