 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiN: Diffusion Model for Robust Medical VQA with Semantic Noisy Labels
Paper and Code
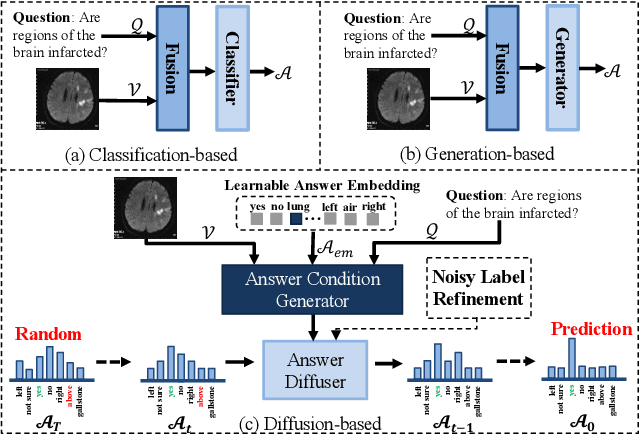
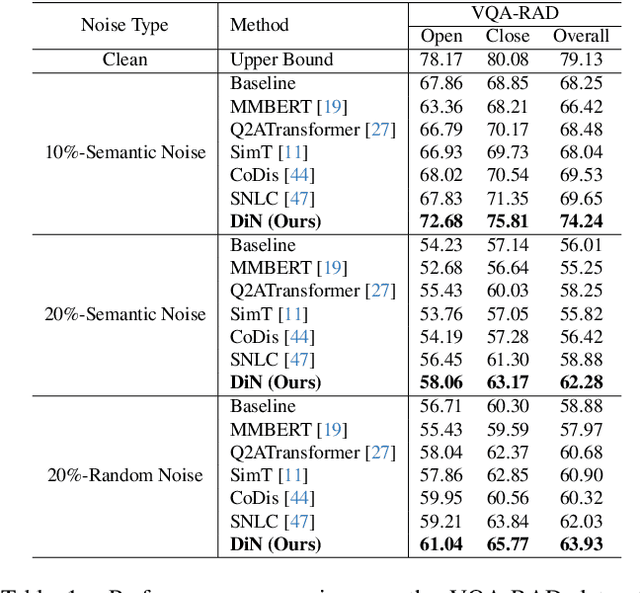
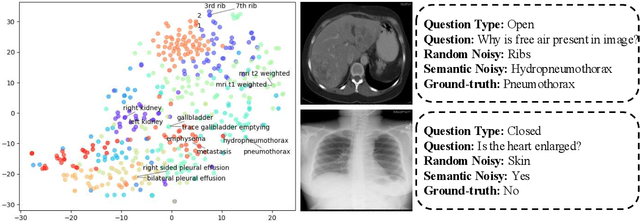
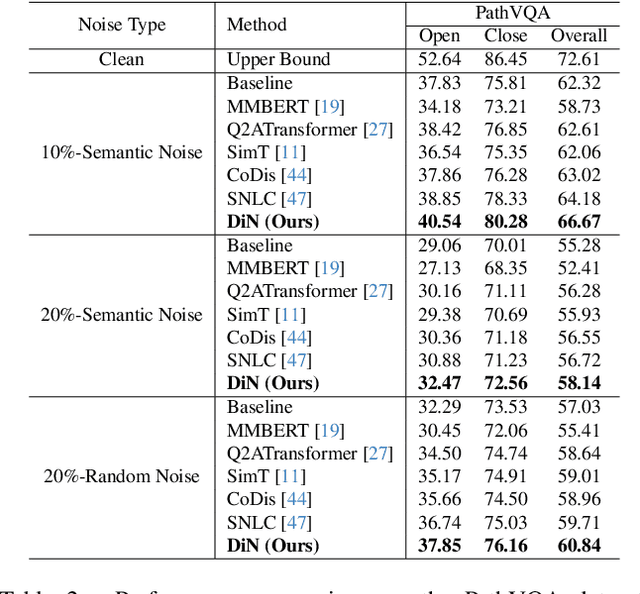
Medical Visual Question Answering (Med-VQA) systems benefit the interpretation of medical images containing critical clinical information. However, the challenge of noisy labels and limited high-quality datasets remains underexplored. To address this, we establish the first benchmark for noisy labels in Med-VQA by simulating human mislabeling with semantically designed noise types. More importantly, we introduce the DiN framework, which leverages a diffusion model to handle noisy labels in Med-VQA. Unlike the dominant classification-based VQA approaches that directly predict answers, our Answer Diffuser (AD) module employs a coarse-to-fine process, refining answer candidates with a diffusion model for improved accuracy. The Answer Condition Generator (ACG) further enhances this process by generating task-specific conditional information via integrating answer embeddings with fused image-question features. To address label noise, our Noisy Label Refinement(NLR) module introduces a robust loss function and dynamic answer adjustment to further boost the performance of the AD module.