 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised makeup transfer with a curated dataset: Decoupling identity and makeup features for enhanced transformation
Jan 31, 2026Diffusion models have recently shown strong progress in generative tasks, offering a more stable alternative to GAN-based approaches for makeup transfer. Existing methods often suffer from limited datasets, poor disentanglement between identity and makeup features, and weak controllability. To address these issues, we make three contributions. First, we construct a curated high-quality dataset using a train-generate-filter-retrain strategy that combines synthetic, realistic, and filtered samples to improve diversity and fidelity. Second, we design a diffusion-based framework that disentangles identity and makeup features, ensuring facial structure and skin tone are preserved while applying accurate and diverse cosmetic styles. Third, we propose a text-guided mechanism that allows fine-grained and region-specific control, enabling users to modify eyes, lips, or face makeup with natural language prompts. Experiments on benchmarks and real-world scenarios demonstrate improvements in fidelity, identity preservation, and flexibility. Examples of our dataset can be found at: https://makeup-adapter.github.io.
InfoAffect: A Dataset for Affective Analysis of Infographics
Nov 09, 2025Infographics are widely used to convey complex information, yet their affective dimensions remain underexplored due to the scarcity of data resources. We introduce a 3.5k-sample affect-annotated InfoAffect dataset, which combines textual content with real-world infographics. We first collect the raw data from six domains and aligned them via preprocessing, the accompanied-text-priority method, and three strategies to guarantee the quality and compliance. After that we construct an affect table and use it to constrain annotation. Five state-of-the-art multimodal large language models (MLLMs) then analyze both modalities, and their outputs are fused with Reciprocal Rank Fusion (RRF) algorithm to yield robust affects and confidences. We conducted a user study with two experiments to validate usability and assess InfoAffect dataset using the Composite Affect Consistency Index (CACI), achieving an overall score of 0.986, which indicates high accuracy.
C5: Towards Better Conversation Comprehension and Contextual Continuity for ChatGPT
Aug 10, 2023



Large language models (LLMs), such as ChatGPT, have demonstrated outstanding performance in various fields, particularly in natural language understanding and generation tasks. In complex application scenarios, users tend to engage in multi-turn conversations with ChatGPT to keep contextual information and obtain comprehensive responses. However, human forgetting and model contextual forgetting remain prominent issues in multi-turn conversation scenarios, which challenge the users' conversation comprehension and contextual continuity for ChatGPT. To address these challenges, we propose an interactive conversation visualization system called C5, which includes Global View, Topic View, and Context-associated Q\&A View. The Global View uses the GitLog diagram metaphor to represent the conversation structure, presenting the trend of conversation evolution and supporting the exploration of locally salient features. The Topic View is designed to display all the question and answer nodes and their relationships within a topic using the structure of a knowledge graph, thereby display the relevance and evolution of conversations. The Context-associated Q\&A View consists of three linked views, which allow users to explore individual conversations deeply while providing specific contextual information when posing questions. The usefulness and effectiveness of C5 were evaluated through a case study and a user study.
Motion-aware Memory Network for Fast Video Salient Object Detection
Aug 01, 2022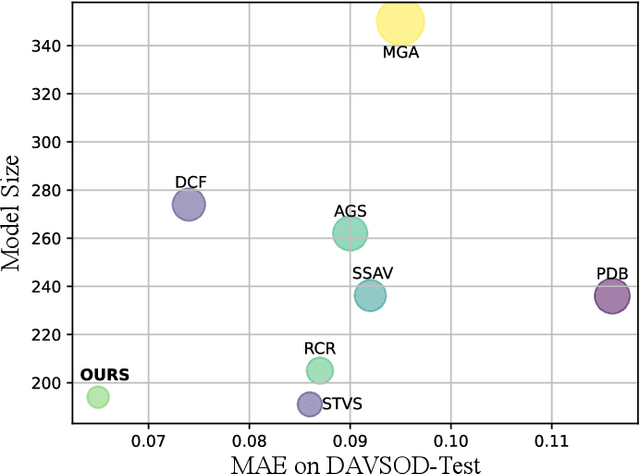

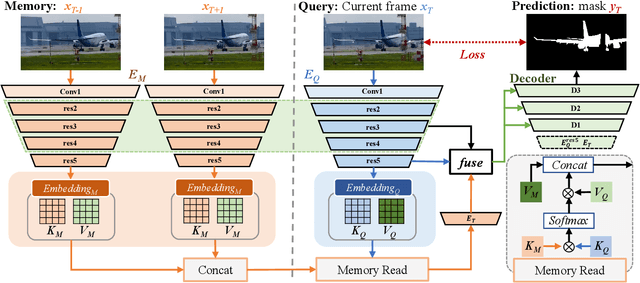
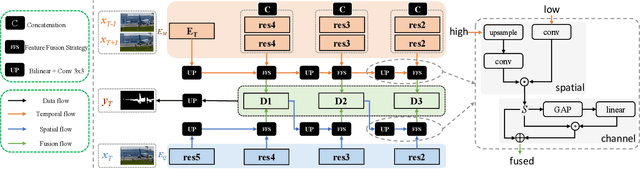
Previous methods based on 3DCNN, convLSTM, or optical flow have achieved great success in video salient object detection (VSOD). However, they still suffer from high computational costs or poor quality of the generated saliency maps. To solve these problems, we design a space-time memory (STM)-based network, which extracts useful temporal information of the current frame from adjacent frames as the temporal branch of VSOD. Furthermore, previous methods only considered single-frame prediction without temporal association. As a result, the model may not focus on the temporal information sufficiently. Thus, we initially introduce object motion prediction between inter-frame into VSOD. Our model follows standard encoder--decoder architecture. In the encoding stage, we generate high-level temporal features by using high-level features from the current and its adjacent frames. This approach is more efficient than the optical flow-based methods. In the decoding stage, we propose an effective fusion strategy for spatial and temporal branches. The semantic information of the high-level features is used to fuse the object details in the low-level features, and then the spatiotemporal features are obtained step by step to reconstruct the saliency maps. Moreover, inspired by the boundary supervision commonly used in image salient object detection (ISOD), we design a motion-aware loss for predicting object boundary motion and simultaneously perform multitask learning for VSOD and object motion prediction, which can further facilitate the model to extract spatiotemporal features accurately and maintain the object integrity. Extensive experiments on several datasets demonstrated the effectiveness of our method and can achieve state-of-the-art metrics on some datasets. The proposed model does not require optical flow or other preprocessing, and can reach a speed of nearly 100 FPS during inference.
VAC2: Visual Analysis of Combined Causality in Event Sequences
Jun 11, 2022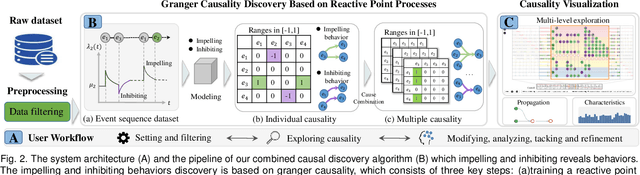
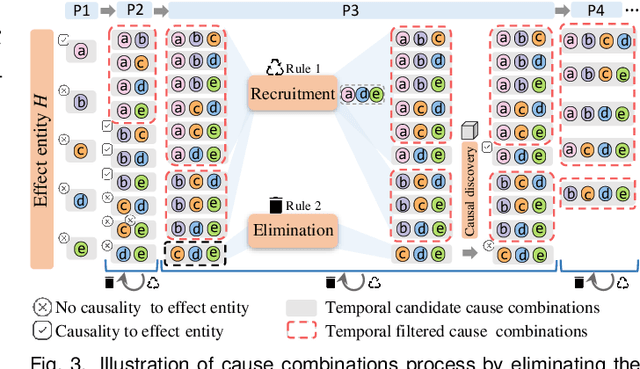

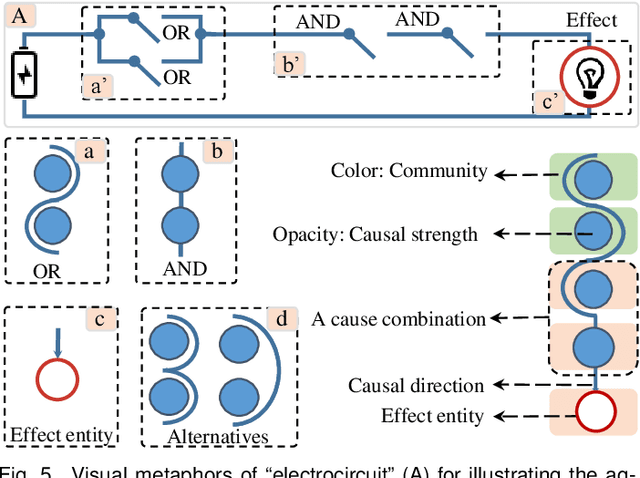
Identifying causality behind complex systems plays a significant role in different domains, such as decision making, policy implementations, and management recommendations. However, existing causality studies on temporal event sequences data mainly focus on individual causal discovery, which is incapable of exploiting combined causality. To fill the absence of combined causes discovery on temporal event sequence data,eliminating and recruiting principles are defined to balance the effectiveness and controllability on cause combinations. We also leverage the Granger causality algorithm based on the reactive point processes to describe impelling or inhibiting behavior patterns among entities. In addition, we design an informative and aesthetic visual metaphor of "electrocircuit" to encode aggregated causality for ensuring our causality visualization is non-overlapping and non-intersecting. Diverse sorting strategies and aggregation layout are also embedded into our parallel-based, directed and weighted hypergraph for illustrating combined causality. Our developed combined causality visual analysis system can help users effectively explore combined causes as well as an individual cause. This interactive system supports multi-level causality exploration with diverse ordering strategies and a focus and context technique to help users obtain different levels of information abstraction. The usefulness and effectiveness of the system are further evaluated by conducting a pilot user study and two case studies on event sequence data.