 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverGAN: An Efficient and Effective Single-Stage Framework for Diverse Text-to-Image Generation
Paper and Code
Nov 17, 2021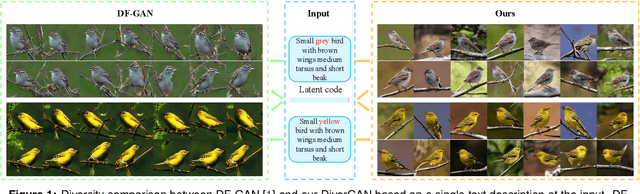
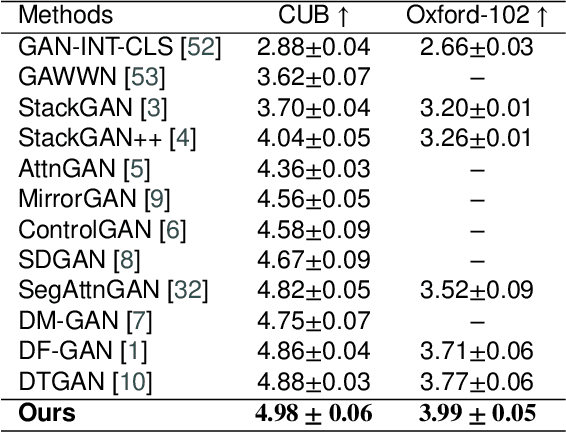
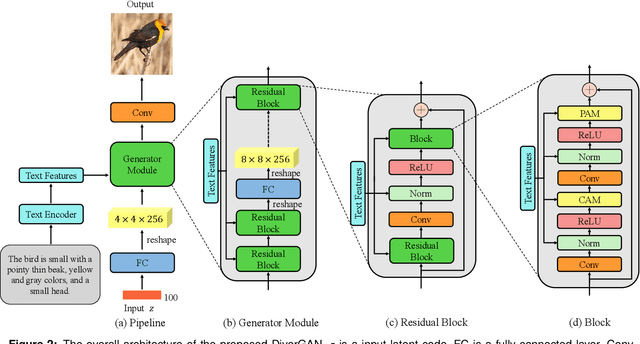
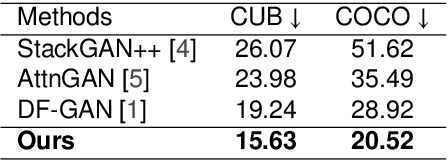
In this paper, we present an efficient and effective single-stage framework (DiverGAN) to generate diverse, plausible and semantically consistent images according to a natural-language description. DiverGAN adopts two novel word-level attention modules, i.e., a channel-attention module (CAM) and a pixel-attention module (PAM), which model the importance of each word in the given sentence while allowing the network to assign larger weights to the significant channels and pixels semantically aligning with the salient words. After that, Conditional Adaptive Instance-Layer Normalization (CAdaILN) is introduced to enable the linguistic cues from the sentence embedding to flexibly manipulate the amount of change in shape and texture, further improving visual-semantic representation and helping stabilize the training. Also, a dual-residual structure is developed to preserve more original visual features while allowing for deeper networks, resulting in faster convergence speed and more vivid details. Furthermore, we propose to plug a fully-connected layer into the pipeline to address the lack-of-diversity problem, since we observe that a dense layer will remarkably enhance the generative capability of the network, balancing the trade-off between a low-dimensional random latent code contributing to variants and modulation modules that use high-dimensional and textual contexts to strength feature maps. Inserting a linear layer after the second residual block achieves the best variety and quality. Both qualitative and quantitative results on benchmark data sets demonstrate the superiority of our DiverGAN for realizing diversity, without harming quality and semantic consistency.