 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion-aware Memory Network for Fast Video Salient Object Detection
Paper and Code
Aug 01, 2022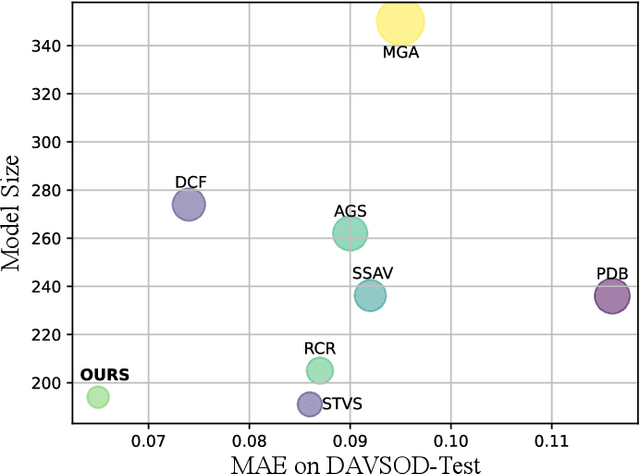

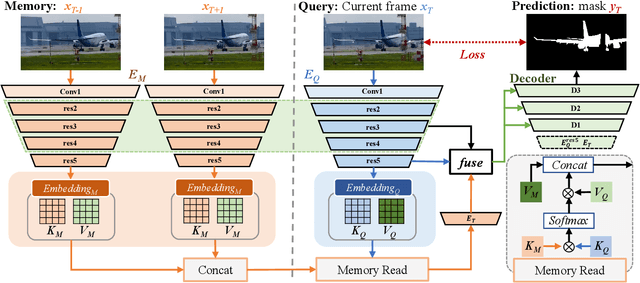
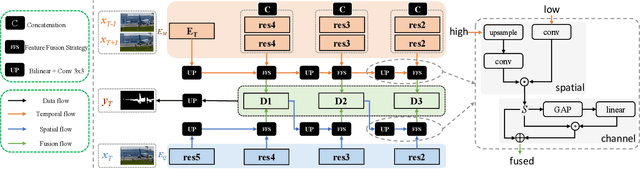
Previous methods based on 3DCNN, convLSTM, or optical flow have achieved great success in video salient object detection (VSOD). However, they still suffer from high computational costs or poor quality of the generated saliency maps. To solve these problems, we design a space-time memory (STM)-based network, which extracts useful temporal information of the current frame from adjacent frames as the temporal branch of VSOD. Furthermore, previous methods only considered single-frame prediction without temporal association. As a result, the model may not focus on the temporal information sufficiently. Thus, we initially introduce object motion prediction between inter-frame into VSOD. Our model follows standard encoder--decoder architecture. In the encoding stage, we generate high-level temporal features by using high-level features from the current and its adjacent frames. This approach is more efficient than the optical flow-based methods. In the decoding stage, we propose an effective fusion strategy for spatial and temporal branches. The semantic information of the high-level features is used to fuse the object details in the low-level features, and then the spatiotemporal features are obtained step by step to reconstruct the saliency maps. Moreover, inspired by the boundary supervision commonly used in image salient object detection (ISOD), we design a motion-aware loss for predicting object boundary motion and simultaneously perform multitask learning for VSOD and object motion prediction, which can further facilitate the model to extract spatiotemporal features accurately and maintain the object integrity. Extensive experiments on several datasets demonstrated the effectiveness of our method and can achieve state-of-the-art metrics on some datasets. The proposed model does not require optical flow or other preprocessing, and can reach a speed of nearly 100 FPS during inference.