 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA General Visual Representation Guided Framework with Global Affinity for Weakly Supervised Salient Object Detection
Feb 21, 2023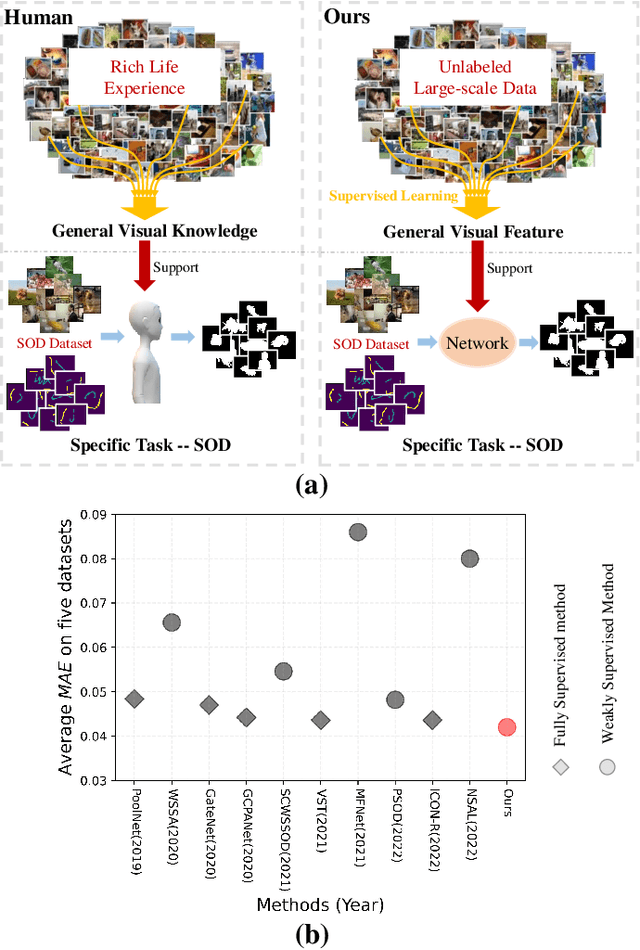
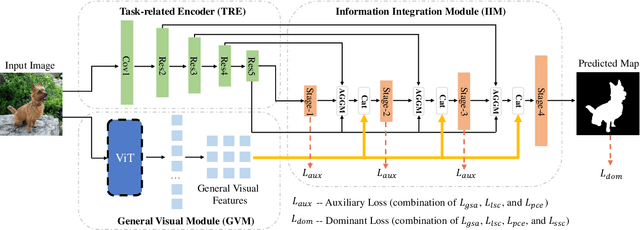

Fully supervised salient object detection (SOD) methods have made considerable progress in performance, yet these models rely heavily on expensive pixel-wise labels. Recently, to achieve a trade-off between labeling burden and performance, scribble-based SOD methods have attracted increasing attention. Previous models directly implement the SOD task only based on small-scale SOD training data. Due to the limited information provided by the weakly scribble tags and such small-scale training data, it is extremely difficult for them to understand the image and further achieve a superior SOD task. In this paper, we propose a simple yet effective framework guided by general visual representations that simulate the general cognition of humans for scribble-based SOD. It consists of a task-related encoder, a general visual module, and an information integration module to combine efficiently the general visual representations learned from large-scale unlabeled datasets with task-related features to perform the SOD task based on understanding the contextual connections of images. Meanwhile, we propose a novel global semantic affinity loss to guide the model to perceive the global structure of the salient objects. Experimental results on five public benchmark datasets demonstrate that our method that only utilizes scribble annotations without introducing any extra label outperforms the state-of-the-art weakly supervised SOD methods and is comparable or even superior to the state-of-the-art fully supervised models.
Learning Video Salient Object Detection Progressively from Unlabeled Videos
Apr 05, 2022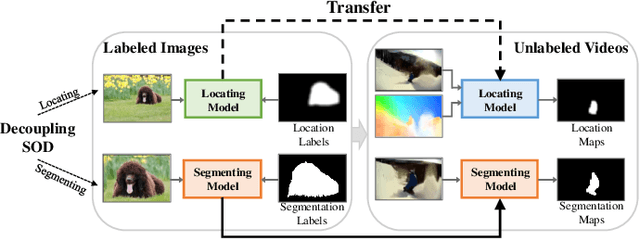
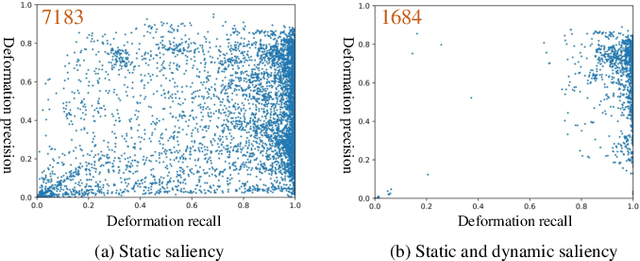
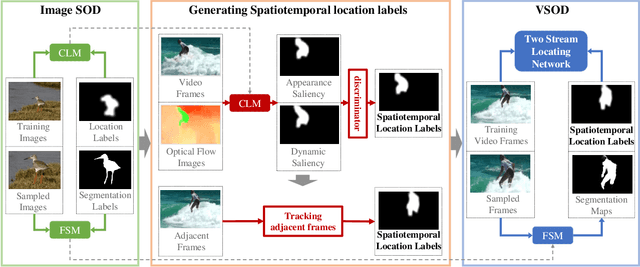
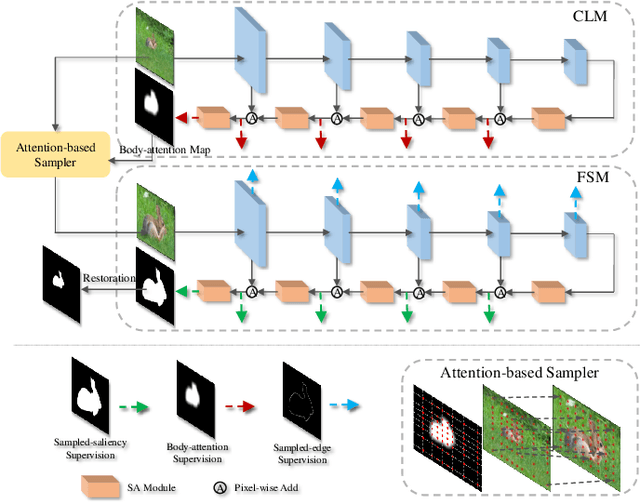
Recent deep learning-based video salient object detection (VSOD) has achieved some breakthrough, but these methods rely on expensive annotated videos with pixel-wise annotations, weak annotations, or part of the pixel-wise annotations. In this paper, based on the similarities and the differences between VSOD and image salient object detection (SOD), we propose a novel VSOD method via a progressive framework that locates and segments salient objects in sequence without utilizing any video annotation. To use the knowledge learned in the SOD dataset for VSOD efficiently, we introduce dynamic saliency to compensate for the lack of motion information of SOD during the locating process but retain the same fine segmenting process. Specifically, an algorithm for generating spatiotemporal location labels, which consists of generating high-saliency location labels and tracking salient objects in adjacent frames, is proposed. Based on these location labels, a two-stream locating network that introduces an optical flow branch for video salient object locating is presented. Although our method does not require labeled video at all, the experimental results on five public benchmarks of DAVIS, FBMS, ViSal, VOS, and DAVSOD demonstrate that our proposed method is competitive with fully supervised methods and outperforms the state-of-the-art weakly and unsupervised methods.