 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobots in the Wild: Contextually-Adaptive Human-Robot Interactions in Urban Public Environments
Dec 10, 2024


The increasing transition of human-robot interaction (HRI) context from controlled settings to dynamic, real-world public environments calls for enhanced adaptability in robotic systems. This can go beyond algorithmic navigation or traditional HRI strategies in structured settings, requiring the ability to navigate complex public urban systems containing multifaceted dynamics and various socio-technical needs. Therefore, our proposed workshop seeks to extend the boundaries of adaptive HRI research beyond predictable, semi-structured contexts and highlight opportunities for adaptable robot interactions in urban public environments. This half-day workshop aims to explore design opportunities and challenges in creating contextually-adaptive HRI within these spaces and establish a network of interested parties within the OzCHI research community. By fostering ongoing discussions, sharing of insights, and collaborations, we aim to catalyse future research that empowers robots to navigate the inherent uncertainties and complexities of real-world public interactions.
Learning with Partial Labels from Semi-supervised Perspective
Nov 30, 2022Partial Label (PL) learning refers to the task of learning from the partially labeled data, where each training instance is ambiguously equipped with a set of candidate labels but only one is valid. Advances in the recent deep PL learning literature have shown that the deep learning paradigms, e.g., self-training, contrastive learning, or class activate values, can achieve promising performance. Inspired by the impressive success of deep Semi-Supervised (SS) learning, we transform the PL learning problem into the SS learning problem, and propose a novel PL learning method, namely Partial Label learning with Semi-supervised Perspective (PLSP). Specifically, we first form the pseudo-labeled dataset by selecting a small number of reliable pseudo-labeled instances with high-confidence prediction scores and treating the remaining instances as pseudo-unlabeled ones. Then we design a SS learning objective, consisting of a supervised loss for pseudo-labeled instances and a semantic consistency regularization for pseudo-unlabeled instances. We further introduce a complementary regularization for those non-candidate labels to constrain the model predictions on them to be as small as possible. Empirical results demonstrate that PLSP significantly outperforms the existing PL baseline methods, especially on high ambiguity levels. Code available: https://github.com/changchunli/PLSP.
Generating Long Financial Report using Conditional Variational Autoencoders with Knowledge Distillation
Oct 23, 2020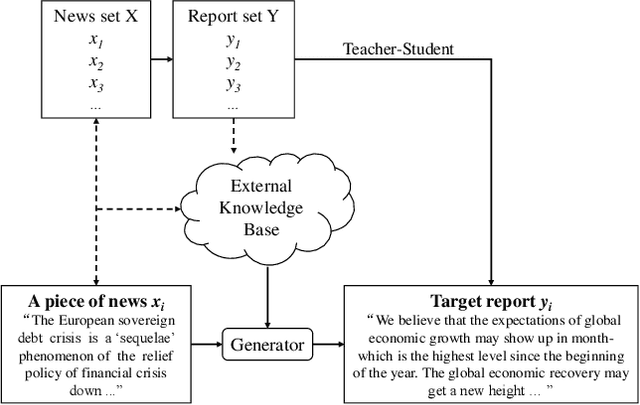
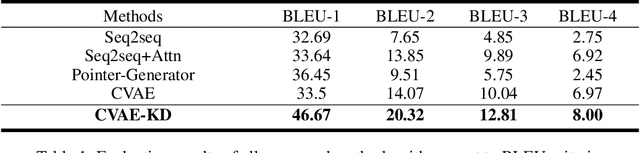
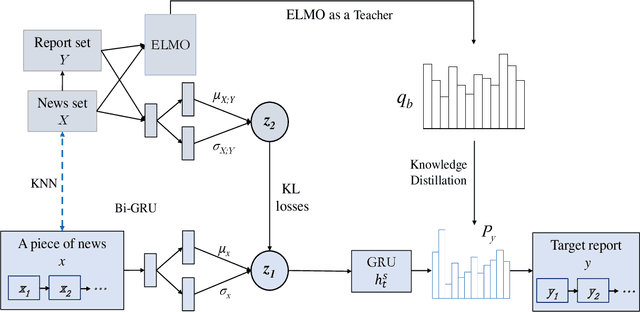

Automatically generating financial report from a piece of news is quite a challenging task. Apparently, the difficulty of this task lies in the lack of sufficient background knowledge to effectively generate long financial report. To address this issue, this paper proposes the conditional variational autoencoders (CVAE) based approach which distills external knowledge from a corpus of news-report data. Particularly, we choose Bi-GRU as the encoder and decoder component of CVAE, and learn the latent variable distribution from input news. A higher level latent variable distribution is learnt from a corpus set of news-report data, respectively extr acted for each input news, to provide background knowledge to previously learnt latent variable distribution. Then, a teacher-student network is employed to distill knowledge to refine theoutput of the decoder component. To evaluate the model performance of the proposed approach, extensive experiments are preformed on a public dataset and two widely adopted evaluation criteria, i.e., BLEU and ROUGE, are chosen in the experiment. The promising experimental results demonstrate that the proposed approach is superior to the rest compared methods.
Local Search for Minimum Weight Dominating Set with Two-Level Configuration Checking and Frequency Based Scoring Function
Feb 15, 2017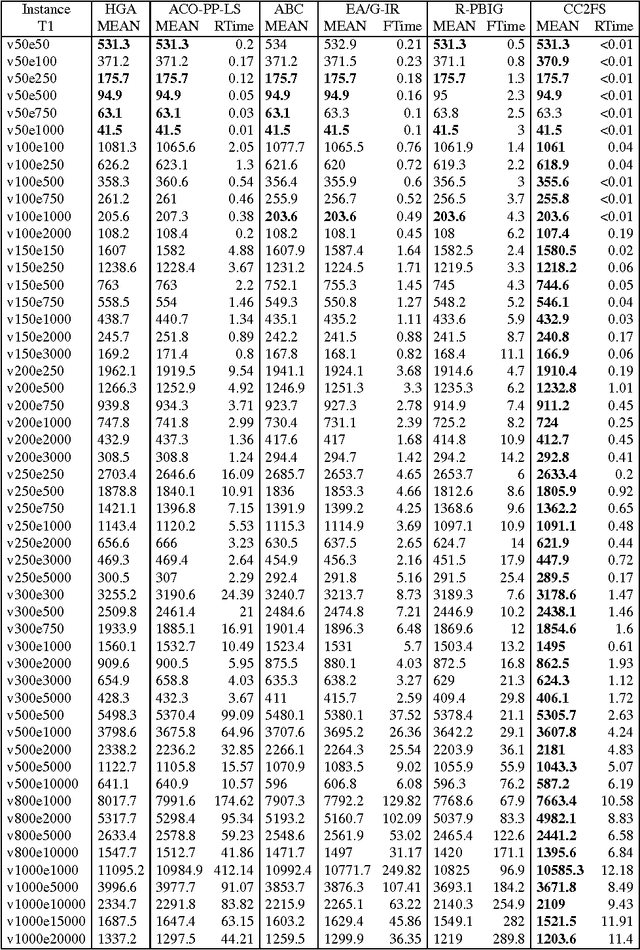
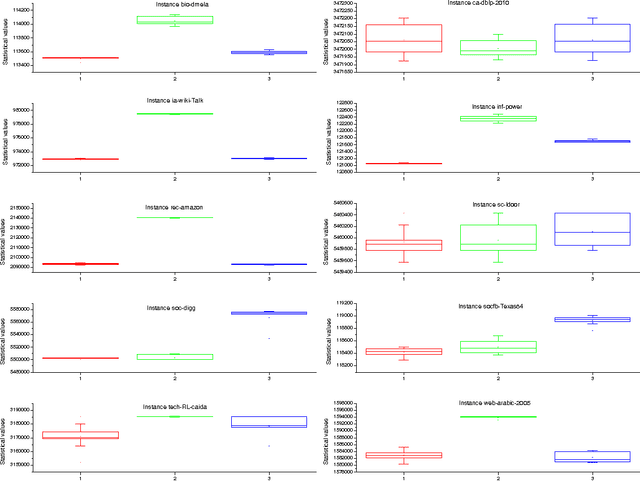
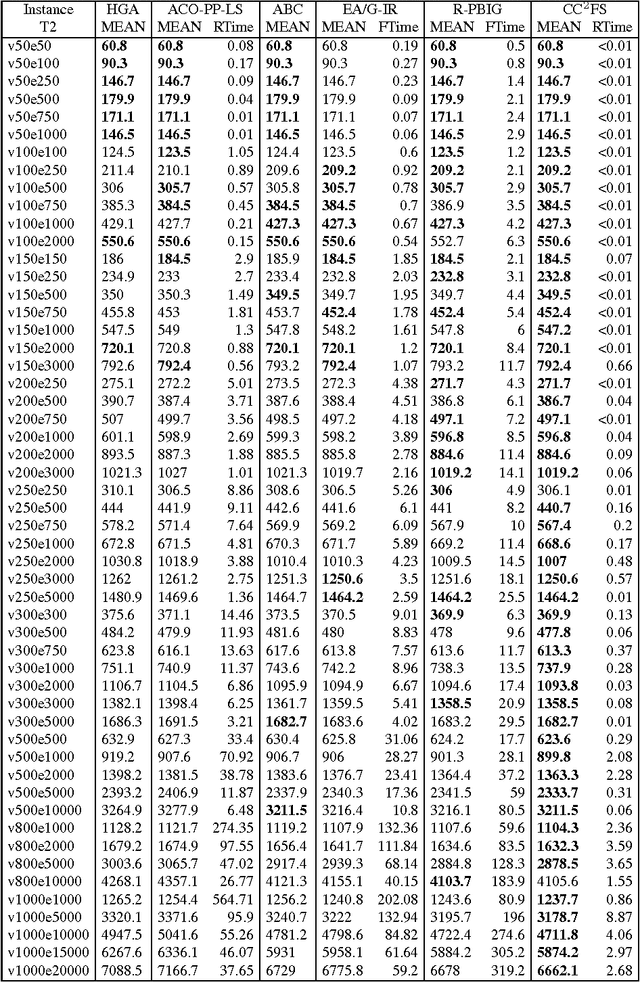
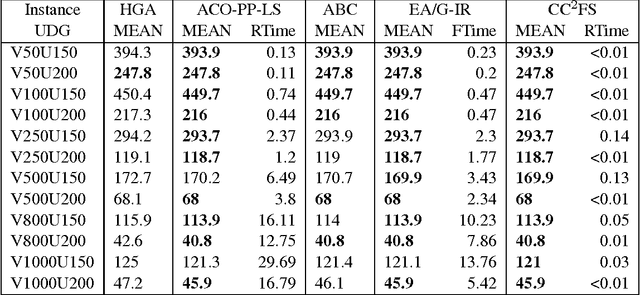
The Minimum Weight Dominating Set (MWDS) problem is an important generalization of the Minimum Dominating Set (MDS) problem with extensive applications. This paper proposes a new local search algorithm for the MWDS problem, which is based on two new ideas. The first idea is a heuristic called two-level configuration checking (CC2), which is a new variant of a recent powerful configuration checking strategy (CC) for effectively avoiding the recent search paths. The second idea is a novel scoring function based on the frequency of being uncovered of vertices. Our algorithm is called CC2FS, according to the names of the two ideas. The experimental results show that, CC2FS performs much better than some state-of-the-art algorithms in terms of solution quality on a broad range of MWDS benchmarks.
* 29 pages, 1 figure