 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptGAN: Optimizing and Interpreting the Latent Space of the Conditional Text-to-Image GANs
Paper and Code
Feb 25, 2022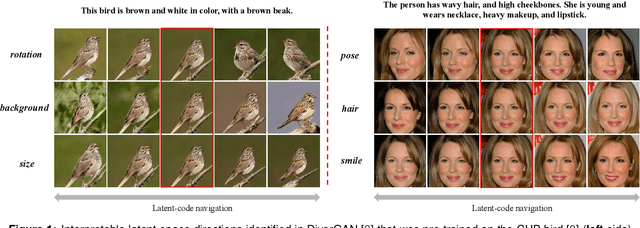

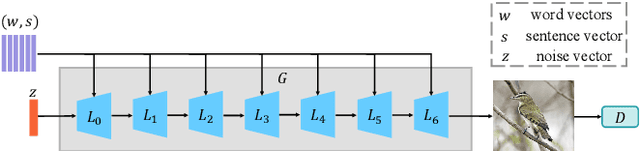
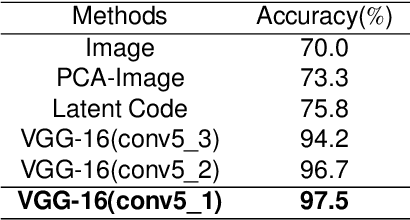
Text-to-image generation intends to automatically produce a photo-realistic image, conditioned on a textual description. It can be potentially employed in the field of art creation, data augmentation, photo-editing, etc. Although many efforts have been dedicated to this task, it remains particularly challenging to generate believable, natural scenes. To facilitate the real-world applications of text-to-image synthesis, we focus on studying the following three issues: 1) How to ensure that generated samples are believable, realistic or natural? 2) How to exploit the latent space of the generator to edit a synthesized image? 3) How to improve the explainability of a text-to-image generation framework? In this work, we constructed two novel data sets (i.e., the Good & Bad bird and face data sets) consisting of successful as well as unsuccessful generated samples, according to strict criteria. To effectively and efficiently acquire high-quality images by increasing the probability of generating Good latent codes, we use a dedicated Good/Bad classifier for generated images. It is based on a pre-trained front end and fine-tuned on the basis of the proposed Good & Bad data set. After that, we present a novel algorithm which identifies semantically-understandable directions in the latent space of a conditional text-to-image GAN architecture by performing independent component analysis on the pre-trained weight values of the generator. Furthermore, we develop a background-flattening loss (BFL), to improve the background appearance in the edited image. Subsequently, we introduce linear interpolation analysis between pairs of keywords. This is extended into a similar triangular `linguistic' interpolation in order to take a deep look into what a text-to-image synthesis model has learned within the linguistic embeddings. Our data set is available at https://zenodo.org/record/6283798#.YhkN_ujMI2w.