 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimized latent-code selection for explainable conditional text-to-image GANs
Paper and Code
Apr 27, 2022
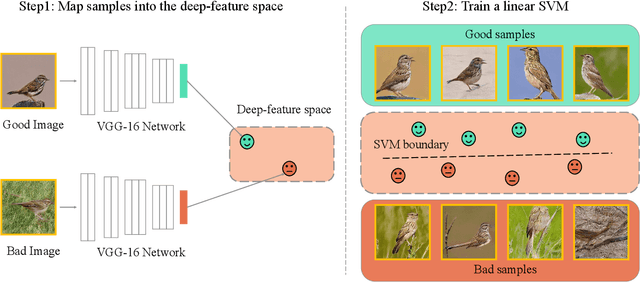


The task of text-to-image generation has achieved remarkable progress due to the advances in the conditional generative adversarial networks (GANs). However, existing conditional text-to-image GANs approaches mostly concentrate on improving both image quality and semantic relevance but ignore the explainability of the model which plays a vital role in real-world applications. In this paper, we present a variety of techniques to take a deep look into the latent space and semantic space of the conditional text-to-image GANs model. We introduce pairwise linear interpolation of latent codes and `linguistic' linear interpolation to study what the model has learned within the latent space and `linguistic' embeddings. Subsequently, we extend linear interpolation to triangular interpolation conditioned on three corners to further analyze the model. After that, we build a Good/Bad data set containing unsuccessfully and successfully synthetic samples and corresponding latent codes for the image-quality research. Based on this data set, we propose a framework for finding good latent codes by utilizing a linear SVM. Experimental results on the recent DiverGAN generator trained on two benchmark data sets qualitatively prove the effectiveness of our presented techniques, with a better than 94\% accuracy in predicting ${Good}$/${Bad}$ classes for latent vectors. The Good/Bad data set is publicly available at https://zenodo.org/record/5850224#.YeGMwP7MKUk.